


技术专栏导语

为什么你的 CPU 跑不满,但系统已经卡死了?
后端工程师最痛苦的时刻,不是 CPU 100%,而是 CPU 只有 30%,但 Latency 却居高不下。
在 EloqData 构建新一代在线数据库时,我们面临一个残酷的硬件现状:硬件进化的速度,已经把软件甩开了几个身位。
1
硬件性能的“剪刀差”
回顾过去十年(2014-2024),我们发现了惊人的趋势:
- CPU 性能挤牙膏:Intel i7-4790K 到 i9-14900K 的单核性能(GHz x IPC)仅提升了约 2.5 倍 。

- SSD 性能狂飙:2014 年的三星 XP941 只有 10 万 IOPS;到了 2024 年,单块 NVMe 设备能跑 200 万 IOPS。性能提升了 12.3 倍 。

- 网络带宽暴涨:从千兆进化到了 AWS UltraClusters 的 200Gbps,增长了 20 倍。

这意味着,单台服务器现在可以轻松实现1600 万 IOPS 。如果你还在用传统的线程池模型(Thread Pool),每个 I/O 请求都对应一次 read()/write() 系统调用和两次上下文切换 。结果是灾难性的:光是上下文切换的开销就能把 CPU 吃光。线程越多,调度争抢越严重,系统陷入“I/O 等待 -> CPU 争抢 -> 延迟飙升”的恶性循环 。我们不是在做 I/O,我们是在调度中挣扎。
2
传统模型的失效:为什么线程爆炸是必然?
在传统模型中,为了跑满 NVMe 的高 IOPS,你不得不创建大量的线程来等待 I/O。当并发 I/O 达到数百万次每秒时,即使每次上下文切换只消耗 1-2 微秒,累计的 CPU 成本也足以让 Latency 尾部(Latency Tail)无限拉长。
协程的出现,不再是锦上添花的优化,而是适应 NVMe 时代必须要做的范式转移(Paradigm Shift)。
io_uring + 协程的“核聚变”
为了配得上现代硬件的速度,我们必须把上下文切换的成本降到极致。我们的答案是:协程(Coroutines) + 异步 I/O(Async I/O) 。
1
为什么是协程?
协程 – 极致轻量级的调度魔法:
- 用户态操作:协程的挂起(Suspend)和恢复(Resume)是纯用户态操作,无需操作系统介入。
- 性能打击:耗时不到 10 纳秒。这是线程切换性能的 10 到 100 倍的性能提升。
- 可读性:它保留了同步代码的线性逻辑,彻底告别了令人头疼的回调地狱(Callback Hell)。
协程的优势在于其极致的轻量级。
2
架构核心:One Loop Per Core
我们抛弃了全局线程池,采用了以下架构 :
1. 绑定核心:每个 CPU 核心运行一个独立的 Worker 线程。
2. 全异步化:每个数据库查询(Query)被封装为一个协程。
3. 永不阻塞:
- 当协程需要 I/O 时,向io_uring 提交请求并立即 yield(让出 CPU);
- Worker 线程无缝切换到下一个协程;
- I/O 完成后,io_uring 通知 Worker,原协程被 resume(恢复)。
技术内幕:Worker 线程只在 Event Loop 末尾调用一次 io_uring_submit 批量提交 I/O,再调用一次 io_uring_peek_cqe 批量收割已完成的 I/O,批量处理所有请求,大幅减少了 syscall 开销 。
这种设计将系统调用(syscall)的开销均摊到无数个 I/O 请求上,让 CPU 资源全部用于业务逻辑的计算。

