

Unite Shanghai 2025 于 10 月 23-24 日圆满举办。在团结引擎专场中,Unity 中国图形渲染主管金晓宇带来分享《团结引擎的并行渲染架构》,本文为演讲全文实录。点击阅读原文,可以访问 Unite Shanghai 2025 演讲录像,一起学习 Unite 分享的最新技术干货。


“这一切都值得吗?”——为什么要做并行渲染
首先,我们为什么要做并行渲染?这一切都值得吗?大概在五六年前,有开发者向我们提出过并行渲染的需求,但是由于各种各样的原因一直没有做。
我们是一个主线程很重的引擎,60 帧游戏,留给主线程的预算只有 16ms;30 帧的游戏,留给主线程的预算只有 33ms。随着开发者用的系统越来越多,主线程的消耗就会越来越大,这其中渲染逻辑往往占了很大的比重。
上图主线程中前面是游戏开发者经常用的各个模块逻辑,可以称之为游戏逻辑阶段或 Simulation 阶段。后面绿色是渲染相关的逻辑,包括 Culling 和 Rendering。随着用的相机越来越多,渲染的耗费会越来越长,它们都占用了主线程的开销。下面是 Unity 原来的渲染线程的概念,本质上是提交线程,在主线程提交命令之后会在提交线程上做具体的 API 提交工作,只有 Rendering 阶段有渲染那命令产生以后,提交线程才开始工作。所以弊端就是前面这些灰色的地方都在等待,有很长时间都是空闲的。

我们把图简化一下。当前没有并行渲染的情况下,Simulatian 和 Rendering 都堆积在主线程,提交线程大部分时候无事可做。当游戏接受输入,simulation 完成后,大部分数据就已经更新完毕了;而 rendering 只是使用这些数据来渲染画面。所以如果在 simulation 结束后,我们把渲染所需的数据 copy 一份,留给渲染线程使用,那么理论上说这部分渲染是没有必要堆在主线程后面的,可以在 Simulation 拷贝完数据后立刻启动,像下图这样。

Rendering、Submit 和主线程的 Simulation 并行执行,这更加高效,符合现代 CPU 架构的设计。但这是看上去简单,实际上却无比复杂的工程。在详细的分析了我们所面临的挑战后,这就是当时我们的心理侧写:You Died。
“You Died”——面临的挑战
首先,如何确保线程安全,这是最基本的问题,会贯穿整个开发过程。

现在团结引擎的 CI 有 150 万左右的 test,但是无法 100% 保证线程安全,因为 Test 无法覆盖所有的代码,即使 Test 通过,也无法证明一定线程安全,有可能有没测到的功能,也有可能只是不稳定,这次通过了下次没过。另外,运行时线程的 bug 其实难以发现和修复。影响代码的范围也不确定,容易遗漏线程安全问题。最要命的是小概率线程竞争问题在开发/测试阶段容易被遗漏,而在高频次的开发者使用中暴露出来,到时候很难复现并修复。

第二,在代码中有各种各样的全局变量。一部分是历史原因,因为 Global R&D 在写代码时默认渲染逻辑是运行在主线程上的,所以在代码中充斥了很多全局变量或者单例。那怎样保证线程安全?最简单的,加锁可以保证线程安全吗?可以,虽然线程安全了,但是无法保证时序的一致性,因为主线程和渲染线程是并行的,即使加了锁,当渲染线程要使用某个全局变量时,它随时有可能被主线程改掉,造成渲染结果错误。另外是性能开销,随着锁越来越多,主线程和渲染线程的并行度就会越来越差。

第三是渲染管线,我们有 Builtin 管线、URP 和 HDRP,开发者还可以实现自定义渲染管线;我们底层有不同的、供用户扩展的回调接口(C# 接口),全部是在主线程的回调,而并行渲染要分为主线程和渲染线程的回调;那么渲染过程中的回调该如何处理,因为这些调用在渲染线程,是不能访问主线程所用的数据的,比如 Game Object,component 等等;这些该如何处理呢?

