
摘要
大型语言模型(LLM)的推理过程包含两个关键阶段:预填充阶段(Prefill Phase)和解码阶段(Decoding Phase)。KV缓存(KV Cache)是连接这两个阶段、提升推理效率的核心技术。本文将从基本概念出发,深入解析LLM推理的工作流程,阐明KV缓存如何解决注意力计算中的冗余问题,并通过代码示例展示其具体实现。我们将探讨这一技术如何在不影响模型输出的前提下,显著加速文本生成过程。
目录
-
1. 引言:理解LLM推理流程 -
2. 核心问题:解码阶段的重复计算 -
3. KV缓存:消除冗余的解决方案 -
• 3.1 核心思想 -
• 3.2 工作原理 -
4. 预填充阶段:解码的准备工作 -
• 4.1 阶段定义与特点 -
• 4.2 与解码阶段的对比 -
5. 代码实现:KV缓存的存储与使用 -
• 5.1 向缓存追加数据 -
• 5.2 从缓存读取数据 -
6. 内存与计算复杂度分析 -
7. 实践要点与常见优化 -
8. 总结与展望
1. 引言:理解LLM推理流程
大型语言模型(LLM)的文本生成过程是一个自回归(Autoregressive) 的序列预测任务。整个过程可以类比为“填空游戏”:模型基于已有的文本序列,预测下一个最可能出现的词(或token),然后将预测结果追加到序列末尾,如此循环往复。
一次完整的推理(Inference)通常始于用户的提示(Prompt),例如“what is a LLM?”。下图概括了从输入到模型完成首次预测的基本流程:

这个流程可以分解为三个核心步骤:
-
1. 分词(Tokenization):将输入文本(即上下文+用户提示)转换为模型能理解的离散token序列。 -
2. 嵌入(Embedding):将每个token映射为一个高维稠密向量(例如,GPT-2中维度为768)。 -
3. 前向传播(Forward Pass):将嵌入序列输入Transformer块,通过自注意力(Self-Attention)等机制进行上下文编码(Contextualization),最终输出下一个token的预测分布。

2. 核心问题:解码阶段的重复计算
自回归生成的核心挑战在于效率。在标准的解码过程中,为了生成第 t 个token,模型需要将前 t-1 个token组成的完整序列重新输入网络进行计算。这就导致了严重的计算冗余。
问题的根源在于注意力机制(Attention Mechanism)。在每一轮解码中,注意力块都需要计算查询(Query)、键(Key)、值(Value)矩阵之间的缩放点积(Scaled Dot Product):

注:
实例化(Materialise)是一个技术术语,指的是需要为一个特定形状的张量(例如1000x1000,每个维度768)分配内存并进行计算。
考虑生成一个长度为 L 的序列。在无优化的情况下,总计算量大致与序列长度的平方(
)成正比,因为每次生成新token时,模型都需要重新处理所有历史token。对于长文本生成,这种计算开销变得难以承受。
3. KV缓存:消除冗余的解决方案
3.1 核心思想
KV缓存(KV Cache) 的关键在于洞察到自回归解码中的一个特性:在生成第 t 个token时,只有当前最新的token(即第 t-1 个token的预测结果)是“新”的输入,而所有历史token的表示在之前的步骤中已经计算过了。
更具体地说,在Transformer的自注意力层中,每个输入token通过线性变换独立地生成其对应的键(K)和值(V)向量。这些向量只依赖于该token自身的嵌入,而不依赖于序列中其他token的位置(位置信息由位置编码单独提供)。因此,一旦计算了某个token的K和V向量,只要该token的嵌入不变,这些向量就可以被缓存并复用于后续所有解码步骤。
3.2 工作原理
KV缓存机制巧妙地利用了这一点。其基本思路是:在每一解码步骤中,仅计算新输入token的K和V向量,并将它们追加到缓存中;在计算注意力时,则使用缓存中所有历史token的K和V向量与当前token的查询(Q)向量进行计算。
