

在代谢组学(metabolomics)这一“功能最末端”的组学技术中,全面地捕捉生物样本中小分子代谢物变化,为理解生命过程、鉴别生物标志物、揭示生理/病理状态提供了强大工具。相比于靶向代谢组学——即预先设定目标化合物并定量分析——“非靶向代谢组学”(untargeted metabolomics)旨在尽可能广泛地、无预设地检测代谢物特征,探索未知变化。
然而,正因为其“无预设”与“宽覆盖”特性,数据读出、判读标准、质量控制也面临更多挑战。本文将从实验设计、数据预处理、判读标准、结果输出四个层面,深入探讨“非靶向代谢组学”数据的读取与判读应遵循的标准与实践。

“非靶向代谢组学”指的是在样本中进行尽可能广泛的小分子检测,而不是只锁定若干预先设定的化合物。其典型流程为:样本提取 → 分离(如液相色谱LC 或气相色谱GC)→ 质谱(MS)采集高分辨率数据 → 特征检测/峰提取 → 特征定性/注释或鉴定 → 统计分析与生物学解读。
与靶向代谢组学相比,非靶向方法优势在于:
宽覆盖,可检测数千至上万特征。
能够发现新的、未知的代谢物变化/指纹。
但也存在明显挑战:
定量精度低、标准品匮乏。
特征识别–鉴定困难。
数据量大、噪声多、批次效应强。
在非靶向代谢组学中,“读出”可理解为从原始仪器输出(色谱-质谱数据)到可供分析的特征矩阵(样本 × 特征)这一全过程。此过程的质量直接决定后续判读可靠性。
1. 实验设计与采样
良好的实验设计是数据可解释性的基础。包括:随机化样本进仪器顺序、批次内加入 QC 样本(例如合并池样、参比样)、设置空白、平行重复等。
研究指出组织化质量保证/质量控制(QA/QC)实践对非靶向 LC-MS 代谢组学至关重要。例如,Metabolomics Quality Assurance and Quality Control Consortium(mQACC)便在其2023研讨会上强调“系统适用测试(system suitability)、内部标准、批次设计、池样QC”四大关键领域。从读出角度,这意味着我们在读取数据之前就应设计好样本结构、仪器状态监控、参比样等。
2. 仪器与原始数据采集
非靶向代谢组学常用高分辨质谱(如 Orbitrap, Q-TOF)结合液相色谱(LC)或气相色谱(GC)技术。仪器设定、分离方案、采集模式(正负离子模式/数据依赖采集等)会影响特征覆盖及可鉴定度。例如,一项比较研究显示,在使用 UPLC-Orbitrap 非靶向方法时,采用正电喷(positive ESI)+ HILIC 色谱获得最多特征。在数据读出角度,我们应评估:色谱峰的分离度、质谱分辨率/质量精度、漂移校正、仪器稳定性等。
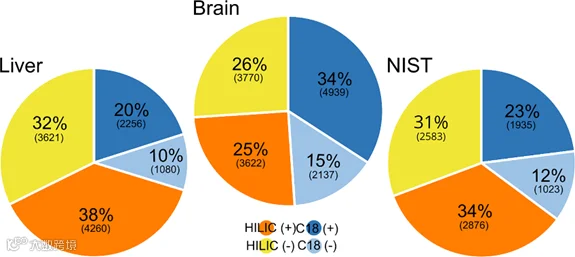
图2. 色谱和电离对同一样品经四种不同色谱和电离组合(C18(+)、C18(-)、HILIC(+) 和 HILIC(-))处理后获得的特征数量的影响。(Anton Ribbenstedt, et al. 2018)
3. 数据预处理
代谢组学数据预处理是将复杂的原始信号转化为可用于统计分析和生物学解释的高质量数据矩阵的关键环节。其核心目标是去除仪器噪声与非生物学变异、提高信号一致性并确保样本间数据的可比性。不同分析平台(如LC-MS、GC-MS、NMR)在数据结构和处理策略上存在差异,但总体目标一致。
3.1 MS-based数据预处理(LC-MS / GC-MS)
质谱平台产生三维数据结构(m/z、保留时间RT、信号强度),预处理流程如下:
1.去噪与基线校正:通过ALS或P-splines等算法削减背景信号,提高信噪比(S/N)。
2.峰检测(Peak Picking):识别局部极值并计算信噪比,将低于阈值的伪峰剔除。
