

作者 | 玖宇(SGLang 社区 & 阿里云),杨彦波(SGLang 社区 & 科大讯飞),孙伟祥(SGLang 社区 & 小红书),宋阳 (SGLang 社区 & 小红书),雨杨 (Mooncake & 阿里云)
大语言模型(LLM)推理服务正成为企业级应用的核心基础设施,其生产落地的关键在于性能、稳定性与成本的平衡。当前,LLM 推理架构正从单体向分布式演进,主流路径包括 Prefill-Decode(PD)分离、Attention-FFN(AF)分离及 KVCache 外置。其中,KVCache 显存占用在长上下文或高并发场景下常超 70%,仅依赖 GPU HBM 和 CPU DRAM 已难满足需求。
Mooncake 作为业界主流的分布式 KVCache 存储引擎,通过专用缓存集群为 SGLang 等推理框架提供高吞吐、低延迟服务。然而,在生产环境中管理 Mooncake 仍面临两大挑战:一是部署运维复杂,Prefill/Decode 与缓存节点需深度协同,传统 Kubernetes Workload 难以表达多角色强耦合语义;二是滚动升级易导致缓存丢失,引发 P99 延迟毛刺与吞吐断崖。
为此,RoleBasedGroup(RBG)应运而生。作为面向 AI 推理的 Kubernetes 原生 API,RBG 将 Mooncake 缓存与 SGLang 推理节点视为同一服务的不同角色,统一编排部署、升级与弹性伸缩。借助原地升级与拓扑感知能力,RBG 可最大限度避免缓存丢失,保障计算与缓存策略一致性,实现高性能与高稳定性的兼顾。
Mooncake:面向大模型推理的分布式 KVCache 存储引擎
Mooncake 是 SGLang HiCache 的高性能分布式 L3 存储后端,基于 RDMA 实现跨机 KVCache 共享,突破单机缓存容量瓶颈。

核心组件
- Master Service:管理集群存储池、元数据与节点生命周期
- Store Service:提供分布式缓存存储,支持多副本、条带化传输与热点负载均衡
核心特性
- RDMA 加速 + 零拷贝机制,实现高带宽、低延迟访问
- 智能预取与 GPU 直传,最大化 I/O 效率
- 支持 PD 分离架构,提升大规模集群 Token 吞吐量
快速预览
# 启动 Master
mooncake_master --http_metadata_server_port=9080
# 启动 Store 服务(配置 RDMA 设备与内存池)
python -m mooncake.mooncake_store_service --config=config.json
# 启动 SGLang(启用 Mooncake 后端)
python -m sglang.launch_server \
--enable-hierarchical-cache \
--hicache-storage-backend mooncake \
--model-path <model_path>RoleBasedGroup (RBG):面向大模型推理的弹性角色编排引擎
核心问题:大模型推理生产落地的五大挑战
- 快速架构迭代:分离式架构(如 PD 解耦、多级路由)演进迅速,传统平台难以适配。
- 性能敏感:TTFT、TPOT 对 GPU 拓扑(NVLink/PCIe)、RDMA 亲和性高度敏感,调度不当将显著增加延迟。
- 组件强依赖:Prefill 与 Decode 存在 1:1 或 N:1 绑定关系,版本升级需原子性同步,否则易引发请求失败。
- 运维效率低:缺乏多角色统一视角,日均约 5% 时间消耗于手动协调,造成资源浪费。
- 资源潮汐显著与利用率不足:线上流量峰谷差超 10 倍,静态配置下 GPU 平均利用率长期低于 30%。
根本矛盾:传统微服务面向无状态、弱拓扑场景,而大模型推理是强状态、拓扑感知、极致性能的有状态应用。
RBG 设计理念:角色即一等公民,角色协同即核心场景
RBG 源自 SGLang 社区,由小红书、算秩未来、科大讯飞、阿里云和南京大学联合贡献。其核心目标是以“角色(Role)”为调度编排原子单元,构建契合 LLM 推理特性的管理范式。
RBG 将一次推理服务视为拓扑化、有状态、可协同的“角色有机体”,提出 SCOPE 核心能力框架:
- S – Stable:面向拓扑感知的确定性运维
- C – Coordination:跨角色协同策略引擎
- O – Orchestration:有编排语义的角色与服务发现
- P – Performance:拓扑感知的高性能调度
- E – Extensible:面向未来的声明式抽象
SCOPE 核心能力解析
Stable(稳定):面向拓扑感知的确定性运维
通过为每个 Pod 注入全局唯一 RoleID,并遵循“最小替换域”原则,确保运维操作在原有 GPU-NVLink 域、NUMA 节点等硬件拓扑范围内完成,避免因拓扑漂移导致性能抖动。
roles:
- name: prefill
replicas: 3
rolloutStrategy:
rollingUpdate:
type: InplaceIfPossible
maxUnavailable: 1Coordination(协同):跨角色协同策略引擎
RBG 内置声明式协同机制,精确定义角色间依赖关系:
- 部署协同:如 Prefill 与 Decode 成对调度、成组就绪;
- 升级协同:支持“比例协议”式升级,确保多角色版本一致性;
- 故障协同:预定义联动策略,触发自动补救或迁移;
- 伸缩协同:按角色配比成组调整实例,保持吞吐与延迟稳定。
该能力将复杂分布式服务作为统一生命周期整体管理,大幅降低运维复杂度。
# 示例:PD 分离架构中 Prefill 和 Decode 角色协作升级
coordination:
- name: prefill-decode-co-update
type: RollingUpdate
roles:
- prefill
- decode
strategy:
maxUnavailable: 5%
maxSkew: 1% # 升级过程中新版本比例最大偏差
partition: 20%
roles:
- name: prefill
replicas: 200
template: ...
- name: decode
replicas: 100
template: ...Orchestration(编排):编排化的角色与服务发现
RBG 显式定义角色依赖与启动顺序,提供拓扑自感知的内建服务发现,将各角色 IP、属性、关系等信息注入环境变量或配置文件。推理引擎(如 SGLang、vLLM)可直接读取本地配置获取拓扑视图,无需依赖 etcd、Consul 等外部系统,显著降低集成复杂度。
Performance(性能):拓扑感知的高性能调度
引入拓扑感知装箱策略,支持多维度优化:
- GPU 拓扑优先级(GPU-NVLink > PCIe > RDMA > VPC);
- 角色间亲和与反亲和约束;
- 同角色实例布局均衡;
- 短路读优化。
上述策略保障 TTFT、TPOT 等关键指标在大规模部署中保持最优。
Extensible(可扩展):面向变化的部署抽象
通过声明式 API(RBG、RBGs、EngineRuntimeProfile 等)与插件机制,将“角色关系定义”与“部署/模型管理/弹性策略”解耦。当社区推出新架构时,无需修改 RBG 核心代码,仅需通过 YAML 定义新角色模板即可快速落地,显著缩短新架构投产周期。
# 示例:PD 分离架构角色定义
roles:
- name: prefill
replicas: 2
engineRuntimes:
- profileName: custom-engine-runtime
template: ...
- name: decode
replicas: 1
engineRuntimes:
- profileName: custom-engine-runtime
template: ...RBG 通过 Kubernetes 原生 API 为大模型推理服务提供稳定、协同、可编排、高性能、可演进的统一承载层,是现代 LLM 推理工作负载的新型部署与运维抽象。
基于 RBG 部署 PD 分离架构 + Mooncake 推理服务
部署架构

