
👆点击“博文视点Broadview”,获取更多书讯


云原生数据仓库利用启发式规则或者机器学习技术来诊断数据仓库在数据建模、数据准备、库表结构设计和数据查询分析等各个环节中存在的可优化点并给出优化建议,并通过自动化处理、分析和可视化展示,提供更自动化和更智能的数据管理和分析解决方案。除了智能化优化数据仓库性能,还会考虑用户的财务成本及不同资源每时每刻的不同价格,因此可以智能化地选择资源以降低用户成本,并加强数据安全和隐私保护。
由于数据查询分析的规模越来越大、复杂度越来越高,库表结构设计的优化对降低数据仓库的存储成本和查询性能有巨大影响。云原生数据仓库可以利用具备深度思考能力的大语言模型(如DeepSeek-R1)可通过多环节优化数据仓库建设流程。在数据建模阶段,其强大的逻辑推理能力可自动解析业务需求,结合历史数据特征,帮助设计人员快速构建符合业务逻辑的数据模型。库表结构设计方面,模型基于深度计算能力,能分析数据分布特征并推荐最优范式等级,自动生成兼顾查询性能与存储效率的DDL语句,同时提供索引策略建议。
在数据查询分析环节,用户可通过自然语言描述需求,模型即时生成优化后的SQL语句,并结合查询计划分析提出性能调优方案,其代码生成准确率较传统方法提升显著。通过强化学习自主进化的特性,模型还能持续吸收数据治理经验,形成闭环优化机制,为数据仓库全生命周期提供智能支持。
如图1所示,云原生数据仓库为了诊断用户的SQL 查询分析代码的性能问题,会记录用户执行的每个查询语句的具体情况,如每个查询语句的执行时间、各个阶段和各个算子所消耗的内存、网络和磁盘资源,以及耗时程度和并发度等。

图1 数据仓库的信息化与智能化
传统的联机分析处理软件是企业自己部署运行的,企业需要维护自己的物理硬件,并在上面安装软件,为了应对突发的高峰时刻,通常要准备较大规模的集群来提供高可用机制。因此,这种企业自己部署数据仓库的方式维护成本高、资源利用率低,难以做到弹性伸缩。弹性与Serverless 是云服务厂商为了解决企业的上述痛点而推出的一种按需付费的云服务,现在大多数的数据仓库通过部署在云上以提供弹性与Serverless 功能。
数据在企业中的使用,具有明显的周期性和不确定性。一方面,业务发展变化很快,其数据规模体量也变化很大;另一方面,有些业务具备很强的时间周期特点,平时空闲,高峰明显。这些特点对底层基础设施提出了极高的资源弹性要求。这里所说的弹性,既包括存储能力的弹性,也包括计算能力的弹性。如图2所示,用户可以根据自身的需求,灵活选择资源配置方式,并根据发展需要,随时变更资源配置,使投入资源收益最大化。
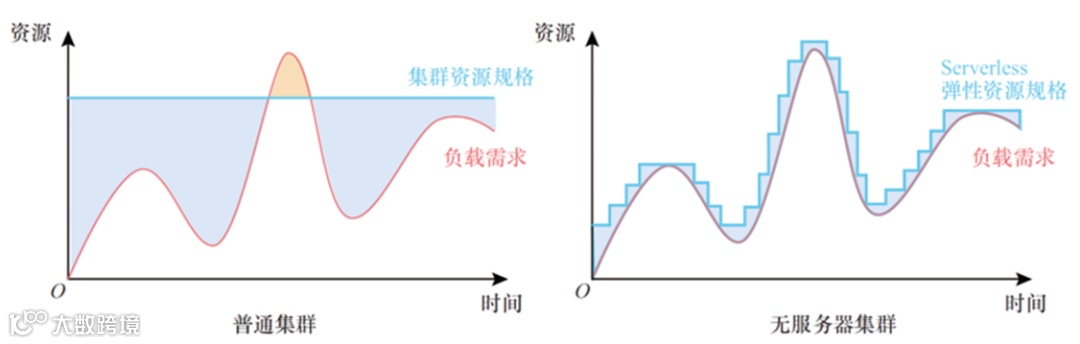
图2 弹性与Serverless
以千亿参数大模型训练为例,数据供给层对云原生架构提出了多方面核心需求,例如:算力集群需要支持千卡级动态扩展能力,满足百亿至千亿参数模型训练时线性增长的并行计算需求,这要求云平台具备细粒度资源调度和弹性伸缩能力。数据预处理流水线需实现自动化编排,集成数据质量检查、多源异构数据融合等功能,以应对日均PB级数据吞吐量,这需要云原生架构提供高吞吐分布式存储与计算资源池化能力。
三、架构突围:AnalyticDB的国产化创新实践
云原生数据仓库AnalyticDB MySQL 版是阿里巴巴自主研发、经过超大规模及核心业务验证的PB 级实时数据仓库。
1. 总体架构
AnalyticDB MySQL 版采用云原生架构,计算存储分离、冷热数据分离,支持高吞吐实时写入和数据库强一致性,兼顾高性能在线分析和低成本离线处理的混合负载,满足“采存算管用”的数据全链路,其架构如图3所示。