第四是涉及的模块非常多,包括 MeshRenderer、SkinnedMeshRenderer 以及其他各种各样的 Renderer,ParticleSystem、Terrain、UI(包括 UGUI、IMGUI、NGUI 等)、2D 的模块、Flare、Light、Camera、Psot process,还有其他没有列出来的模块,任何漏掉的或者没有处理好的模块都会爆发出严重问题。

最后是脚本的执行,由于历史原因,大部分的脚本只能执行在主线程上,大部分的接口都不是线程安全的接口。脚本可以访问几乎所有的引擎资源,而用户的代码因为要执行在渲染线程上,自然有渲染线程回调供用户使用和自定义,用户代码理论上可以调用所有 Runtime 接口,我们也没办法禁止开发者调用他们需要的接口,它们几乎都不是线程安全的,难道我们要把所有的接口都改成线程安全的吗?这些归根到底总结成一句话——“任何遗漏的线程安全问题都可能造成严重的后果”,而且这些严重的后果有可能在开发者的手中集中爆发出来。
“It is a good pain.”——我们的方案
接下来和大家介绍一下我们的方案,方案总结成一句话,It is a good pain。这个方案初期会带来一些困难,但长远来看,阵痛是有必要而且有益的。我会从渲染架构开始讲,最后会讲我们的系统,以及为什么我会说它是 a good pain。

渲染架构首先要重构。让我简化一下改造前的流程图。我们分成两帧,Frame N 和 Frame N+1。每一帧由 Game Simulation 和 Rendering 两阶段组成,比较重要的是下面的 game data,Simulation 和 Rendering 访问的是同一份数据,不管是 global 变量还是其他的单例,它们的时序可以保证是一致的。

我们现在要把 Render 拿下来,把渲染线程放在子线程上面去。但是有一个问题,我们新写的代码可以访问新的数据,保证它与之前的主线程 game data 是两份数据,但是原来的代码(运行在渲染线程上)还访问着 game data,他们与主线程的逻辑会同时访问 game data,就会出现 racing condition 的情况,这是我们要解决的比较头疼的事情。

简单来说,我们让这些代码不去 read/write game data,而是 read/write 我们自己的 Proxy 数据。这样看上去问题好像就解决了。

那就引出 Proxy,什么是 Proxy?首先它是 game data 的数据代理,需要每帧创建、复制数据。GameObject 可以有 Proxy,Component 可以有 Proxy,全局变量也可以有 Proxy。因为它是每帧创建的,我们控制了复制的数据量,只复制渲染需要的数据,尽可能降低复制开销。
为了尽可能降低 proxy 的 overhead,我们加入了 proxy buffer 的机制,会预分配内存,主要是为了方便创建,也可以说其实是一个内存池。这样 proxy 几乎没有创建开销,因为创建仅仅是指针移动的开销。它是双 Buffer 的机制,保证了主线程和渲染线程在并行运行中访问的是不同的 buffer,在合适的时间点 swap(交换)一下,避免了 data racing;同时这大大降低创建的开销,并且 proxy 是内存连续的,也可以提升缓存命中率。

用 proxy buffer 我们大大降低了 proxy 的创建开销,但是数据复制的开销依然存在,因此我们实现了 static proxy。我们把 Proxy 分成两类,一种是 Dynamic 的,一种是 Static 的。Dynamic 的每帧都要创建并复制数据,用于动态物体;对于静态物体,在数据没有改变时,不需要每帧创建。当这些静态物体更新时,我们的系统也能适时的更新 static proxy 的数据,尽可能地少复制,我们通过这个机制显著降低了复制数据的开销。

处理好了数据之后,剩下的就是怎么把执行逻辑放到渲染线程上。简单地说,我们用 Lambda 把原本主线程执行的逻辑直接推到渲染线程执行。这里有一个简单的例子,利用 lambda 把 UpdateSkinnedMeshes() 这个函数推到了渲染线程上执行。后面我会讲这个函数的模版参数。这里的宏会方便我们改写和追踪。

剩下的问题就是脚本在渲染线程上的执行。首先它不能访问 game object 或 component,会 data racing。目前的方案开发者在 C# 中需自主控制避免 data racing 的代码,我们提供了一定的机制来引导开发者写出正确的代码,但是理论上来说我们没办法阻止开发者写出线程不安全的代码。所以在并行渲染的架构下,写渲染管线就需要多考虑一层线程安全问题。Proxy 的框架是 C++ 的,那 C# 自然需要同样的一份 C# Proxy 供开发者自定义。

