![[体系结构] 谷歌TPU v4 @ 2023 ISCA](https://cdn.10100.com/user/3f152f638d66e78832d2aeeb86771102.png?x-oss-process=style/180x)
谷歌TPU v4论文将发表在2023年ISCA会议(Industrial Track)上,基本信息如下图所示。

链接: https://arxiv.org/ftp/arxiv/papers/2304/2304.01433.pdf
问题
对于体系架构学者来说,机器学习模型在规模和算法方面依然以具有挑战性的方式发展着,前者的例子是大语言模型(Large Language Model, LLM), 后者的例子是推荐系统(Deep Learning Recommedation Models, DLRMs)的嵌入(Embedding)以及Transformer和BERT的大量计算。近期LLM需要将机器学习超算扩展到4096个TPU v4节点,达到这样的规模会带来可靠性(Reliability)问题,而深度神经网络(Deep Neural Network, DNN)训练过程中HPC风格、检查点/恢复、一切必须工作的执行方式会加剧该问题。这种可靠性问题与主流Google分布式系统的典型软件可靠性相去甚远。
下表显示了谷歌在TPU上运行的模型类型变化,目前以DLRM和Transformer为主。

贡献
1)通过光电路交换机(Optical Circuit Switches, OCSes)来解决扩展性和可靠性问题,支持4096基点的超算重构来容忍1024个CPU主机0.1%到1%时间的不可用;
2)通过稀疏核心(SparseCore, SC)来硬件加速深度学习推荐模型中的嵌入(稀疏核心从TPU v2就是TPU的一部分);
3)嵌入添加了超算级互连的全部交换(All-to-All)通信模式, 结合光电路交换机的灵活拓扑配置,可实现更好的对分带宽(Bisection Bandwidth)特性。
1)和3)都是关于超算级互连方面的优化,此类研究少有涉及,故下文主要围绕稀疏核心展开,描述TPU v4对嵌入的领域特定架构(Domain Specific Architecture)。
方案
1)什么是嵌入?
嵌入是一种将分类特征值转换为密集向量的标准且有效的方法。嵌入函数从大的分类空间(如英语中的单词)转换为较小的密集空间(如代表每个单词的 100 维向量)。嵌入是谷歌深度学习推荐模型的一个关键成分,且一般作为神经网络模型的第一层使用。嵌入函数是使用查找表实现的,表的规模很大,从O(10MiB)到O(100GiB)。嵌入查找表操作主要由小批量的聚集(Gather)或分散(Scatter)存储访问构成,具有很低的计算强度。
2)影响嵌入性能的关键因素
嵌入查找表操作的性能瓶颈主要是存储带宽、存储容量、向量处理单元(Vector Processing Unit, VPU)性能,以及芯片间互连网络。
互连网络带宽和性能取决于并行方式。对于模型并行(常见情形),通信模式由变长全部交换交互组成,性能受限于网络对分带宽。对于数据并行,通信模式由全归约(All-Reduce)操作组成,限制了注入带宽。
此外,嵌入的非结构稀疏容易导致计算、存储、通信的负载不均衡。为了减少负载不均衡,通常使用频繁特征值的重复数据删除(Deduplication),并且必须由计算基板有效支持。重复数据删除还可以减少内存访问次数和通过互连网络发送的数据量,从而进一步提高性能。
3)为什么要设计稀疏核心?
嵌入可以在张量核心(TensorCore)或超算的主机CPU中执行。张量核心拥有宽向量处理单元VPU和矩阵单元,且面向密集操作优化。将嵌入放到张量核心执行是次优的,因为小批量的聚集/分散存储访问和变长的数据交互。将嵌入放到超算的主机CPU上执行,会在CPU DRAM接口上引起Amdahl定律,并被TPU v4和主机CPU的4:1比例放大。数据中心网络的尾部延迟和带宽限制将进一步限制训练系统。
性能可以通过使用一个TPU超算的所有HBM容量,结合专用的核间互连(Inter-Core Interconnect, ICI)网络,以及快速的聚集/分散存储访问来优化。这导致了稀疏核心的协同设计。
4)稀疏核心结构
稀疏核心是一个面向嵌入训练的领域特定架构,开始于TPU v2,随后在TPU v3和TPU v4优化。稀疏核心相对开销较小,仅占大约5%的芯片面积和大约5%的芯片功耗。超算的HBM和核间互连构建了一个扁平的、全局可访问的存储空间(128 TiB)。与密集训练时大规模参数张量的全归约模式,小批量嵌入向量的全部交换传输采用支持细粒度聚集/分散访问的HBM和核间互连实现。
稀疏核心采用数据流架构,因为数据从存储流向各种直连的专用计算单元。稀疏核心有16个计算块(图7中的深蓝色框),每个块有一个HBM 通道,并支持多个未完成(Outstanding)的内存访问。计算块由获取单元(Fetch Unit)、可编程8路SIMD向量处理单元(scVPU)和冲洗单元(Flush Unit)组成。获取单元从HBM中读取激活和参数,并存入计算块的2.5MiB稀疏向量存储(Spmem)中。冲洗单元将更新的参数写回到HBM中。五个跨通道的单元(图7中的金色框)执行专用嵌入操作,这些单元执行类似CISC的指令,操作在变长的输入上,每条指令的运行时间受数据决定。这些跨通道的单元共同操作在所有16个Spmem的阵列上。
论文原文并未对控制逻辑做细致描述,个人猜测稀疏核心序列器(SparseCore Sequencer)类似于CPU中的取指单元,然后通过派发器(Dispatch)将指令分发到目标单元。此外,图中显示的OCI,貌似是指HBM和ICI。

