
现如今,想通过预测(预后/诊断)模型发篇10分+其实挺不容易的,添加验证实验就不用多说了,这么高分数的文章验证实验都是必备的。除此之外,热点基因集的选择和联合分析思路也都非常重要。
今天带来的这篇文章仅通过3套公共数据集就拿下10分+
1、聚焦m7G修饰:这篇文章围绕m7G修饰在骨关节炎(OA)中的作用展开,m7G 修饰作为关键的RNA转录后修饰,在癌症、自身免疫病等疾病中具有重要作用,但在OA中的功能尚未明确,所以选择这个基因集进行分析创新性较高。
2、联合单细胞数据:这篇文章用到了3个数据集,其中两个是bulk转录组数据,一个是单细胞数据。其中,单细胞数据用于验证筛选的关键基因在软骨细胞亚型中表达情况。Bulk联合单细胞数据是目前经常用到的一种联合思路,上分效果很棒,想提升自己文章IF的朋友可以尝试这种联合思路哦,
3、干湿结合思路:馆长前面就提到过,这种级别的文章干湿结合是必备的,这篇文章进行了体内外实验的验证,不过用到的实验方法都很简单(基因敲除、qPCR、WB等),一般实验室都可以独立完成。
这篇文章的分析思路还是比较容易理解的,可复现性很强,而且能发10分+

题目:对bulk RNA和scRNA-seq数据的综合分析揭示了与骨关节炎中 m7G相关的潜在生物标志物和免疫浸润情况
