

在 CAMEL AI 框架的开发过程中,我们一直在使用浏览器自动化工具来驱动 AI 智能体(AI Agents)完成复杂的 Web 任务。我们的技术起点,是基于 Playwright Python 绑定的纯 Python 方案。但随着用例的增加,我们逐渐发现了一些无法回避的痛点。
首先,是快照质量的不稳定性。AI 智能体需要准确理解网页内容才能做出正确决策,而当时我们只能自行遍历 DOM 树并编写 JavaScript 脚本来提取元素信息。这个过程不仅繁琐易错,还经常遗漏关键的交互元素。
其次,成本与速度难以兼顾。当页面内容复杂时,我们不得不向 AI 提供可视化截图来辅助理解布局。但图像 token 的成本是文本的数倍,处理速度也慢得多。反之,纯文本快照虽然廉价且准确,但在遇到复杂的视觉布局时又容易出错。我们需要一种能够在这两者之间智能切换的机制。
最后,表单填写的可靠性也是一大挑战。现实世界的网页表单千奇百怪:有些输入框隐藏在多层嵌套中,有些下拉菜单是动态加载的,有些日期选择器只有在点击后才显示真正的输入框。纯粹依赖 Playwright 的基础 API 很难处理这些边缘情况。
因此,我们决定从架构层面重新思考这个问题。
为什么我们决定重构到 TypeScript?
CAMEL 是一个纯 Python 框架,引入 Node.js 无疑会增加依赖的复杂性。但经过深入调研,我们发现这几乎是一个必然的选择。
Playwright 本质上是用 TypeScript 开发的,其 Node.js 版本是“一等公民”。许多高级功能总是优先在 Node.js 中实现,然后再被移植到 Python 绑定。例如,Playwright的 _snapshotForAI()API,它可以生成为 AI 优化的 DOM 快照,自动处理 ARIA 属性、元素层级、可交互性判断等一系列复杂逻辑。如果坚持使用纯 Python,我们需要自己编写上千行 JavaScript 代码来实现这些功能,而且很难保证质量。
更重要的是,浏览器本身就运行在 JavaScript 环境中。当我们需要在页面内部执行一些高级操作时——比如检测元素是否被遮挡,或动态注入视觉标记——在浏览器的 JavaScript 上下文中直接执行,其效率远非 Python 端间接控制所能比拟的。
因此,我们最终敲定了如下架构:
TypeScript 层:负责浏览器交互。管理所有与 Playwright 和 DOM 操作相关的逻辑,直接调用原生 API,追求最佳性能。
Python 层:负责 AI 编排。管理 LLM 调用、智能体决策和任务流程控制,充分发挥 Python 生态的优势。
两者通过 WebSocket 进行异步通信,互不阻塞。Python 端发起浏览器操作请求,TypeScript 端执行并返回结果,整个过程对都用户保持透明。


