


【案例1】

某系统后台采用Oracle数据库作为数据存储,该系统的某业务需要对表Table执行查询操作,该查询操作执行时间不稳定,有时出现执行时间较长的问题。
业务执行的SQL语句较为简单,只对表Table这一单表执行了查询操作,如下所示:

对该SQL语句的执行计划进行分析,其执行计划如下所示:

通过执行计划可以发现,该SQL语句执行时,首先使用了COLC列的单列索引IDX_COLC执行了过滤操作,之后进行了回表并按COLA、COLB、COLD列进行了二次过滤。
对于这种通过索引再回表的查询,其执行效率与索引过滤需要访问的数据量有关。
对索引列COLC的数据分布情况进行分析,如下所示:

通过以上的查询结果可知,索引列COLC的数据存在严重的分布不均衡的问题,总量最多的02值与总量最少的06值之间相差达到356倍,表TABLE共有6723116条记录,如果查询条件为COLC=02,通过该索引访问后需要执行5687854次的回表再过滤操作,回表的记录数已经达到全表记录的84%,理论上,此时更适合直接采用全表扫描的方式。
由此可知,索引列COLC的数据分布问题是导致该查询执行时间不稳定的直接原因。
对于该查询的优化,需要重新选择索引列。
一个列的数据分布严重不均,从另一个角度反映了该列存在大量的重复数据,存在大量重复数据的列的选择性是较差的,选择性较差的列不适合建立索引。
对该SQL语句的其他过滤列的分布情况进行分析,并按选择性从高到低进行排序,结果为COLD>COLA>COLB,因此,可以按选择性从高到低为这三个列创建一个复合索引IDX_DAB(COLD,COLA,COLB)。
设置复合索引后,每次执行SQL语句时,通过该复合索引可以过滤掉表TABLE中的大量记录,需要读取的索引块较之前大量减少,只需执行少量的回表后再按COLC列的过滤操作,执行耗时稳定在1秒左右。
【案例2】

某系统后台采用Oracle数据库作为数据存储,该系统的某业务需要对表Table执行查询操作,该查询操作执行时间不稳定,有时出现执行时间长达数十分钟的问题。
业务执行的SQL语句对表Table执行了自关联的NOT EXISTS子查询操作,如下所示:

对该SQL语句的执行计划进行分析,其执行计划如下所示:

通过执行计划可以发现,该SQL语句执行时,优化器(CBO)已经将子查询展开为HASH反连接操作,所以不存在子查询未展开导致的性能问题。
分别单独执行该SQL语句中的主查询部分语句和子查询部分语句,其中主查询返回2087条记录,子查询返回2017894条记录,执行计划中,主查寻结果集与子查询结果集执行了HASH 反连接操作,HASH连接适用于较大表或结果集的关联,因此,优化器选择的HASH 反连接操作是正确的。
继续分析对表Table的访问操作,对表Table执行过滤时,优化器采用了INDEX RANGE SCAN索引范围扫描的方式,且没有回表访问。
表Table共有250万左右的记录,查询访问的IDX_UID_IDA索引是一个复合索引(uid,insertdate,pid),其大小超过2GB,子查询通过INDEX RANGE SCAN(索引范围扫描)返回了2017894条记录,已经达到全表记录的80%,需要访问大量的索引数据块。
当IDX_UID_IDA索引数据块从ORACLE数据库的BUFFER CACHE缓冲区中置换出去后,执行该查询时就需要从磁盘读取索引数据块,INDEX RANGE SCAN(索引范围扫描)是单块读,其效率较差,特别是当所读取的索引数据块较多时,索引数据块的读取消耗了大量的时间,导致查询的执行时间较长。
当IDX_UID_IDA索引数据块存在于BUFFER CACHE缓冲区中时,执行INDEX RANGE SCAN(索引范围扫描)无需再读取磁盘,直接从缓冲区获取,此时执行相同的查询,其执行时间就是较快的。这就是该SQL语句执行时间不稳定的原因。
对于该查询的优化,因为其对表TABLE访问后需要返回该表80%的数据且没有回表操作,其完全可以通过访问索引即可获取到所需的数据,所以,可以使用INDEX FAST FULL SCAN(索引快速全扫)替代优化器采用的INDEX RANGE SCAN(索引范围扫描),INDEX FAST FULL SCAN(索引快速全扫)采用多块读的方式,适合于大量数据块的读取,在IDX_UID_IDA索引数据块需要从磁盘中读取的情况下,其读取效率高于INDEX RANGE SCAN(索引范围扫描)。
使用/*+ index_ffs(T2) */提示器强制exists子查询对表TABLE访问时采用INDEX FAST FULL SCAN(索引快速全扫),即:... AND NOT EXISTS( SELECT /*+ index_ffs(T2) */ PID ... ...)。
优化后,该SQL语句的执行时间控制在5秒左右,即使发生了从磁盘读取索引数据块的操作,整体执行时间也降低至60秒以内。
【案例3】