数据集 |
平台 |
样本量 |
用途 |
GSE48556 |
GEO |
外周血(106例OA 患者 +33例健康人) |
训练集 |
GSE104782 |
GEO |
OA软骨细胞(10个OA软骨样本,1600个细胞) |
单细胞验证集 |
GSE114007 |
GEO |
软骨组织(20例OA + 18例正常) |
验证集 |
m7G 调控因子集 |
MSigDB |
59 个 m7G 相关调控因子 |
候选基因集 |
1)利用LASSO回归构建了基于关键m7G调控因子的OA风险模型。
2)采用无监督聚类分析方法检测106份OA样品中不同m7G修饰表型和m7G关键调控因子的m7G基因簇。
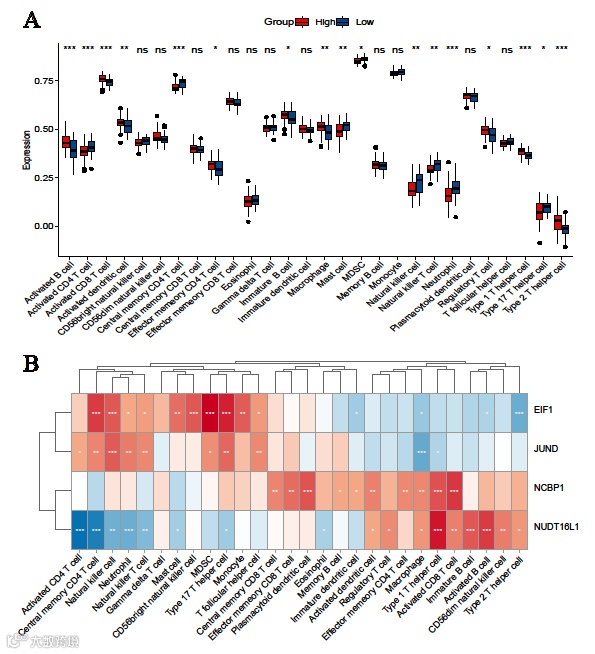
3)通过免疫浸润分析,评估了不同风险群体、m7G修饰表型和m7G基因簇之间的免疫微环境特征。
4)通过单细胞分析确定关键m7G调节因子与软骨退变之间的关系。
5)进行体外和体内实验验证。
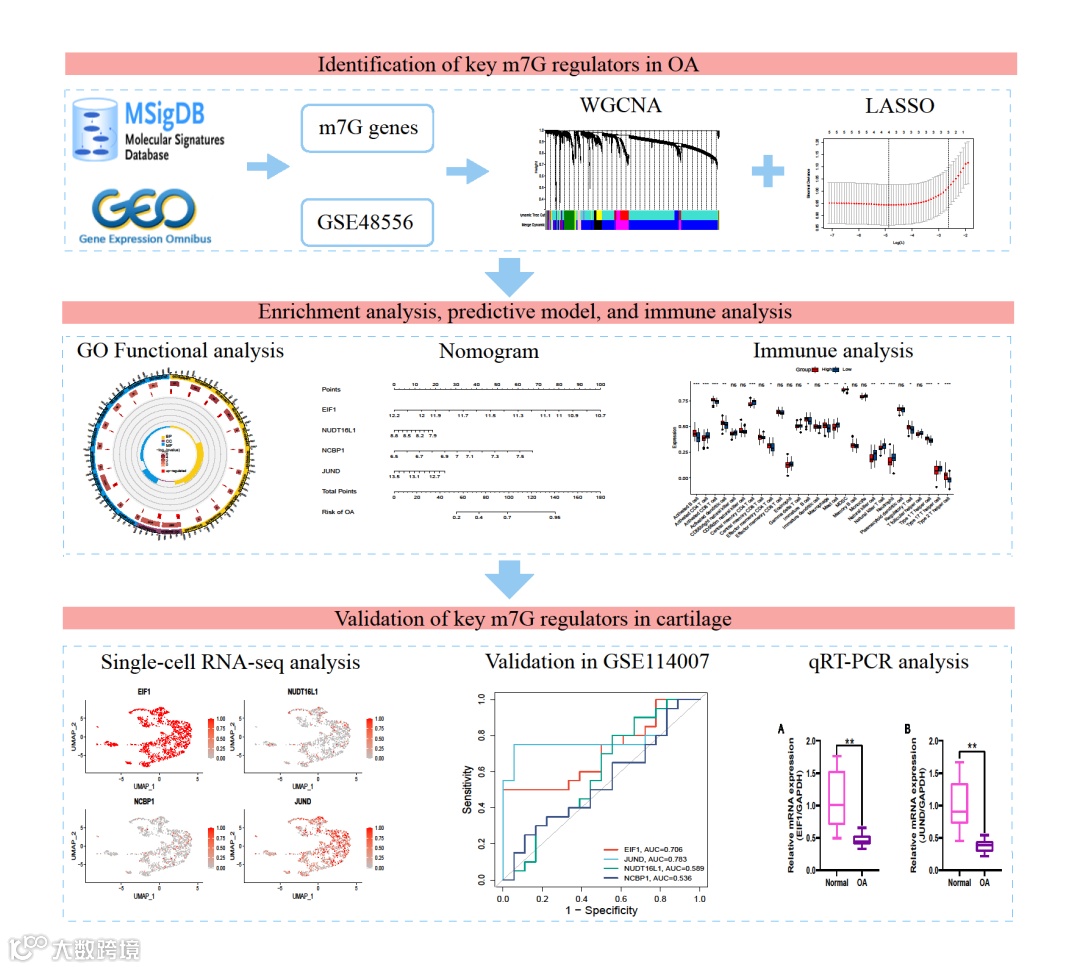
59 个 m7G 调节因子与 GSE48556 数据集中的DEGs进行交叉比对后,确定了 16 个具有显著差异的 m7G 调节因子。