5)稀疏核心性能
由于小批量嵌入向量的全部交换传输,端到端嵌入查找性能基本上与对分带宽成正比。
端到端嵌入查找性能基本上与对分带宽成正比,这是由于小嵌入向量的全对全传输。原文提到,在1024个芯片规模时,稀疏核心开销开始占主导地位,而对分带宽不太重要。

图9显示了使用两代128芯片的TPU训练内部推荐模型DLRM0的性能。基准CPU配置为为576个Skylake Sockets,最下面两个是不使用TPU v4的稀疏核心,嵌入放在CPU存储中,其中Emb on CPU表示放在主机CPU存储中,Emb on Variable Server表示放在64个外部变量服务器中。当嵌入放置在 TPU v4 的 CPU 内存时,由于CPU内存带宽瓶颈,性能会下降 5–7 倍。(注:图8不太懂,但图9是比较清楚的,针对稀疏核心开展的消融实验)

6)平台感知的神经网络架构搜索
为了对DNN模型的质量和性能帕累托优化(Pareto-Optimization),开发了平台感知神经架构搜索(Platform-Aware Neural Architecture Search, PA-NAS),来自动化针对TPU v4超算定制DNN模型的过程。
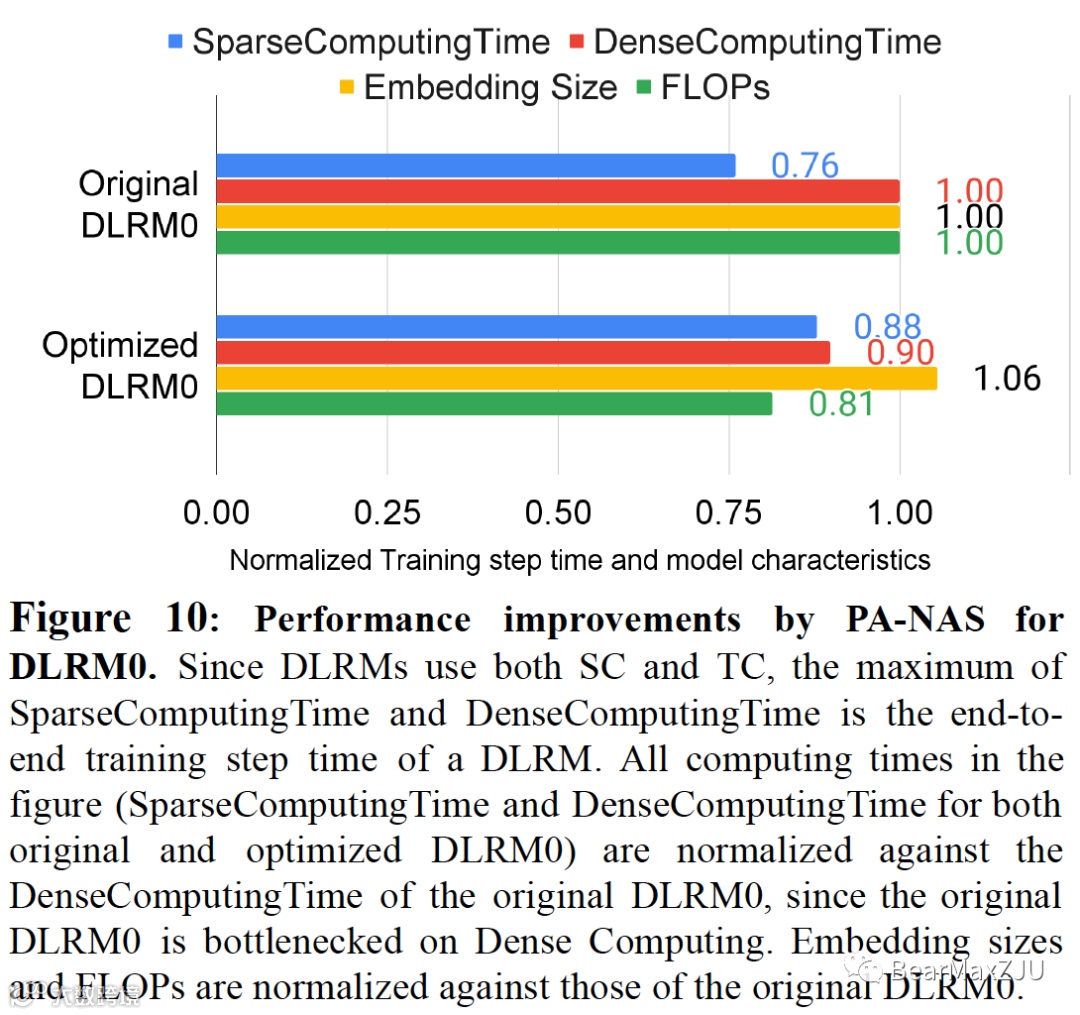
和CNN主要是用张量核心不同,DLRM同时使用稀疏核心和张量核心。PA-NAS可以移动稀疏层(运行在稀疏核心上)和密集层(运行在张量核心上)的计算负载来实现帕累托优化的性能和质量。图10显示了PA-NAS应用在内部DLRM模型上的效果,其中基准已经经过了手动优化和通用NAS的优化,但是稀疏核心和张量核心之间仍存在不小的负载不均衡。