某系统后台采用Oracle数据库作为数据存储,该系统的某业务需要对表PRPLXXXX,即:别名表A和表PRPLREXXXX,即:别名表B执行关联查询操作,某日,该查询操作执行时间突然变长,超过60分钟。
业务执行的SQL语句如下所示:

对该SQL语句的执行计划进行分析,其执行计划如下所示:

通过执行计划可知,表A与表B采用了嵌套循环关联,表B作为被驱动表,且被驱动表在关联列上使用了索引扫描,该执行计划看似是“正确”的。
进一步分析参与关联的表A与表B的结果集的大小,发现关联的两表结果集的记录数基本在95万左右,其中作为驱动表的表A使用WHERE条件过滤后的记录数达到94万条左右,这将导致被驱动表表B被访问94万次,显然,这种关联方式的性能是低下的,优化器选择了错误的关联方式。
应将表A与表B的方式调整为HSAH关联,使用提示器强制使用HASH关联,即:/*+ use_hash(A,B) */。
调整后使用HASH关联,该SQL语句的执行时间降低至4分左右。
进一步分析优化器选择错误关联方式的原因,表A中数据随系统的运行不断增长,但未及时收集统计信息,优化器一直使用的是数据较少时的旧的统计信息,导致优化器认为表A的数据较少,因此仍然使用之前的嵌套循环关联方式。
对表A重新收集统计信息,去掉语句中的强制使用HASH关联的提示器,重新执行查询,优化器在执行该查询语句时可以正确地选择采用HASH关联的方式对表A和表B进行连接。
【案例4】

某系统后台采用Oracle数据库作为数据存储,该系统的某业务需要同时对表t1、t2、t3执行查询操作,该查询的执行时间达到1分钟左右。
业务执行的SQL语句如下所示:

该SQL语句中存在两个exists关联子查询,且它们之间的关系为or,对该SQL语句的执行计划进行分析,其执行计划如下所示:
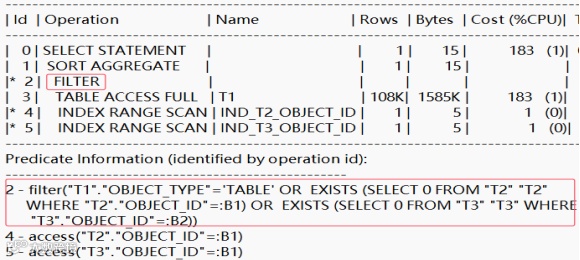
该查询的执行统计信息如下所示:

通过执行计划和统计信息可知,该查询执行时,因存在对两个exists相关子查询结果集的or操作,使得优化器未能消除exists子查询,执行计划中产生了FILTER操作,该查询的访问的主表t1返回的记录较多,使得FILTER操作的性能较低,查询执行时的逻辑读(consistent get)达到1849940,这是导致该查询执行效率不高的主要原因。
对该SQL语句的优化,需要通过等价改写的方式,使用union/union all替代对exists子查询结果的or操作。
首先将对表t2和t3的exists关联子查询更改为表t2与表t1,表t3与表t1的连接查询,将这两个查询结果使用union连接(去掉两个结果集中的重复数据),该部分语句如下所示:

之后,对表t1执行查询,并将查询结果集与上述查询的结果集执行union all操作(保留两个结果集中的重复数据),最终修改后的查询语句如下所示:

改写后的查询,其执行时间降低到2秒左右,以下展示了改写后的查询语句的执行计划:

通过改写后的执行计划可知,查询执行时,已经消除了FILTER操作,统计信息如下所示:

改写后的查询,执行时的逻辑读(consistent get)由之前的1849940降至2027。
......
本文节选自第八十六期《51测试天地》
原创文章
《Oracle数据库查询优化案例几则》
文章后续将继续为大家介绍
“案例五”内容
想继续阅读全文或查看更多《51测试天地》的原创文章
请点击下方 阅读原文或扫描二维码 查看

每日有奖互动
文中的哪个优化案例让你最有共鸣?
为什么?