图3 AnalyticDB MySQL 总体架构
(1)访问层。访问层由Multi-Master 可线性扩展的协调节点构成,主要负责协议层接入、SQL 解析和优化、实时写入Sharding、数据调度和查询调度。
(2)计算层。自研羲和计算引擎具备分布式MPP 和BSP 融合执行能力。借助云原生基础设施,计算节点实现了弹性调度,可根据业务需求做到分钟级甚至秒级扩展,实现资源的有效利用。
(3)存储层。自研玄武存储引擎是基于Raft 协议实现的分布式、实时、强一致性、高可用引擎,通过数据分片和Multi-Raft实现并行,利用分层存储实现冷热分离来降低成本。
(4) 数据源。AnalyticDB MySQL 在深化湖仓能力的同时, 推出了APS(AnalyticDB Pipeline Service)数据管道组件,为用户提供实时的数据流服务,支持数据库、日志、大数据等低成本、低延迟入湖入仓,单链路吞吐量可达到4 GB/s。
2. 优化器内核架构
在数据库中优化器是不可或缺的组件,所有的关系数据库都自带优化器组件。无论在学术界还是工业界,优化器可以分为两大类:基于规则的优化器(Rule-Based Optimizer)和基于成本的优化器(Cost-Based Optimizer)。
基于规则的优化器和基于成本的优化器是数据库查询优化的两种不同策略。虽然基于规则的优化器在早期的数据库系统中具有一定的应用,但在现代数据库系统中,基于成本的优化器通常更为有效。通过考虑实际数据统计信息和代价模型,基于成本的优化器能够更加智能地生成高效的查询执行计划,提供更好的性能。
AnalyticDB 优化器的内核分为RBO 和CBO 模块, 分别对应分层搜索和统一搜索的模式。区别于其他一些数据库简单采用Cascades 框架,AnalyticDB 将分层搜索和统一搜索结合起来,这样可避免将所有规则放入Cascades框架中融合搜索,缩短编译时间。同时,保证对性能影响起到关键作用的规则都能发挥作用。

图4 AnalyticDB 优化器内核架构
3. 采用行列混合存储策略
数据仓库的目的是将决策支持型数据处理与事务型数据处理分离,以减少对业务系统的影响。随着用户产生的数据量不断增加,出现了越来越多的业务场景,需要能够同时处理高并发的事务请求,并确保数据分析具有时效性。因此,行列混合存储技术应运而生,这里以 AnalyticDB 为例来介绍其中的行列混存技术。
为了处理同时包含了单点查询与范围扫描的混合负载,通常会选择使用行列混合存储的方式,这种方式可以使数据文件同时高效地支持这两种类型的查询。在此基础上,AnalyticDB 的存储层设计了 Lambda 架构,将数据划分为基线数据和增量数据两部分,其中基线数据包含索引和数据两部分,而增量数据不包含索引。随着实时数据的不断写入,为了避免增量数据影响查询性能,AnalyticDB 会使用后台任务将基线数据和增量数据合并成一个新的基线数据,并基于新的基线数据构建全量索引。频繁更新的特征列按行存储保障写入效率,低频访问的元数据按列压缩节省空间。