通过 RBG 可部署高可用、弹性的 SGLang PD 分离推理系统,核心角色包括:
- SGLang Router:统一请求入口,根据负载、上下文长度等智能调度至 Prefill 或 Decode 节点。
- Prefill Serving Backend:处理提示词前向计算,生成初始 KVCache,计算密集型,显存带宽敏感。
- Decode Serving Backend:执行 token 自回归生成,依赖 KVCache,对缓存访问延迟极为敏感。
- Mooncake Master/Store:独立 KVCache 外置存储角色,提供高吞吐、低延迟分布式缓存服务,突破单机容量限制,支持跨请求复用与细粒度淘汰策略(如 LRU + 高水位驱逐)。
上述角色通过 RBG 的多角色协同能力紧密集成。EngineRuntime 作为 Sidecar 注入引擎 Pod,实现服务注册、动态 LoRA 加载、流量控制与可观测性集成。
通过 RBG 部署 Mooncake + SGLang PD 分离推理服务
- 安装 RBG:https://github.com/sgl-project/rbg/blob/main/doc/install.md
- 镜像准备参考附录 8.1
准备好镜像后,使用以下 YAML 部署支持 KVCache 卸载的 SGLang PD 分离推理服务:
https://github.com/sgl-project/rbg/blob/main/examples/mooncake/pd-disaggregated-with-mooncake.yaml
环境变量说明详见:https://github.com/kvcache-ai/Mooncake/blob/main/doc/zh/mooncake-store.md
查看部署结果
kubectl get pods -l rolebasedgroup.workloads.x-k8s.io/name=sglang-pd-with-mooncake-demo
sglang-pd-with-mooncake-demo-router-0 1/1 Running 0 71s
sglang-pd-with-mooncake-demo-prefill-0 1/1 Running 0 3m42s
sglang-pd-with-mooncake-demo-decode-0 1/1 Running 0 3m42s
sglang-pd-with-mooncake-demo-mooncake-master-0 1/1 Running 0 4m2s
sglang-pd-with-mooncake-demo-mooncake-store-bh9xs 1/1 Running 0 3m42s
sglang-pd-with-mooncake-demo-mooncake-store-dsrv4 1/1 Running 0 3m42s
sglang-pd-with-mooncake-demo-mooncake-store-tqjvt 1/1 Running 0 3m42s查看 Mooncake Store 实例网络与位置信息
kubectl get pods sglang-pd-with-mooncake-demo-mooncake-store-dsrv4 -o jsonpath='{.spec.nodeName}'
kubectl get pods sglang-pd-with-mooncake-demo-mooncake-store-dsrv4 -o jsonpath='{.status.podIP}'Benchmark 测试结果:多级缓存加速显著
多轮对话场景测试表明,多级缓存架构对 KVCache 命中率与推理性能提升至关重要:
- Baseline(仅 GPU 显存):命中率低,平均 TTFT 5.91s,P90 12.16s,InputToken 吞吐 6576.85 token/s
- L2 DRAM HiCache:命中率 40.62%,平均 TTFT 降至 3.77s(↓36.2%),P90 10.88s,InputToken 吞吐 10054.21 token/s(↑52.89%)
- L3 Mooncake 缓存:命中率进一步提升,平均 TTFT 2.58s(↓56.3%),P90 6.97s(↓42.7%),InputToken 吞吐 15022.80 token/s(↑49.41%)