多模态输出:在成本与准确性之间找到平衡
在拥有了稳定的快照生成能力后,我们开始思考下一个问题:什么时候该用文本,什么时候该用图像?
在实际使用中,我们发现纯文本快照在大多数情况下是足够的。例如,填写一个登录表单,AI 只需要知道“这里有一个用户名输入框 ref=e123,一个密码输入框 ref=e124,以及一个提交按钮 ref=e125”,它就能准确完成任务。文本 token 成本低、处理快、信息也非常精确。
但在某些场景下,纯文本会丢失关键信息。例如,一个包含几十个按钮和图表的复杂仪表盘,其文本快照可能长达数千行,AI 很难从中理解哪个按钮具体在哪个区域。或者像“把蓝色按钮移动到右上角”这样的视觉设计任务,没有截图根本无法完成。
因此,在将所有操作动作解耦为原子化工具后,我们同时提供了 browser_get_page_snapshot(获取页面快照)和 browser_get_som_screenshot(获取 SoM 截图)作为 AI 智能体的可选动作,允许智能体根据任务需求在这两种模式间自由切换。
快照优化:让 AI 看得更“准”
即使有了 _snapshotForAI(),我们发现生成的快照仍有优化空间。
// 问题1:装饰性元素的干扰
Playwright 快照会包含所有 ARIA 可访问的元素,这也包括了大量纯粹的装饰性图标、分隔符和装饰性文本。例如,一个导航栏可能有 50 个元素,但真正可点击的只有 5 个链接,其余都是装饰。这些噪声会分散 AI 的注意力,增加推理成本。
我们的做法是在 Node.js 端增加智能过滤逻辑。通过 snapshot-parser.ts 解析 DOM 的层级关系,我们能识别出真正的“母元素”。例如,如果一个按钮内部嵌套了图标和文本,我们只保留最外层的按钮元素,并过滤掉内部的装饰性子元素。这种过滤通过 filterClickableByHierarchy()实现,其规则包括:如果一个链接标签包含一个 img,则移除 img 只保留链接;如果一个按钮包含通用元素,则移除这些通用元素只保留按钮。
// 问题2:无意义的屏幕外元素
网页通常很长,用户当前只能看到一小部分(即视口,Viewport)。但快照默认包含整个页面的所有元素,包括那些需要滚动才能看到的部分。这对 AI 来说是纯粹的噪声——它不应该试图去点击一个还没滚动到视野内的按钮。
为此,我们增加了一个 viewportLimit 参数。启用后,快照将只返回当前视口内的元素。这一过滤操作在浏览器端完成,通过调用 isInViewport()函数检查元素的 getBoundingClientRect()是否在可见区域内。这样,AI 看到的快照更聚焦,决策质量更高。
// 问题3:元素遮挡带来的误导
有些元素虽然存在于 DOM 树中,但实际上被其他元素(如弹窗、浮动菜单)遮挡了,用户既看不到也无法点击。如果我们将这些元素包含在快照中,AI 很可能会做出无效的点击尝试。
在 SoM 截图模式下,我们实现了遮挡检测。通过 checkElementVisibilityByCoords()函数,我们对每个元素的中心点调用 document.elementsFromPoint(x, y)。这是一个浏览器原生 API,它能返回该坐标点上的所有元素堆叠列表(按 z-index 从高到低排序)。如果我们的目标元素不在这个列表的最顶层,就意味着它被遮挡了。对于这类元素,我们会用虚线框(而非实线框)标出,或者直接将其过滤。