利用GSE48556数据集中所有的DEGs构建基因共表达网络,筛选关键模块基因,将上述 16 个 m7G 调节因子与这些关键模块基因进行交集确定了5个枢纽m7G调节因子,通过LASSO分析进一步筛选出关键的m7G调节因子。最终确定了四个关键基因,即 EIF1、JUND、NCBP1和NUDT16L1。关键的m7G 调节因子主要集中在 RNA 运输、mRNA 监控以及 IL-17 信号通路中。

OA的列线图模型和风险模型的构建

m7G修饰相关风险组的免疫浸润特征
根据这四种关键的m7G 调节因子的表达水平,进行无监督聚类分析,从 GSE48556 数据集中检测OA患者中的 m7G 修饰表型,发现了两个不同的聚类。

使用 scRNA-seq数据集GSE104782来验证关键基因在软骨中的表达。EIF1 和 JUND 的表达在所有软骨细胞亚型中均较为普遍,而 NUDT16L1 和 NCBP1 的表达则较为有限。通过GSE1140007 验证发现EIF1 和 JUND 在诊断 OA 方面有良好性能。

EIF1 和 JUND 被确认为软骨退化过程中的关键调节因子。

这篇文章看上去图片不少,其实内容并不是很多,用到的分析方法和实验方法都是咱们比较熟悉的,馆长再为大家总结一下咱们可以借鉴的点:
1、预测模型类的文章,热点基因集的选择是最关键的,所以我们需要时刻关注新出的热点方向,第一时间拿来发文,效果最佳。
2、传统预测模型思路中加上其他热点方向,比如单细胞、孟德尔随机化、机器学习等,联合思路是大势所趋,也是提分的关键~
3、期刊选择也很重要,International Journal of Surgery本身就是一个生信非常友好的期刊,而且分数还这么高,馆长强烈建议大家收藏一下,以备不时之需。
随着医学研究的不断发展,临床研究在医学创新中的作用日益凸显,尤其是数据在临床决策和科研中的重要性日渐增加。既往,众多科室团队都存在着缺乏数据库建设的困境,同时也存在着数据库虽建立,但是缺乏科学标准,致使数据库难以更新完善,难以产出高水平文章。临床医生不仅是临床数据产生的源头,更应该成为管理数据的行家。临床研究数据库作为一种高效的数据管理工具,不仅能为科研提供数据支持,还能有效推动临床医疗的精准化和个性化治疗,更可以成为开展高水平RCT临床试验的有效推动力。
随着大语言模型技术(Deepseek, Chatgpt等)迅猛发展,越来越多的高水平临床研究被top杂志所发表,暗藏在病历资料中的数据规律被逐渐揭示出来。





可以看出,纯临床研究同样可以发表top刊!临床研究数据库是研究生学位论文设计、文章发表、项目申报、以及临床试验设计的最重要环节,良好的临床研究数据库不仅能够提供数据存储和管理功能,还能为患者数据的追踪、疾病预测和治疗方案的优化提供支持。在大语言模型技术迅猛发展的今天,数据库的数据清洗、标注和分析,都得到了极大推动。基于临床数据的深层研究也层出不穷。临床海量多模态数据作为疾病认识和诊疗的一手数据,在大语言模型技术的挖掘下,已逐渐成为国内外研究热点。
近来,在数据库挖掘领域,中国健康与养老追踪调查(China Health and Retirement Longitudinal Study, CHARLS),作为我国独立自主的数据库已被用于老年、康复、肿瘤、骨科、心理、护理、心脑血管、中风、代谢、肾病、呼吸、环境等领域的探索和研究,相关成果得到越来越多的top刊所接受,基于CHARLS的2025年部分代表作如下:





CHARLS数据库包括问卷信息、生物标志物和体格检查等数据,目前已收集了一套代表中国45岁及以上中老年人家庭和个人的高质量数据。CHARLS数据库具有2大特征:具有全国代表性,能够反映中国中老年人群的健康和养老现状;具有时间序列特征,适合研究长期变化趋势。可以看出,中国独立自主的公共数据已逐渐走向世界性的研究舞台,在各大CHARLS数据库的研究中,配以单中心/多中心的数据进行对比验证将显著增加研究的质量和可信度,进而可以被top期刊审稿人所认同。由此,本地数据库的设计和构建将更为重要。CHARLS数据库的学习是通往高水平临床研究的快速通道。
Pubmed可查总发文量2342篇,2024年619篇,2025年697篇

