
你好,我是Alan, 上一篇文章我介绍了UML类图, 今天这篇文章主要分享一下关于DDD中的API设计。
在什么是领域驱动设计这篇文章中我提到, 领域驱动设计的核心是建立起与业务强相关的模型, 来帮助我们更好的应对软件中的不确定性, 而API作为软件对外的接口, 是否可以和领域模型一样稳定呢? 那么由领域模型获得API就变得理所应当了。
如何根据领域模型获得高质量的API呢? 这就要回到模型本身上去, 在事件风暴这篇文章中, 我提到业务方总是习惯从交互的角度去理解问题, 而模型更偏向于数据, 上面说API是与模型关联的, 那么自然API也从数据角度出发, 而RESTful API就是一个不错的选择。
首先我们需要弄清楚, 如何将模型与RESTful API相关联? 一共有四个步骤:
使用URL来表示领域模型
根据URL设计API
使用分布式超媒体设计API中涉及到的资源
使用得到的API去覆盖业务流程
第一步是通过URL来表示领域模型, 比如现在我们现在有这样一段URL, fnmain.cn/users/alan/subscription/, 那这段url背后的模型是什么呢?

这段URL其实对模型的细化, user-id是user的实例, subscription-id是subscription的实例。
下面我们通过一个更加复杂的模型来设计我们的API接口, 下面是对应的模型。

分别从两个聚合根上看, 分别是user和author。
首先是以user为聚合根的URL。
/users/ user聚合根, 表示所有用户
/users/{user_id} user实例化, 表示通过user_id标识某个用户
/users/{user_id}/subscriptions, User-subscriptions聚合, 表示某个用户的全部订阅。
/users/{user_id}/subscriptions, User-subscription聚合, 表示某个用户的全部订阅。
/users/{user_id}/subscriptions/{subscription_id},User-Subscription的实例化, 表示通过user_id和subscription_id标定某个订阅。
其次是以author为聚合根的URL
/authors/ author聚合根, 表示所有作者
/authors/{author_id} author的实例化, 表示某个具体的作者
/authors/{author_id}/columns/{column_id}, 作者撰写专栏的实例化, 表示每个特定的专栏。
/authors/{author_id}/columns/{column_id}/contents/表示某个专栏的全部内容。
/authors/{author_id}/columns/{column_id}/contents/{content_id}表示某个专栏内容的实例化, 表示某个特定的课程。
根据URL来设计API, 我们可以设计一个表格, 第一行的内容是角色, HTTP方法, URL, 业务场景。
角色 |
HTTP方法 |
URL |
业务场景 |
| {user_id} |
GET |
/users/{user_id}/ subsciptions |
查看订阅文章详情 |
| {user_id} |
POST |
/users/{user_id}/ subscriptions |
订阅文章 |
| {user_id} |
PUT |
/users/{user_id}/ subscriptions |
将文章赠送它人 |
| {user_id} |
DELETE |
/users/{user_id}/ subscriptions |
管理员退订 |
到这里我们只是得到一组API候选, 接下来就需要使用分布式超媒体设计API中所涉及的资源, 用来完善API的设计, 以及使用得到的API去覆盖业务流程, 验证API的有效性。
首先我们需要知道什么样的格式属于超媒体, 其实很简单, 包含超链接的格式都可以看成是超媒体, 因此HTML是超媒体格式, 它的构成要素主要有两个分别是:
指向关联资源的链接(href)
与主资源是哪种关联关系(rel)
而我们常用的JSON和XML并没有提供默认的链接方式, 所以它们并不是超媒体, 我们在设计RESTful API的时候, 要使用HAL, 而不是原味的JSON或者XML。
XML的HAL基本上就是把HTML的link作为标准标签引入了XML, 而JSON的HAL则定义了_links结构来表示链接。
下面我放了一段xml中的HAL
Content-Type: application/hal+xml
<resource rel="self" href="/orders/523">