7)硬件参数对比
相比于TPU v3 (16nm工艺),TPU v4 采用 7 nm 制造,具有两倍的矩阵乘法器(得益于提高的工艺密度)和 快11% 的时钟速度,这驱动了峰值性能的2.2倍增益。大约40%的能耗比来自工艺改进,其余来自设计改进(如平衡流水线、时钟门控)。


8)功耗对比
为什么A100的功耗会多30%-90%?
因为设计复杂,作者从定性的角度回答了这个问题,包括四个层面:1)TPU v4片上存储为160 MiB,而A100片上存储只有40MiB,更大的片上存储允许以更大的块与内存传输,可提高能效;2)A100采用多线程(Multithreading)并行方式,因此其寄存器堆高达27MiB,而TPU v4仅有0.25MiB,寄存器访问可能需要更多的能量;3)TPU v4采用128x128的MXU计算单元,意味着128个输入可复用128次,而A100的4x4 FP16阵列仅可复用4次,会导致更多的片上存储访问;4)A100面积大40%,可能有更长的数据传输路径,增加数据传输能耗。

总结
TPU v4的两大主要架构特性成本较小,但优势很大。
特性一:稀疏核心可加速DLRM模型的嵌入5到7倍,代价仅有5%左右的面积和功耗;
特性二:光电路交换机整体成本占比小于5%,整体功耗消耗占比小于3%,但可带来诸多优势:扩展性、改进的可用性、模块化等。