这里给出了一个 C# 实现自定义 Proxy 的例子。UniversalAdditionalLightData 是 URP 中挂在 light 上的一个 component,它提供了 light 的一些额外的数据。我们在渲染线程是没办法直接访问它的。所以开发者需要声明一个对应的 proxy;这个 proxy 的命名是有一定规则的,它必须是在原 UniversalAdditionalLightData 基础上加 _Proxy,并且继承自 MonoBehaviour_Proxy。它有两个特点:一个是自动创建,用户无需管理,与 C++ 的 Proxy 机制是一样的。第二个是无需挂载(attach),这里的意思是 component 都需要挂到 game object 上才能生效,但由于 proxy 是个临时对象,它与 game object 只有潜在的对应关系,生命周期是不同的,所以它不能也无需挂载到 game object 上。

那接下来就是数据复制的问题,为此我们提供了一个调用函数。开发者只需要实现一个叫 OnProxyCreate 的方法,就可以完成 copy 数据的任务。引擎会自动把关联的 component 作为参数传递过来,这样开发者就可以根据自己需求来 copy 必要的数据。大家需要注意只拷贝渲染用到的数据就可以了,把拷贝的数据量降到尽可能低。左上角的 attribute [Preserve] 是必须的,这是为了防止引擎的 strip 功能错误地把 proxy 代码剔除掉。

我们回顾一下。我们把改造前的 Rendering 细化为 culling, post culling, rendering 三个阶段;每个阶段都有一些 event 触发的回调事件,这些回调函数的对应代码,都是我们需要处理的。

我们现在把 rendering 逻辑移动到渲染线程上,流程就变为了上图这个样子。在 post culling 后加入了一个阶段来 fill proxy,也就是创建我们所需的 proxy,之后启动渲染后,渲染线程访问的就是 proxy 数据了。
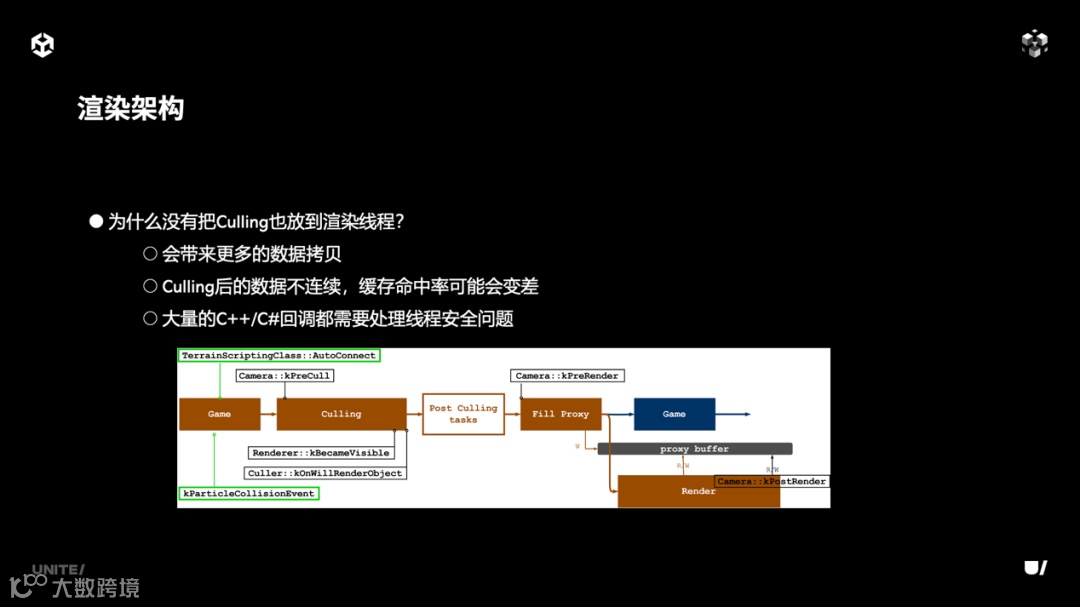
为什么没有把 Culling 也放在渲染线程呢?理论来说 Culling 放过来开销更低。但是这会带来更多的数据拷贝,因为 culling 往往能帮我们 cull 掉 80~90% 的物体,如果把 culling 也放到渲染线程,这就意味着我们需要把场景中所有的物体都作为 proxy 进行 copy。第二 Culling 后的数据可能是不连续的,由于通过 culling 的物体只是一小部分,这就导致渲染逻辑访问的数据并不连续,从而缓存命中率会变差。由于以上两个劣势,就有可能抵消掉把 Culling 搬过来的性能优势。
第三是有大量的 C#/C++ 回调都需要处理线程安全问题,从 culling 开始直到 rendering 之前,有大量的 event 会发送给不同的模块,如果搬到渲染线程都需要处理潜在的线程安全问题;这无疑会大大增加重构的工作量。所以最终我们决定只把 rendering 的逻辑放到渲染线程,这样的数据复制量、缓存的命中率和我们要处理的线程安全问题可以降到最低。