这些优化都得益于 TypeScript 架构。document.elementsFromPoint()是用浏览器原生 C++ 实现的,性能极高。如果换作在 Python 端,我们只能先获取所有元素的坐标数据,再自己用低效的算法去模拟计算遮挡关系,既慢又不准确。
SoM 截图:为何选择“浏览器内注入”,而不是“图像后处理”?
SoM (Set-of-Mark,标记集)截图带来了一个有趣的设计挑战:我们需要在截图中标记出所有可交互元素,并为每个元素绘制边框和编号。
最直观的方法是:先截图,然后用 Python 的 PIL 库在图片上画框。早期我们的纯 Python 版本就是这么做的。但我们发现这个方案有几个问题:
视觉质量差:PIL 依赖 CPU 进行软件渲染,绘制的线条和文字边缘有明显锯齿。
跨平台不一致:PIL 依赖系统字体库,在 Windows、macOS 和 Linux 上的字体路径各不相同,经常导致“找不到 arial.ttf”之类的错误,最终只能降级使用丑陋的默认字体。
坐标映射复杂:当以 CDP 模式连接到不同分辨率的浏览器时,需要编写繁琐的缩放比换算逻辑,才能将元素坐标准确映射到截图的像素位置上。
数据传输量大:Python 方案需要先执行 JS 收集所有元素的详细信息(坐标、属性、元数据等),再序列化为庞大的 JSON 传回 Python。这个 JSON 里包含了大量 SoM 并不需要的冗余字段(如
disabled,checked等)。
而 TypeScript 版本的做法是:直接在浏览器中注入 DOM 元素作为标记,然后再执行截图。
具体流程如下:
通过
page.evaluate()在浏览器上下文中执行 JavaScript。创建一个覆盖整个页面的
overlaydiv,并将其z-index设为最高。为每个需要标记的元素,创建一个
labelldiv,通过 CSS 设置其边框、背景色、文本内容,并精确定位。调用
requestAnimationFrame()确保浏览器已完成渲染。执行截图。
截图完成后,再次调用
page.evaluate()移除该overlay。
这种做法的好处是:
视觉效果完美:所有标记都是由浏览器渲染引擎(GPU 加速)绘制的,自带抗锯齿,字体渲染清晰。我们可以轻松使用 CSS 实现圆角(
border-radius)、阴影(box-shadow)和透明度(opacity),视觉效果非常专业。跨平台一致性:浏览器确保了渲染的一致性,无论在哪种操作系统上运行都可以得到相同的效果。
数据传输量小:我们只需要传入元素
ref和坐标,浏览器内部完成所有标记绘制,然后返回一个轻量的结果对象。智能标签定位:我们实现了
findLabelPosition()函数,它会自动尝试元素的上、下、左、右、对角线等多个位置,检查是否与已有标签重叠,并自动选用最佳位置。这在浏览器端操作 DOM 来实现非常简单,但如果用 PIL 在 Python 做,则需要维护一个复杂的坐标记录系统,效率很低。
另一个细节是:在可见性检测时,我们将完全被遮挡的元素标记为 hidden状态,直接跳过绘制标签;部分可见的元素标记为 partial,使用虚线框和半透明标签。这使得 AI 能够区分哪些元素是真正可交互的。
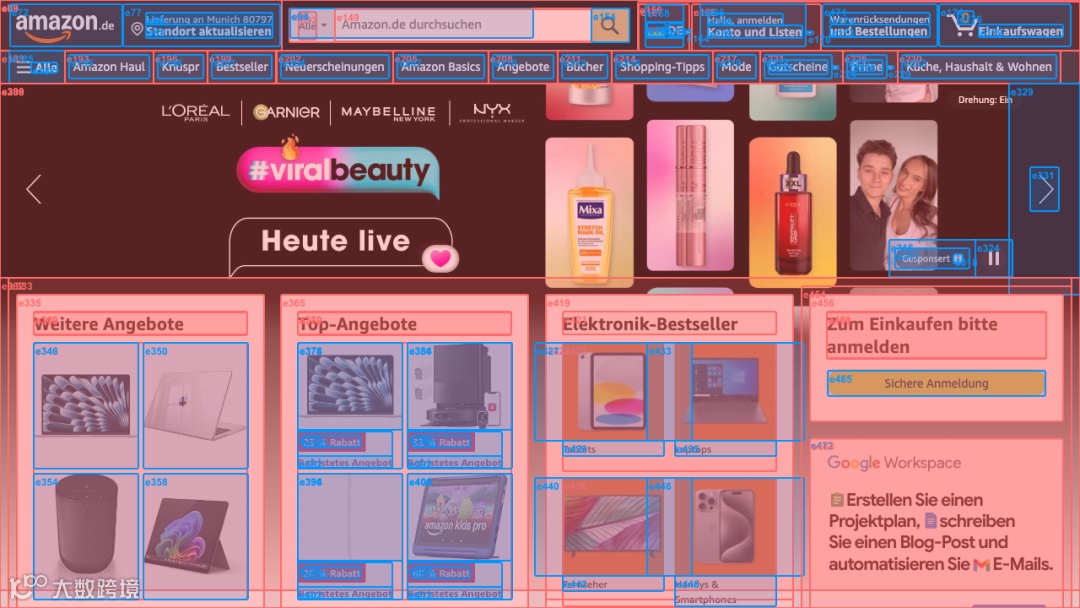
我们之前的 SoM 截图:
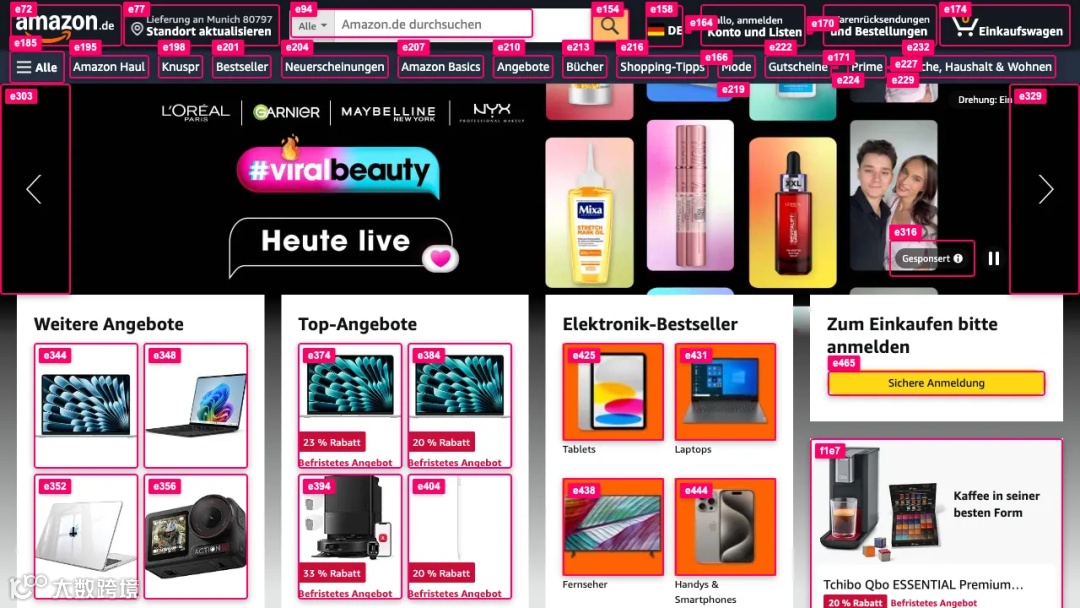
我们现在的 SoM 截图:
其他流行的开源 SoM 截图:

工具注册机制:避免“上下文爆炸”

早期版本有一个隐藏的性能问题:SoM 截图会被直接存入 AI 智能体的上下文(Context)中。如果智能体在任务中需要多次截图(例如浏览多个页面),上下文空间会迅速被占满,导致成本飙升或超出限制。
我们的解决方案是,要求 AI 智能体在调用 browser_get_som_screenshot工具时,将相关指令作为提示词(Prompt)写入。这样,智能体的上下文中只会保留对该截图的文字描述(例如“我获取了仪表盘的截图”),而图片本身并不会挤占上下文空间。
这个优化需要与 CAMEL 的 AI 智能体注册机制相配合。通过 RegisteredAgentToolkit基类,我们允许工具包(Toolkit)访问注册了它的 AI 智能体实例。具体来说,当 browser_get_som_screenshot被调用时,如果检测到已注册的 AI 智能体,它会自动调用该智能体的 astep()方法,并传入一个包含图片路径的 Message对象。AI 智能体内部再使用 PIL 加载图片,并将其传递给多模态 LLM 进行分析。
这种设计实现了清晰的职责分离:工具包负责生成截图,AI 智能体负责分析和理解。两者之间仅通过轻量级的文件路径接口进行通信。
表单填写优化:应对真实世界的复杂性