理想很丰满,落地全是坑
市面上讲原理的文章很多,但落地全是细节。以下是我们从理论到生产环境(Production)中踩过的真实陷阱。
1
坑点 1:C++ 标准的“分裂”
C++20/23 标准虽然引入了std::coroutine,但在工程实践中,我们必须面对不同成熟度协程库的混战:
|
协程形式 |
应用场景 |
优缺点与选择原因 |
|
手写状态机 |
核心事务处理 |
极致性能,但维护难度高。 适用于对性能要求苛刻且逻辑固定的核心路径。 |
|
brpc::bthread |
网络通信层 |
工业级成熟,调度模型稳定。 网络 I/O 场景下,我们依赖其成熟的 M:N 调度能力。 |
|
Boost.Context |
旧代码适配 |
有栈协程,可保存完整调用栈。 适用于将历史遗留或第三方同步查询代码强制“协程化”,避免大规模重写。 |
|
std::generator |
未来探索 |
无栈,内存占用极低。 在 GCC 14/C++23 普及后,正逐步应用到隔离的业务模块中。 |
R
结论
在复杂的数据库系统中,我们无法“一刀切”。必须采用混合编队策略,根据不同场景的成熟度和性能要求,选择最合适的协程实现。
2
坑点 2:隐形杀手 RocksDB
协程模型的最大风险在于阻塞扩散:一个协程卡死,整个 Worker 线程上的所有协程都将停滞。我们遇到的最大“暗雷”来自 RocksDB。
Q
问题
RocksDB 是优秀的存储引擎,但它是为多线程设计的,内部使用了大量的std::mutex 和条件变量。
R
后果
当我们的协程调用 RocksDB 操作时,一旦内部发生锁竞争,该协程将发生线程级阻塞,Event Loop瞬间停顿。
S
解决方案
我们果断引入了隔离层。所有涉及 RocksDB 的读写操作,都必须通过单独的 Offload 线程池进行卸载。协程仅负责向该线程池提交任务,并在 io_uring 上等待结果完成,绝不亲自踏入阻塞区。
下面的实验对比了两款Redis兼容的Key-Value存储,分别是基于RocksDB的KvRocks和基于 EloqStore(iouring+协程)的EloqKV。 从实验结果可以看出,iouring+协程技术,无论是吞吐还是长尾延时,都显著优于传统RocksDB存储。
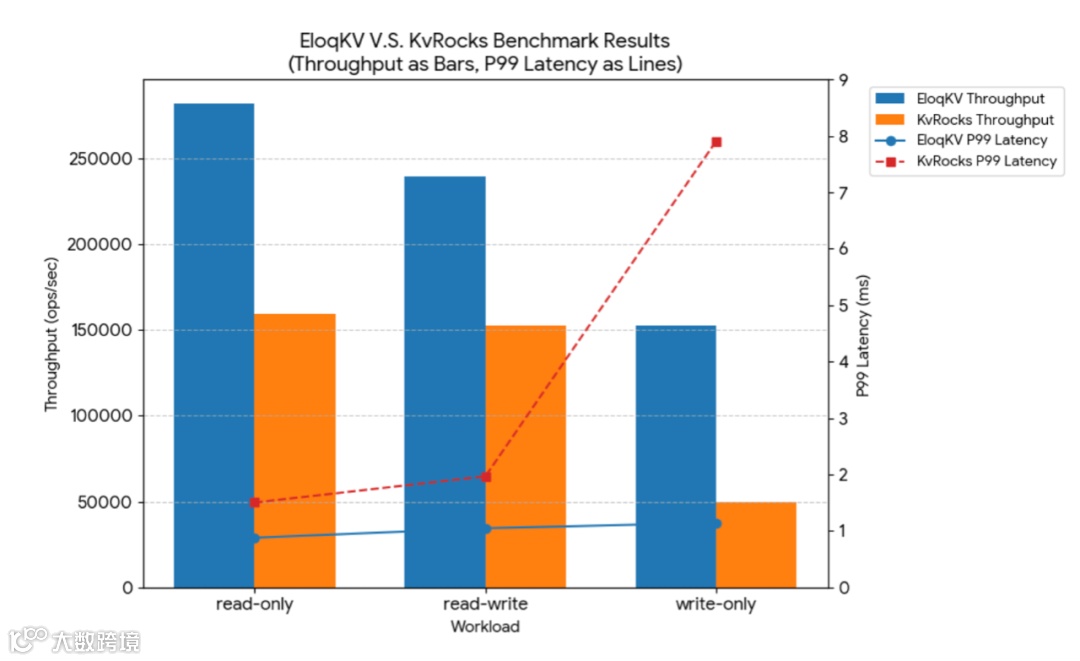
3
分布式下的“状态幽灵”
在分布式集群中,协程挂起时的“状态保存”机制,可能会导致严重的上下文安全问题。
当一个协程在挂起期间(例如等待 I/O),如果集群恰好发生了故障转移(Failover),该协程所持有的局部变量(如锁、节点租约)可能已经失效。当协程被唤醒时,它会拿着一个“过期”的锁或指针继续操作,极易引发数据损坏或内存错误。
C
挑战
协程“醒来”时,手里的资源可能指向无效内存。
S
解决方案
我们在resume 恢复执行的关键路径上,强制引入了资源验证机制(Resource Validation)。协程必须在继续执行前,验证其持有的所有分布式状态(如版本号、事务 ID、锁)是否仍然有效。一旦检测到上下文已被重置,则必须触发事务回滚或重试。
协程 + 异步 I/O 不仅仅是代码风格的变化,它是适应 NVMe 时代必须要做的范式转移。它让我们的数据库内核从“调度密集型”转变为“计算密集型”,真正释放了现代硬件的潜力。
虽然目前完全基于协程重写的存储引擎还不多,但这绝对是未来的方向。如果你的系统 I/O 吞吐上不去,别急着加机器,也许该看看你的 I/O 模型了。
Talk is cheap, show me the code.
为了验证io_uring 到底比pread 吞吐大多少,我们编写了一套可复现的Benchmark 基准测试脚本(包含 2 种 I/O 模型的性能对比源码)。
拒绝“云评测”,你可以直接在自己的 Linux 机器上跑分。
获取报告
Download the Report
关注公众号【晨章数据】,后台回复“io_uring”获取完整源码和测试报告 PDF。