总的来看,渲染线程只可以访问 Proxy 数据,在 Fill Proxy 之后是渲染线程和主线程的同步点,在这时候才能启动,要保证 Proxy Buffer 已经填充完毕了。
这里可以详细讲解几个点。虽然 Culling 没放到渲染线程,但是我们做了一定的改进。以前的团结引擎和 Unity 的逻辑,有三个 camera,执行逻辑是 Cull、Render 交替。现在我们把三个 camera 的 Culling 放在一起,生成三个 views 集中做,这样可以充分发挥 job system 的多线程优势,也能尽可能的降低主线程的开销。另外就是 static proxy,当 Game 有一些主线程上(即 game object)数据变动的时候,我们也会更新 Proxy 数据,而不是在最后。另外有些工作是和游戏逻辑没有关系的,比如粒子的更新,我们也把它放到了渲染线程上。

了解了整体架构之后,接下来我想讨论一下如何保证重构质量。还是那几个问题,运行时的线程 bug 难以发现并修复,影响代码范围不确定,容易遗漏线程安全问题,小概率线程竞争问题在开发/测试阶段容易被遗漏,而在高频次的用户使用中暴露出来,最后如何保证项目能够收敛。如果发散以后各个模块不断曝出来问题,我们的功能最终是没办法完成的。

我们拿 Camera 举个例子。传统思路下我们需要做两件事情,一个是创建 Camera Proxy;相对应原来处理 camera 的渲染逻辑,会有处理 camera proxy 的供渲染线程版本的 function,但是这会有一些问题。首先从 function 讲,有大量重复的代码。那些原本运行在主线程的代码需要写一份渲染线程的版本,这有可能导致渲染线程版本的函数逻辑与主线程的不一致,造成不期望的结果;另外 2 套代码也不好维护,一旦有修改就需要同时修改 2 份代码,非常繁琐。其次需要运行时判断,增加了 overhead。比如在这个 function 里,需要判断当前执行在哪个线程上,再往下传不同的参数,判断是 camera 还是 proxy,所以用传统思路来做是有很大风险的。

因此我们构建了一套系统称为安全围栏。就是我们前面所说的 a good pain。简单来说,我们在渲染线程触及的逻辑和数据中引入了模板参数,标记此时的逻辑用于哪个线程,是主线程还是渲染线程,使用模板可以在渲染线程最大程度复用已有的主线程代码,降低引入 regression 的几率。我们第一个版本的目标是保证渲染和之前完全匹配,所以复用了大量的原来代码。引入模板参数的过程等于梳理了渲染线程所有的分支逻辑,虽然需要人工改造,但是只需要做一遍,并且可以多人并行,过程简单无脑,套模板就好了。如果模版编不过,就说明 code path 不对,code path 不对说明主线程使用了渲染线程的接口,或者反过来。

我们通过模版来生成了 2 套代码,分别给主线程和渲染线程用;函数参数也通过模版来接受不同的数据结构,以图示的例子来说,主线程版本接受 Camera 类,而渲染线程版本接受的是 Camera_proxy 类。