3.峰对齐(Alignment):修正保留时间漂移,通常借助内部标准或QC样本实现。
4.峰匹配与合并:将跨样本检测到的相同化合物信号整合为统一特征。
5.矩阵生成:建立以样本为行、特征为列的定量矩阵(m/z-RT对 + 峰面积)。
对于GC-MS,信号通常更稳定,质谱碎片特征重复性高,可通过数据库比对实现快速自动化鉴定;而LC-MS数据峰形复杂,对齐与漂移校正尤为关键。
3.2 NMR-based数据预处理
NMR谱图以化学位移(ppm)为横轴,信号连续且易受pH、离子强度等因素影响,主要步骤包括:
1.基线校正:移除低频伪迹与实验漂移。
2.谱段分箱(Binning/Bucketing):将连续谱段划分为固定宽度的小区间,对每个区间信号积分以减少变量数并缓解微小位移影响。
3.峰对齐:利用快速傅里叶互相关、局部相关扭曲(Correlation Warping)或icoshift等算法,将同一代谢物信号在不同样本中对齐。
4.质量控制与矩阵构建:去除噪声区(如水峰区)并建立谱强度矩阵,为后续统计分析提供输入。
4. 鉴定/注释与可信度分层
这是非靶向代谢组学判读的核心难点:很多“特征”只具有 m/z 质量、保留时间、可能还有 MS/MS 片段,但未必有对应纯标准品。如何将这些特征注释为具体代谢物,并判断其可信度,是读出→判读的关键。国际上已有相关标准,如 Metabolomics Standards Initiative(MSI)提出的最低报告标准。
简单而言,可按以下层次判定:
Level 1:与纯标准品在实验室条件下匹配(保留时间 + 质谱 + MS/MS片段)——最高可信度。
Level 2:无标准品,但与数据库/文献中的保留时间 + MS/MS 片段/推测结构匹配。
Level 3:仅有准确质量(m/z) + 保留时间/出峰特征,结构不确定。
Level 4:通过同位素丰度分布、电荷状态和加合物离子测定完成鉴定,未知化合物。
在数据读出阶段就应标注每个特征的“鉴定级别”,以便后续结果解读慎重。如果鉴定标准不清晰、可信度不明,其跨实验室、跨平台可比性大为降低。
在完成数据读出后,科研者面临的是庞大的特征矩阵以及初步注释结果。如何判读、如何输出可靠结论,接下来我们一起逐一拆解。
数据质量评估
任何判读之前,都应先确认数据质量是否达标。建议检查以下指标:
QC 样本在批次内/跨批次的重现性(如相对标准差 RSD < 20 %)。
blank(空白)样本中假阳性/污染特征的比例。
仪器漂移情况:色谱峰保留时间漂移、信号强度漂移。
特征总数、缺失值比例、批次差异可视化(如 PCA/PCoA 看是否批次聚类而非生物组差异)。
特征筛选与统计分析
非靶向数据矩阵常包含数千至上万个特征,必须经由统计流程筛选出差异代谢物/显著特征。注意要点包括:
适当的数据预处理(如前文所述,包括正态化、对数转换、归一化、缺失值插补等)。
单变量统计(如 t-test、Wilcoxon、Fold Change)与多变量统计(如 PCA, PLS-DA, OPLS-DA)结合使用。但应警惕过拟合、伪差异。
多重假设校正(如 FDR、Bonferroni)以控制假阳性。
可视化结果(Volcano 图、热图、聚类图、得分图等)便于直觉理解。
将统计结果回归到生物学背景中,不宜只报告“特征1234在组A vs 组B上丰度上调2倍”。更应连接代谢通路、代谢网络。
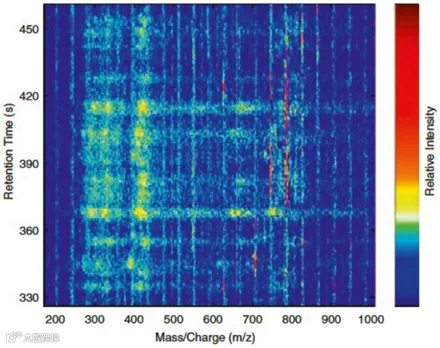
图3. 三维数据结构中的 LC-MS 图谱可视化。(Jun Sun, et al. 2024)
生物学判读与通路富集
差异特征筛选后,下一步是判读这些特征在生物系统中的意义。判读标准应包括:
注释的代谢物是否具有明确生物学意义(如参与已知代谢通路、酶调控网络)。
通路富集分析(如 KEGG、SMPDB)是否提供支持。例如,有研究通过非靶向尿液代谢组分析发现若干代谢物可用于预测 2 型糖尿病风险。
差异代谢物是否与预期生物学变化/机制一致,而不仅仅是统计学显著。
判读时注意“倾向”与“因果”的区分:非靶向研究通常是观察性,不能轻易下结论说“代谢物 X 导致 Y”,只能说“伴随”或“关联”。
结果应报告鉴定级别(如前文所述的1-4级),“低可信度代谢物”应谨慎解读。
报告与可重复性要求
耐药性癫痫患者血“白细胞层”(buffy coat)中的通路富集分析
背景:该研究以患有Drug‑Resistant Epilepsy(DRE,即抗药性癫痫)的中颞叶癫痫患者为研究对象,从血液样本的“白细胞层”(buffy coat)中开展非靶向代谢组学分析,并与公开的基因表达数据集(GEO数据集)整合以推进通路分析。
数据处理与通路富集流程
1.样本采集、处理及 LC–MS 数据采集:从 DRE 患者与对照组采集buffy coat,进行正/负离子模式 LC–MS 检测。
2.数据预处理:使用 XCMS 进行峰提取、对齐、保留时间校正,剔除检测频率 ≤ 50% 的特征。
3.差异代谢物筛选:结合 OPLS-DA 分析(VIP > 1)和 t-检验(p < 0.05)筛选出潜在生物标志物。最终识别 27 个潜在标志物。
4.通路注释:将筛选的代谢物映射至 KEGG 路径,使用超几何检验判定富集显著的代谢通路。
5.整合分析:将从 GEO 数据集中筛选出的差异表达基因与代谢组数据在MetaboAnalyst 中联合分析(Joint Pathway Analysis),依据代谢物、基因共同参与的通路确定高可信度通路。
从这个案例中对我们的判读流程建议:
在通路富集分析时,不仅看 p-value、富集数(被筛出代谢物数),还应看“参与代谢物/基因数量”、是否整合其它组学数据、是否有生物学机制支撑。
结果报告中应明确:通路名称、富集代谢物列表、方向(上调/下调)、可能的机制提示。
应提醒:即使通路富集显著,也需谨慎区分“关联”与“因果”,并提示后续验证(如靶向定量、细胞/动物模型实验)为佳。
在报告中标注注释水平/鉴定级别,例如哪些代谢物是标准品确认、哪些是推断。
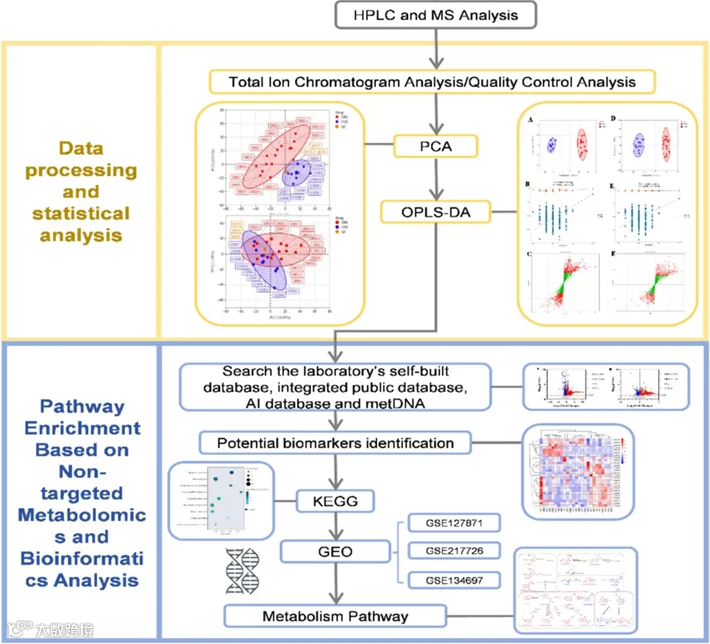
图4. 基于非靶向代谢组学和生物信息学分析,鉴定耐药性内侧颞叶癫痫患者囊泡中生物标志物和潜在通路流程图。(Zhu, Hailin, et al. 2025)

安必奇提供面向科研机构、医药与产业客户的一站式非靶向代谢组学服务,覆盖从方案设计到生物学解读的全流程,帮助客户把握数据质量、提高鉴定可信度并获得可落地的生物学结论。
项目咨询与实验设计:根据研究目标(生物标志物筛选、机制研究、药代学/毒理学、暴露组学等)定制采样方案、QC布置与批次设计,确保后续数据可比性与统计功效。
样本处理与多平台检测:提供多平台检测能力,包含高分辨质谱联用方案(LC-MS/MS、GC-MS)与核磁共振(1H-NMR)等,支持正/负电离模式、多极性色谱方法以扩大代谢物覆盖。
严格的QC体系:实验中贯穿系统适用性测试、内部标志物、池样QC与空白控制,按社区最佳实践(如 mQACC、MSI 指南)制定质控门槛与监控指标。
数据预处理与矩阵构建:执行去噪/基线校正、峰检测与积分、保留时间/谱图对齐、峰匹配、缺失值处理、批次漂移校正与归一化,交付结构化的样本×特征数据矩阵和QC报表。
代谢物注释与鉴定:提供分级注释(遵循 MSI 鉴定分级原则),对可疑/关键特征可开展纯标品比对或靶向验证以提升鉴定级别。