多轮对话测试场景下服务整体吞吐指标

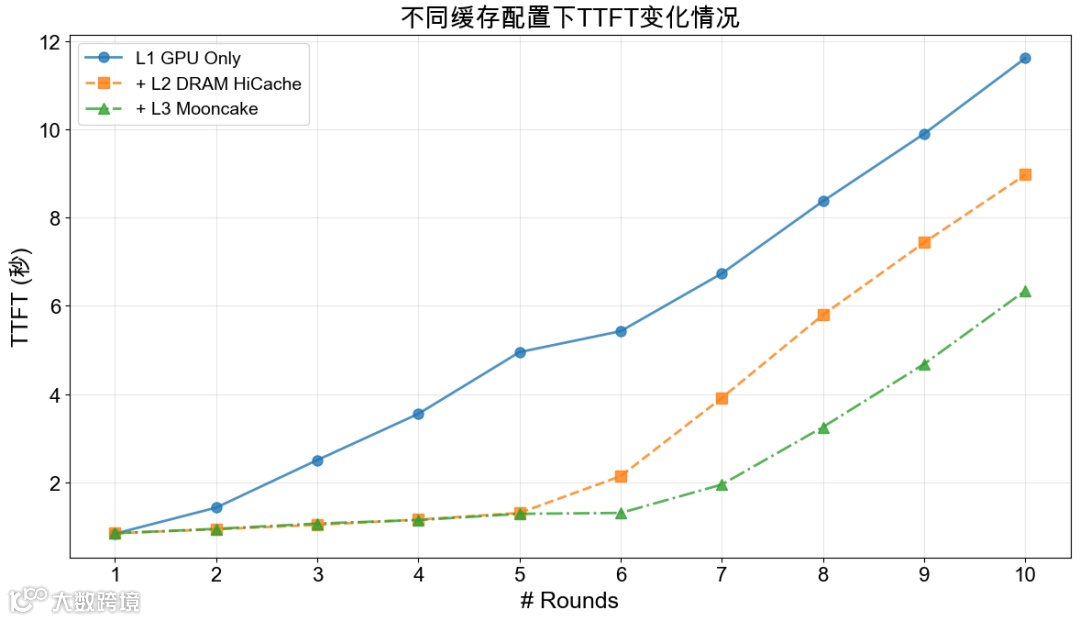
多轮对话测试场景下 KVCache 命中率及对应 TTFT 指标
测试细节详见附录 8.2
通过原地升级能力实现 Mooncake 版本平滑升级
Mooncake 与 SGLang Serving Backend 的 transfer-engine 需保持版本一致,因此推理引擎升级时 Mooncake 必须同步更新。但由于 Mooncake 数据通常驻留内存,传统滚动升级会导致缓存丢失,迫使活跃会话重新执行 Prefill 计算,引发 P99 延迟毛刺、吞吐断崖和服务抖动。
解决方案:Mooncake 缓存本地持久化 + RBG 原地升级
- 缓存本地持久化:Mooncake 支持将 KVCache 元数据与热数据快照持久化至节点共享内存或 NVMe,进程重启后可快速恢复状态,避免 Prefill 重计算。
- RBG 原地升级:通过 RBG 控制升级过程,避免重建 Pod,原地替换容器镜像并复用本地存储,保留已持久化缓存数据,实现“无缝”切换。
两者结合,使 Serving Backend 与 Mooncake 联合升级时 KVCache 状态得以延续,活跃会话无需回退到 Prefill 阶段,有效规避延迟与吞吐波动,保障端到端稳定性。