<link rel="warehouse" href="/warehouse/56"/>
<link rel="invoice" href="/invoices/873"/>
<currency>USD</currency>
<status>shipped</status>
<total>10.20</total>
</resource>
然后下面这段是JSON的
Content-Type: application/hal+json
{
"_links": {
"self": { "href": "/orders/523" },
"warehouse": { "href": "/warehouse/56" },
"invoice": { "href": "/invoices/873" }
},
"currency": "USD",
"status": "shipped",
"total": 10.20
}
说完了格式问题, 我们来看看如何使用超媒体设计API中的资源, 如何通过超链接构成渐进式服务消费。
首先我们看一下聚合根的超媒体描述, 对于一个User实例而言, 我们可以使用如下的HAL JSON去描述。
{
"_links": {
"self": {"href": "/user/19"},
"subscriptions": {"href": "/user/19/subscriptions"}
},
"username": "alan"
}
这段HAL JSON中包含两个超链接: self和subscriptions,self表示获取当前资源的URL, 我们会将这个URL称作主URL。这个URL从概念上讲和ID是等价的, 也就是可以用于唯一定位当前资源的标识符, 同时self也是用于缓存的URL。
subscriptions表示聚合关系User-subscriptions, 也就是指示了如何寻找被当前User聚合的Subscription, 对于聚合根而言, 需要为所有的聚合对象提供链接, 用来指示如何获取这些聚合对象。
你可能会问, self URL有什么用, 如果单独对一个User实例而言
{
"_links": {
"self": "/users"
},
"_embedded": {
"users": [
{
"_links": {
"self": "/users/18"
},
"username": "Alan"
},
{
"_links": {
"self": "/users/19"
},
"username": "join"
},
]
},
"total": 4525
}
我们通过_embedded表示所有的用户, 但是有一个地方需要我们注意的是,如果User对象有很多属性, 那么我们需要在/users的HAL JSON中包含这些属性吗?
这个时候就该列表中每一个User对象中包含的self URL发挥作用了, 我们可以把集合资源和其中的独立资源, 看成是渐进式的两种服务。
也就是说, 我们可以把集合资源中包含的数据, 看作是更基础的服务, 像常用数据这样, 可以满足大部分客户端在通常情况下对用户数据的需求, 而其中每一个user对象中包含的self URL所指示的服务, 我们可以看成是增强服务, 也就是全量服务。
于是, 如果某个客户端需要不包含常用数据中的信息, 那么它可以通过self URL去获取全量数据, 也就是说, 我们将常用数据和全量数据设计成为渐进式消费的两种不同的服务, 并通过分布式超媒体格式, 描述它们之间的关联。
构造资源的时候, 将缓存当作必须考虑的特性, 详细进行设计。
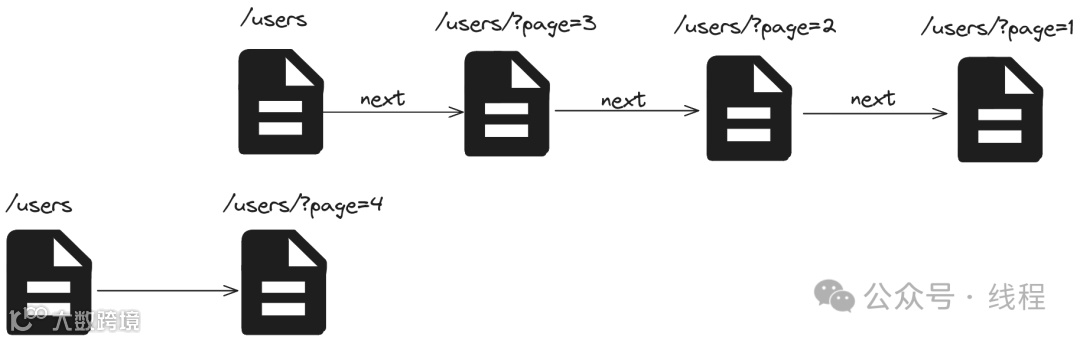
当然我们还需要进行分页处理, 比如前面/users一共有43215个用户, 如果将所有的用户都包含进来, 就会产生极大的HAL JSON文件, 因此我们需要分页处理, 于是就变成了下面这种。
"_links": {
"self": "/users",
"next": "/users?page=3"
}
我们可以通过next链接表示后面这一页, 那么如何通过缓存, 使得当有新用户注册的时候, 大部分的缓存都不失效呢?
一个比较有效的策略是, 永久不缓存/users页面, 也就是/users永远表示新注册的用户, 如果分页达到上限的时候, 就生成新的页面id, 并进行缓存, 然后继续使用/users去等待新注册的用户。
在我们将API中涉及的资源都使用分布式超媒体描述之后, 我们就获得了完整的API定义, 最后一步就是将API重新映射回所需要支撑的业务流程或用户使用场景中, 与业务方一起验证这些API是否能够满足所有的需求。
好了, 到这里这篇文章就结束了, 这篇文章主要介绍了如何在DDD中构造出合适的API。