生物信息学分析与生物学解读:包括单变量/多变量统计、差异筛选、多重检验校正、代谢通路富集、代谢网络分析与可视化(PCA/PLS-DA/Volcano/热图、通路图等),并提供可操作的生物学结论与后续验证建议。
期待与您合作,将高质量的非靶向代谢组学数据转化为可验证、可解释的生物学洞见,助力研究与产品开发落地。
*注:安必奇提供的所有产品或服务均不得用于人类或动物之临床诊断或治疗,仅可用于工业或者科研等非医疗目的。
参考文献:
1. Souza, Amanda L., and Gary J. Patti. "A protocol for untargeted metabolomic analysis: from sample preparation to data processing." Mitochondrial Medicine: Volume 2: Assessing Mitochondria. New York, NY: Springer US, 2021. 357-382.
2. Mosley, Jonathan D., et al. "Metabolomics 2023 workshop report: moving toward consensus on best QA/QC practices in LC–MS-based untargeted metabolomics." Metabolomics 20.4 (2024): 73.
3. Ribbenstedt, Anton, Haizea Ziarrusta, and Jonathan P. Benskin. "Development, characterization and comparisons of targeted and non-targeted metabolomics methods." PloS one 13.11 (2018): e0207082.
4. Sun, Jun, and Yinglin Xia. "Pretreating and normalizing metabolomics data for statistical analysis." Genes & Diseases 11.3 (2024): 100979.
5. Sumner, Lloyd W., et al. "Proposed minimum reporting standards for chemical analysis: chemical analysis working group (CAWG) metabolomics standards initiative (MSI)." Metabolomics 3.3 (2007): 211-221.
6. Salihovic, Samira, et al. "Non-targeted urine metabolomics and associations with prevalent and incident type 2 diabetes." Scientific Reports 10.1 (2020): 16474.
7. Zhu, Hailin, et al. "Identification and enrichment of potential pathways in the buffy coat of patients with DRE using non-targeted metabolomics integrated with GEO Datasets." European Journal of Medical Research 30.1 (2025): 1-12.
版权说明:本文来自北京安必奇,感谢关注、转发。欢迎媒体/机构转载,转载请注明来自“北京安必奇生物”。