RBG 不仅解决多角色协同部署难题,更通过原地升级将“有状态缓存服务平滑演进”转化为标准化、自动化运维能力,真正实现“升级无感、服务不抖”的生产级目标。
以 v0.5.5 升级至 v0.5.6 为例:
kubectl patch rolebasedgroup sglang-pd-with-mooncake-demo \
--type='json' \
-p='[{"op":"replace","path":"/spec/roles/1/template/spec/containers/0/image","value":"lmsysorg/sglang:v0.5.6"}]'查看 Pod 状态可见,Mooncake Store 角色仅发生容器重启:
kubectl get pods -l rolebasedgroup.workloads.x-k8s.io/name=sglang-pd-with-mooncake-demo -owide
NAME READY STATUS RESTARTS AGE
sglang-pd-with-mooncake-demo-decode-0 1/1 Running 0 7m4s
sglang-pd-with-mooncake-demo-mooncake-master-0 1/1 Running 0 7m24s
sglang-pd-with-mooncake-demo-mooncake-store-bh9xs 1/1 Running 1 7m4s
sglang-pd-with-mooncake-demo-mooncake-store-dsrv4 1/1 Running 1 7m4s
sglang-pd-with-mooncake-demo-mooncake-store-tqjvt 1/1 Running 1 7m4s
sglang-pd-with-mooncake-demo-prefill-0 1/1 Running 0 7m4s
sglang-pd-with-mooncake-demo-router-0 1/1 Running 0 4m33s通过事件确认重启原因:
kubectl describe pods sglang-pd-with-mooncake-demo-mooncake-store-dsrv4
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 27m default-scheduler Successfully assigned ...
Normal AllocIPSucceed 27m terway-daemon Alloc IP 10.134.25.238/16 took 584.019653ms
Normal Created 27m kubelet Created container: store
Normal Pulled 27m kubelet Container image "lmsysorg/sglang:v0.5.5" already present on machine
Normal Started 27m kubelet Started container store
Normal Killing 21m kubelet Container store definition changed, will be restarted检查升级后 Pod 的节点与 IP 信息未变,结合缓存持久化能力,可确保 KVCache 状态完整恢复。
总结和展望
- RBG 重新定义 LLM 推理编排范式:将多角色协同与拓扑感知调度作为核心,不仅解决分布式部署复杂性,更通过原地升级攻克“有状态缓存服务平滑演进”难题,实现升级无感、服务不抖。
- Mooncake 解锁 KVCache 无限可能:作为 L3 缓存层,显著提升命中率,平均 TTFT 降低 56.3%,P90 延迟改善 42.7%,GPU 利用率从不足 30% 提升至可持续弹性水平,平衡性能与成本。
- 分级缓存架构是长上下文推理必由之路:从 GPU HBM → DRAM → Mooncake 的三级缓存体系已在 Benchmark 中验证有效性,尤其适用于多轮对话、RAG、AI Agent 等机器驱动场景,缓存复用带来的边际成本递减效应将持续放大。
RBG + Mooncake 的实践表明,唯有将高性能系统设计与云原生运维能力深度融合,才能推动大模型推理从“能用”走向“好用”,从“实验室”迈向“生产级”。期待与社区共同推进这一范式,为下一代 AI 基础设施奠定坚实基础。
- 小红书:孙伟祥、宋阳、熊峰
- 科大讯飞:杨彦波
- 趋境科技:杨珂
- Mooncake:马腾、蔡尚铭
- 阿里云:一斋、柏存、东伝
附录
8.1 镜像构建
本文示例可直接使用 SGLang 官方镜像 lmsysorg/sglang:v0.5.5(需包含 mooncake-transfer-engine >= 0.3.7)。定制需求可参考:https://github.com/sgl-project/rbg/blob/main/examples/mooncake/Dockerfile.mooncake
8.2 Benchmark 测试
8.2.1 环境配置

8.2.2 测试方法
使用 HiCache 多轮对话压测工具模拟 KVCache 可重用场景,对比开启 L3 Mooncake + L2 HiCache、仅开启 L2 HiCache 及不开启 HiCache 的推理服务在吞吐与 SLO 上的表现。
测试命令
python3 benchmark/hicache/bench_multiturn.py \
--model-path /models/Qwen3-235B/Qwen3-235B-A22B \
--dataset-path ShareGPT_V3_unfiltered_cleaned_split.json \
--disable-random-sample \
--output-length 1 \
--request-length 2048 \
--num-clients 150 \
--num-rounds 10 \
--max-parallel 4 \
--request-rate 16 \
--ready-queue-policy random \
--disable-auto-run \
--enable-round-barrier