图5 AnalyticDB 行列混合存储模型
四、未来图景:数据仓库的AGI演进之路
1.流批一体处理引擎与多级一致性保障
湖仓一体方案引入了实时数据处理和分析的功能。它利用流处理技术,对实时数据进行处理和转换,将结果写回数据湖中。这使用户可以基于最新的数据进行实时的查询、分析和决策,提高了数据仓库数据的实时性。
基于湖仓一体方案的云原生数据仓库,可以同时在多套引擎中写入同一份数据,将各种类型和来源的数据以原始格式存储在数据湖中。这种原始数据存储方式避免了传统数据仓库中的多级数据转换和规范化过程,从根本上解决了多级数据一致性问题。
异构计算资源池统一调度CPU、GPU及FPGA设备,满足多样化算力需求。
2.一体化数据处理
近年来,随着人工智能的飞速发展,用户的需求不断演化,需要在原有基础上增加基于AI 的接口,进一步使数据仓库的接口复杂化。面对这一现状,云原生数据仓库应该整合多种数据处理方式,包括批处理、交互式查询和人工智能等,从而提供一体化的数据处理能力。开发人员能够在统一的环境中进行数据处理和分析,无须频繁切换工具或学习不同的编程语言。
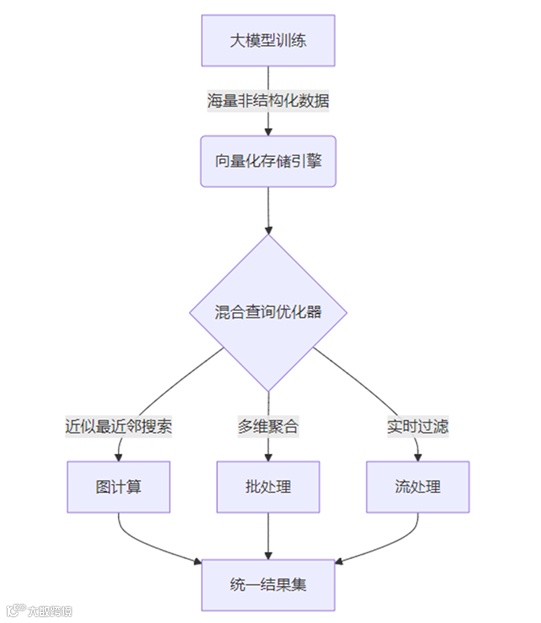
图6 一体化数据处理
五、大模型时代的技术挑战
1.万亿级参数的梯度更新对数据流水线提出新要求
数据库在结构化数据领域中表现优异,但对于一些非结构化数据表现欠佳。虽然业界出现了一些用于支持非结构化数据查询和处理的NoSQL 数据库,但在一些特定领域始终无法达到令人满意的效果。例如,在GitHub 中管理了大量开源项目,如何在短时间内搜索出符合条件的项目及代码文件;在类似百度、谷歌等搜索引擎中,如何快速搜索到用户需要的内容;在淘宝、饿了么等App 中如何快速搜索,找到指定商品;等等。对于这类偏向搜索的应用,很难用数据库达到快速检索的目的。利用实时检索,有望解决上述场景中快速检索的问题。
2.大模型时代的多模态数据治理面临三大核心矛盾
●数据多样性矛盾:多模态数据涵盖文本、图像、音频等多种类型,传统系统难以实现统一的元数据管理与质量评估标准,需同时解决异构数据融合与标准化问题;
●规模与效率矛盾:海量非结构化数据处理需求与实时分析响应要求形成冲突,需平衡存储成本与计算性能;
●生态兼容矛盾:跨系统数据集成面临协议差异与接口碎片化挑战,要求平台具备开放的生态适配能力。
3.AnalyticDB数据仓库通过以下方式满足需求
●构建混合负载架构,支持结构化与非结构化数据的统一存储及实时分析,通过分布式计算引擎实现PB级数据秒级响应;
●集成异构资源的智能资源调度算法,根据负载动态分配计算与存储资源,降低运维复杂度;
●提供标准化数据接口与跨平台连接器,兼容主流数据源和应用生态,支撑一站式的多模态数据端到端治理
满足大模型的多模态预训练需求。
六、结语
正如中国工程院院士郑玮民教授所言:“在数据成为新石油的时代,云原生数据仓库是打开智能世界的金钥匙。'"
当DeepSeek等大模型推动AI进入新纪元,云原生数据仓库正以弹性计算重塑数据供给链,以智能优化释放数据潜能,成为企业智能化转型的核心基座。
以上内容摘自《云原生数据仓库:原理与实践》
↑限时五折优惠,快快抢购吧↑

限时五折优惠,快快抢购吧!
发布:王功瑾
审核:陈歆懿
如果喜欢本文
欢迎 在看丨留言丨分享至朋友圈 三连
< PAST · 往期回顾 >
书单 | 5本数据分析神作!
书单 | 6本巨好看的科技史!