安全围栏有什么优势?首先没有运行时 overhead,不需要运行时判断了。第二,因为是把原本主线程的函数改为了模版,所以天生就是复用了主线程的代码,这样最大程度保证系统是可以 work 的。第三,可以兼容主线程和渲染线程数据结构。第四,最重要的是编译时可以自动检查,在渲染线程上运行未完成改造的函数会编译不过,在渲染线程上访问未完成改造的数据结构会编不过;如此虽然不能完全避免,但我们最大程度上避免了 data racing 的问题;而且编译期可以覆盖系统的所有代码,而不像运行时只覆盖跑得到的代码。此外我们还支持渐进式改造,提供了一些改造中的宏来欺骗编译器,可以只改负责的代码,其他的代码可以暂时骗过编译器,至少是可以编过的,这样我们也能多人并行进行改造。最后关闭宏就可以了解哪些模块未完成改造。
“大人,时代变了”——优化提升
接下来讲一下优化提升,我想和大家说,“大人,时代变了”。
理论来说,改造成并行渲染之后,主线程有更多的预算留给游戏逻辑,卡顿减少,帧数更稳定。一个 30 帧的游戏,budget 是 33 毫秒的话,现在把 rendering(假如 10 毫秒)放到了渲染线程,主线程还空着 10 毫秒的 budget。做实例化或加载的时候有些卡顿的话,主线程消耗的时间更长了,10 毫秒的 budget 则更有利于主线程保持 30 帧的运行。随着手机上主线程的消耗降低,CPU 的核心频率会降低,电压就会降低,功耗就更低。渲染逻辑会有更多预算,原来只有 10 毫秒的 budget,现在变成 33 毫秒的 budget,可以支持更宏大、更复杂的场景,支持的 Draw call 会更多一些。

简单看一下 Profiling 的情况。左边是并行渲染 Off 的状态,右边是并行渲染 On 的状态。在这个例子中,游戏逻辑和渲染都集中在主线程,是游戏逻辑和渲染比较平衡的状态。开启并行渲染之后,很大一块的渲染开销移动到了渲染线程上,主线程有更多的空余时间,消耗降低,主线程的消耗从 12.17 毫秒降到 9.88 毫秒。

这个柱状图是我们测了三个 case 的帧率对比,左边两个是 CPU bound,右边一个 GPU bound。两个 CPU bound 的情况下,能看到并行渲染对帧数上有一定提升,中间是 Draw call 数量比较多的情况,提升也会相对更大一些。而 GPU bound 不在我们的考虑之内,GPU bound 下开不开并行渲染线程对帧数影响不大。整体来看测试的场景当中,主线程消耗下降 10%—30%,功耗下降 7%—15%,帧数提升 10%—15%,帧数更稳定了。
“那么,代价是什么?”——有什么限制
看了优势,我们再来看一下开发者需要多付出哪些努力。

首先是渲染线程的脚本执行,不能访问 Game object 或 component 等数据,这个要谨记在心,作为代替,可以访问 Proxy 数据。还有一点,我们无法把数据写回到主线程,一般来说,我们认为这种操作是没有意义的;因为渲染线程的运行要比主线程慢一帧,这就导致渲染线程的更新也会慢一帧,如果主线程也对相应数据有改写,那其实我们是不知道两个线程究竟哪个数据更新是正确的;所以对于有写入或数据更新的操作,我们建议都放在主线程执行。我们可以访问 Proxy 数据,即用户自定义的数据,但开发者依然需要保证自己代码的线程安全。我们提供一些机制和警告或错误来提示大家,但是本质上很遗憾我们暂时没有一个机制能帮助大家来保证这个事情。

另外还有一些限制。要支持并行渲染,URP、HDRP 这些 SRP 管线都不可避免需要改造,自定义管线需要开发者自行适配。但是要强调一点,大家现在用的管线如果不开并行渲染是不受影响的,无需改造,只在需要开启并行渲染的时候才需要做适当适配。
内存方面,我们有 Proxy 数据、Proxy Buffer,还有其他临时数据,有一定内存的增大是不可避免的。测下来,不同场景中内存增大大概在 2%—10% 左右。

由于工作量的原因,目前还有未支持的模块,包括 GPU Resident Drawer、BRG、VFX、虚拟几何体(VG)、VSM,以及一些 API 暂时没有支持,像 Graphics.DrawMesh、CommandBuffer.DrawMesh 等等,但其他的像 CommandBuffer.DrawRendererList 等都是可以用的。
“向着星辰与深渊!”——展望未来
最后我们看一下未来的计划,给我的感觉就是既有星辰也有很多需要探索的地方。我们目标同时支持 HDRP、URP、Builtin 管线,同时支持 Windows、Mac、iOS、Android 以及小游戏平台,会逐渐支持更多的引擎功能,进一步减轻主线程的压力。最重要的是我们会持续优化性能。

谢谢大家,我今天的分享就是这些。

Unite Shanghai 2025 演讲回放录像已上线 Unity 中文课堂,点击阅读原文即可访问,购票用户可免费观看。请持续关注,一起学习 Unite 分享的最新技术动向。
长按关注
第一时间了解 Unity 社区动向,学习开发技巧

点击“阅读原文”,观看演讲录播