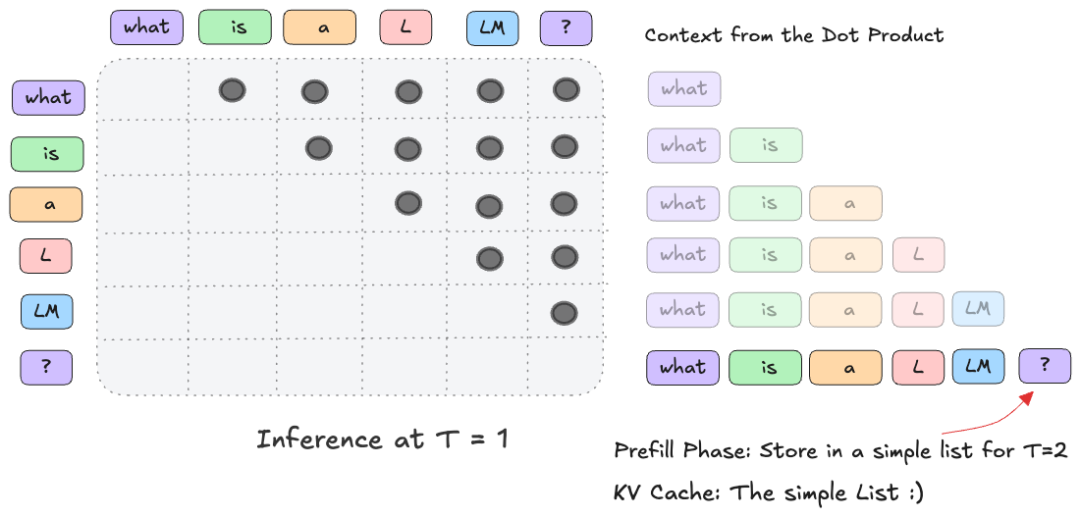
这个“缓存列表”通常是一个按层(Layer)和注意力头(Head)组织的张量队列。在实现上,它可以是动态增长的结构,也可以是预分配好固定大小的缓冲区。
通过引入KV缓存,解码阶段的总计算复杂度从 降低到了 ,因为每个token的K和V向量仅被计算一次。虽然内存占用从 增长到了 ,但在现代硬件上,用额外的内存换取显著的计算速度提升通常是划算的。
4. 预填充阶段:解码的准备工作
4.1 阶段定义与特点
在LLM推理中,预填充阶段(Prefill Phase) 特指处理初始用户提示的第一个推理步骤(即 T=1 的时刻)。

与后续的解码阶段(T>1)不同,预填充阶段具有以下特点:
Transformer本质上是一个序列到序列(Sequence-to-Sequence) 模型。在预填充阶段,当输入 N 个token时,模型会为这 N 个位置中的每一个都计算下一个token的预测。然而,在自回归生成任务中,我们通常只关心最后一个位置的预测结果(即基于整个提示的下一个token),而中间位置的输出会被丢弃。
4.2 与解码阶段的协同
预填充阶段是解码阶段的“准备工作”。它为后续所有解码步骤完成了两件关键事情:
-
1. 生成第一个输出token。 -
2. 计算并填充KV缓存,为后续的高效解码奠定基础。
从 T=2 开始,推理进入纯解码阶段。此时,模型进入一个循环:输入是上一轮预测出的单个token,利用已填充的KV缓存计算注意力,生成下一个token,并将新token的K和V向量追加到缓存中。
5. 代码实现:KV缓存的存储与使用
理解了原理后,我们来看一个高度简化的KV缓存实现伪代码。在实际框架(如Hugging Face Transformers)中,实现会更复杂,但核心逻辑一致。
5.1 向缓存追加数据
在每个Transformer层的自注意力模块中,当计算出当前步的 key_states 和 value_states 后,需要将它们追加到该层对应的缓存中。
# 假设 self.key_cache 和 self.value_cache 是预先初始化好的列表或张量,按层索引
# layer_idx: 当前层的索引
# key_states, value_states: 当前步计算出的键和值状态,形状通常为 (batch_size, num_heads, seq_len, head_dim)
# 将当前步的键值状态沿着序列长度维度(dim=-2)拼接到缓存中
self.key_cache[layer_idx] = torch.cat([self.key_cache[layer_idx], key_states], dim=-2)
self.value_cache[layer_idx] = torch.cat([self.value_cache[layer_idx], value_states], dim=-2)
关键点:
-
• torch.cat操作沿着序列维度拼接,使得缓存中保存了从第一步到当前步所有token的K和V向量。 -
• 缓存需要在每个解码步骤、每个Transformer层进行更新。
5.2 从缓存读取数据
在计算注意力时,我们需要使用完整的、缓存中的所有历史K/V向量,而不仅仅是当前步新计算出的。
# 假设 q_len 是当前查询向量的序列长度(解码阶段通常为1)
# 首先,将当前步的查询(query_states)和键(key_states)重塑为标准的注意力头格式
key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
# 如果KV缓存存在(即非预填充阶段或预填充阶段后)
if kv_cache is not None:
# 关键步骤:更新缓存,并获取用于当前注意力计算的完整键值状态
# `kv_cache.update` 内部执行了上述的拼接操作,并返回拼接后的完整缓存
key_states, value_states = kv_cache.update(key_states, value_states, self.layer_idx)
关键点:
-
• 在解码阶段, key_states和value_states经过kv_cache.update后,其序列长度维度会从1变为当前总步数。 -
• 随后进行的 QK^T计算,是当前步的单个查询向量与缓存中所有历史键向量的点积,从而实现了高效的上下文注意力计算。
6. 内存与计算复杂度分析
引入KV缓存带来了显著的效率提升,但也改变了资源消耗的模式。
解释:
-
• 计算复杂度: L是生成的序列总长度,d是模型维度。无缓存时,每次生成都需重新计算历史token的表示,导致平方复杂度。有缓存时,每个token的K/V只计算一次。 -
• 内存占用:缓存大小与序列长度 L、层数 、注意力头数 、每个头的维度 成正比。对于大模型和长上下文,这可能占用数GB甚至数十GB的GPU内存。 -
• 瓶颈转移:使用缓存后,计算不再是主要瓶颈。从缓存中读取大量K/V数据到计算核心的过程,其内存带宽成为关键限制因素。此外,过长的序列可能因缓存过大而耗尽GPU显存。
7. 实践要点与常见优化
在生产环境中部署带KV缓存的LLM推理时,需要考虑以下要点和优化策略:
-
1. 缓存初始化与清空: -
• 在开始一个新的生成任务前,必须清空(或重新初始化)KV缓存,防止不同会话间的信息污染。 -
• 在预填充阶段结束后,缓存应已包含提示词的所有K/V向量。 -
2. 内存管理策略: -
• 预分配(Pre-allocation):根据模型支持的最大上下文长度,预分配固定大小的缓存张量。这避免了动态拼接带来的内存碎片和分配开销,是高性能推理库(如vLLM, TensorRT-LLM)的常见做法。 -
• 分页注意力(Paged Attention):类似操作系统内存分页管理,将KV缓存划分为固定大小的“块”,按需分配和释放。这极大提高了显存利用率,支持更长的上下文和更高的并发。 -
• 量化(Quantization):将KV缓存中的浮点数(如FP16)转换为低精度格式(如INT8, INT4)。这能显著减少内存占用,但可能引入轻微精度损失,需谨慎校准。 -
3. 计算优化: -
• 融合内核(Fused Kernel):将注意力计算中涉及缓存读取、 、 、与 相乘等多个步骤融合到一个CUDA内核中执行,减少中间数据的读写,提升计算效率。 -
• 连续缓存(Continuous Cache):确保缓存张量在内存中是连续的,以利于硬件高效访问。 -
4. 长上下文处理: -
• 滑动窗口(Sliding Window):某些模型(如Mistral)的注意力本身具有滑动窗口限制,只关注最近的N个token。这自然限制了KV缓存的大小。 -
• 流式逐出(Streaming Eviction):当缓存达到上限时,采用特定策略(如淘汰最旧的token)逐出部分缓存,以容纳新token。
8. 总结与展望
KV缓存与预填充阶段是现代LLM高效推理不可或缺的组成部分。预填充阶段负责一次性、并行地处理初始提示,并为后续解码填充初始缓存;KV缓存则在解码阶段通过存储和重用历史注意力状态,将计算复杂度从平方级降至线性级,实现了量级上的速度提升。
这项技术的本质是用空间换时间。它成功地将推理瓶颈从计算转移到内存管理,从而催生了一系列围绕显存优化、内存带宽利用和高效内核设计的技术创新。
展望未来,随着模型规模持续增长和应用场景对长上下文、低延迟、高并发的要求不断提高,KV缓存技术将继续演进。例如,选择性缓存(只缓存重要的token)、更高效的压缩算法、以及与硬件协同设计的缓存架构,都将是重要的研究方向。深入理解KV缓存,是构建高性能LLM推理服务的基础。