大型前瞻性随机对照研究对于绝大多数的临床医师有较难的入门瓶颈,而研究者发起的临床试验(Investigator initiated trial,IIT研究)可作为临床医师们的高水平临床试验的开端。IIT研究作为上市后临床研究的类型之一,指由研究者(主要指临床医师)申请发起的对已上市的药品、医疗器械或诊断试剂等开展的临床研究。如上市药物新适应证发现或者比较多种临床治疗手段的优劣,以及罕见病治疗等,与企业发起临床试验互为补充,更好地推进了药物研究的深度和广度,获得了更多的研究数据,为循证医学提供依据。
01
培训目标
1. 如何科学的进行临床数据库的设计、建立和维护;
2. 基于数据库,如何进行数据挖掘和研究设计;
3. 临床研究的套路和路数汇总,临床预测模型如何构建;
4. 本地数据库与公共数据库的联动验证和使用;
5. 公共CHARLS数据库:从认识到应用的深度讲解;
6. 临床数据库SCI文章的高效撰写模板解析和投稿选刊;
7. 大语言模型和临床数据库分析的实战介绍(着重案例);
8. 从回顾走向前瞻:研究者发起的临床研究(IIT研究)设计与实施。
02
参加对象
全国三甲医院、医学研究所及高校从事临床医学和生物医学研究的临床医生、副主任医师、主任医师,以及临床医学博士、硕士研究生;
03
主讲专家
北京大学、协和医学院、上海交通大学、中国科学院等高校,研究领域涵盖深度学习、计算机视觉、知识图谱、生物信息学等。近年来,老师们已发表科研论文80余篇,主持科学基金等科研项目10项,开发信息化软件30余项,并主编或参与编写多部学术著作。此外,参与多家三甲医院的临床研究合作,具有丰富的科研与授课经验。
04
课程大纲
课程主题
|
课程内容
|
【第一部分】
临床研究基础与数据库实例
|
一、临床研究介绍和概述
Ø 临床研究的套路和路数总结:万法源于总结与预测
Ø 临床数据的选择、类型与来源:熟稔数据特点
Ø 临床研究中的数据巧妙组合与应用:提炼与验证
Ø 数据标准化、统一化与质量控制:降低研究偏倚与误差
|
二、数据库基本概念与实例
Ø “玩儿转”单中心数据库:如何突出单中心数据优势?
Ø “利用好”多中心数据库:样本量、可信度与合作交流
Ø “联合好”公共数据库:可重复、大样本与透明度
|
|
【第二部分】
临床研究设计与数据库构建
|
一、临床研究设计与数据库需求
Ø 临床研究设计与数据需求分析:样本量如何估算?
Ø 临床数据标准化处理:本地数据如何接轨公共数据?
Ø 基于数据库的研究选题案例分析:高水平文献的设计解析
|
二、数据库构建流程与管理
Ø 数据库构建的关键步骤:可重复应用的数据库构建
Ø 数据库管理与数据更新:可“传代”的数据库设计
Ø 临床研究数据的处理与集成:真实世界临床数据的“舍”与“得”
|
|
【第三部分】
临床研究实践与数据库应用
|
一、临床研究数据库的实际应用
Ø 临床数据采集与质量控制
Ø 研究数据的获取与处理
Ø 临床数据的统计分析方法
|
二、数据库在多中心研究中的应用
Ø 多中心数据库的设计与管理
Ø 基于数据库的多中心研究与数据整合
Ø 多中心数据库的质量控制
|
|
三、临床数据库与AI应用
Ø AI在临床研究数据库中的应用
Ø AI辅助的临床研究设计与数据管理
Ø 临床与AI技术的跨学科协作模式
|
|
【第四部分】
CHARLS数据库介绍和应用
|
一、CHARLS数据库的准备工作
Ø 注册与登录
Ø 数据选择与申请
Ø 数据下载和本地保存
|
二、基于CHARLS标准化数据的全分析流程解析
Ø 听:分析过程全面讲解
Ø 看:分析实践逐步展示
Ø 做:标准化数据自行复现操作
|
|
三、CHARLS数据库文献案例剖析
Ø 文献剖析1:CHARLS数据库与心脑血管分析
Ø 文献剖析2:CHARLS数据库与老年研究分析
Ø 文献剖析3:CHARLS数据库与代谢病分析
Ø 文献剖析4:CHARLS数据库与抑郁分析
Ø 文献剖析5:CHARLS数据库与肌少症分析
|
|
【第五部分】
临床数据库类SCI论文撰写
|
一、基于大语言模型的高效SCI论文撰写
Ø 个性化指令展示(Deepseek & Chatgpt)
Ø 大语言模型的反向训练展示(Deepseek & Chatgpt)
Ø 回顾性分析SCI论文的撰写顺序高效优化(3天完成撰写)
|
二、临床数据库SCI论文模板展示
Ø 数据库SCI论文拆解与解析
Ø 模块化大语言模型撰写模板展示(Deepseek & Chatgpt)
Ø 如何防止AI幻觉产生
Ø 如何导入参考文献
|
|
三、Case Report撰写技巧
Ø 如何基于大语言模型进行Case信息的高效收集(Deepseek & Chatgpt)
Ø 如何进行完形填空式的Case Report撰写
Ø Case Report高效撰写流程介绍(1天完成撰写)
|
|
【第六部分】
研究者发起的临床研究(IIT研究)设计与实施
|
一、IIT研究的介绍
Ø 为什么说IIT研究是高质量临床研究的开端?
Ø 怎样利用好临床资源,进行较好的IIT研究的设计?
Ø 基于大语言模型的IIT研究伦理申请书高效撰写
|
二、IIT研究的实施
Ø IIT研究监管法规和相关政策介绍
Ø 如何通过IIT研究的实施发表高水平论文?
Ø IIT研究的国内外实施现状
|
|
【第十部分】
课程辅助措施
|
长期微信群答疑,为学员扫清技术难点障碍
Ø 技术咨询、合作,提供全方位服务
Ø 专业技术团队深入探讨
Ø 科研基金项目合作
|