现实世界的网页表单远比想象的复杂。我们在测试中遇到了各种奇怪的场景,通过不断迭代,才优化出了当前的解决方案。
// 批量处理多个输入框
browser_type()时,只需传入一个字典(如 {ref1: text1, ref2: text2}),即可一次性完成所有填写。这避免了多次通信往返(其中可能夹杂着快照变化),并降低了因页面状态中途改变而导致失败的风险。
// 智能下拉菜单检测
有些输入框实际上是伪装的下拉菜单(例如,带自动补全的搜索框)。我们的 browser_type()实现中包含一个 shouldCheckDiff逻辑:如果输入框的 role属性包含 combobox、searchbox等,我们就认为它可能触发下拉菜单。此时,我们会在输入前后各捕获一次快照,然后计算差异(Diff),提取新出现的选项元素。这个 Diff 结果会返回给 AI 智能体,这样智能体就知道“现在有这些选项可以选择了”。
// 针对动态内容的快照差异 (Diff) 计算
这个功能由 getSnapshotDiff()实现。其原理是比较两次快照的文本内容,找出特定类型(如 option, menuitem)的新增元素。我们通过正则表达式匹配 [ref=...],记录第一个快照中的所有 ref,然后在第二个快照中找出所有新出现的 ref。这样 AI 就能看到“点击这个输入框后,出现了 5 个选项”。
// 对只读元素的特殊处理
日期选择器(Date Picker)通常是一个只读的(readonly)输入框,点击后会弹出一个日历组件。我们的 performType()函数会首先检查元素的 readonly属性及其 type(如 date, datetime-local, time等)。如果匹配上,它会先执行点击操作,等待 500 毫秒(等待日历弹出),然后在新增的元素中(通常通过 placeholder 文本来匹配)寻找那个真正可供输入的输入框。
// 嵌套输入框搜索
有些按钮在点击后,并不直接替换原有位置,而是在嵌套的子元素中出现。我们的策略是:如果在某个 ref上执行 fill()失败,就在它的子元素中搜索 input, textarea, [contenteditable]等,并尝试对找到的第一个子元素进行填写。这个搜索利用了 Playwright 强大的 locator()API,支持复杂的 CSS 选择器。
// 错误恢复机制
所有这些复杂逻辑都包裹在 try-catch 模块中。如果某一步策略失败了,我们会记录详细的错误信息(包括元素的 tagName, id, className, placeholder等调试信息),但不会直接抛出异常,而是继续尝试下一个备用策略。只有当所有策略都失败后,才返回一个描述性的错误信息给 AI 智能体。
这些优化都是在实际使用中逐步积累起来的。每当我们遇到一个 AI 智能体无法处理的表单,我们都会深入分析问题所在,然后进行针对性的改进。
未来计划
1. 优化页面快照(Page Snapshots)
高质量的快照是使用浏览器的智能体的效率基础。一份理想的快照应当具备高信噪比和低冗余度,即保留所有关键信息,同时滤除无关噪声。
目前的执行方案仍然会包含大量空的或通用的元素,并且对视口外元素的过滤也还不够精确。在某些情况下,不可见或不相关的节点仍会被捕获,导致不必要的数据和潜在的模型混淆。
我们未来的工作将集中于优化快照提取算法,确保只保留那些具有语义相关性和视觉重要性的元素,包括更精确的视口过滤、对非交互元素的层级聚合,以及增强关键 UI 组件的语义表示。我们的目标是创建一种更紧凑、信息密度更高的快照格式,以提升模型的理解效率和 token 利用率。
2. 支持纯视觉模型的评估环境
最近,一些模型提供商(如 Google)推出了纯视觉的、基于坐标的“计算机使用”模型(computer-use models,例如 Gemini 2.5 Computer Use)。这类模型能像人类一样,通过像素级的点击直接与图形用户界面(GUI)交互。在这种新范式下,执行 GUI 任务不再需要一个复杂的工程层来暴露元素级的交互 API,极大地降低了模型开发者实现 GUI 交互的门槛。
为了支持这种新范式,我们可以提供一个模拟和评估环境,其中模型预测的点击坐标可以与从快照派生的基准(ground-truth)元素位置进行验证。该框架将能够为纯视觉 GUI 智能体提供准确性评估和强化学习。这样的环境可以为基于视觉的“计算机使用”模型提供训练和基准测试所需的基础设施,为模型开发者减少大量工程开销。
3. 构建可靠的长期记忆范式
“浏览器使用”是 GUI 交互的一种特定形式,智能体通过一系列连续的动作和反馈在 Web 环境中执行任务。随着动作序列的增长,不断累积的中间反馈也带来了更加严峻的挑战,比如超出模型的上下文长度限制、降低历史信息的检索效率,以及增加关键信息丢失的风险。
这个问题在纯视觉模型上更为突出,因为视觉上下文(即截图)缺乏结构化的语义,难以被高效地索引或总结。因此,构建一个鲁棒的长期记忆范式至关重要。
在未来我们将结合语义摘要、分层缓存和自适应上下文重建等机制,努力探索如何高效地检索和压缩历史状态与反馈。我们的最终目标是使 AI 智能体能够在超长任务序列中保持情景感知和连续性,同时保留完整的行为可追溯性和任务连贯性。
致谢社区
以上所有的重构工作都是由真实的任务需求所驱动的。通过大量的测试以及与社区成员的紧密合作,我们才得以逐步构思并共同实现了这些优化。在 AI 智能体时代,浏览器使用是一个高度工程化、细节繁杂的领域,它只能通过丰富多样的真实场景测试来不断打磨和完善。在此,我们向社区中每一位贡献者表示衷心的感谢!🌟🐫
-
Eigent开源产品重磅发布!全球首个多智能体生产力团队来了! -
CAMEL-AI与Gemini正式官宣合作,用Gemini 2.5 Pro实现数据可视化和自动化 -
CAMEL-AI x MCP:一篇文章读懂如何让 AI 智能体玩转所有工具 -
自动化新时代:OWL、CRAB 与 MCP 如何打通“最后一公里” -
自动化新时代:OWL、CRAB 与 MCP 如何打通“最后一公里”
CAMEL微信群

加入CAMEL微信群,请添加CAMEL官方微信号CamelAIOrg,会有工作人员通过您的好友申请并邀请您加入我们的微信群~
Join CAMEL Community

www.camel-ai.org

https://github.com/camel-ai/camel

https://discord.camel-ai.org