
在当前的 AI 时代,所有技术工程师都对大语言模型(LLM)非常熟悉。这些 LLM 通过承担某些重复性任务,使我们能够更轻松地完成工作。作为 AI 工程师,这无疑提高了我们的产出。
然而,每当我们使用 LLM 时,都会消耗大量的标记(Token)。这些标记是我们与模型通信的“入场券”。在使用推理模型时,还会额外消耗作为推理环节的标记。不幸的是,这些标记的成本非常昂贵,这往往导致用户达到调用频率限制(Rate Limit)或遇到订阅付费的限制(Subscription Paywall)。
为了降低我们的标记使用量,从而降低总体成本,我们将探讨一种刚刚出现的新表示法:面向标记的对象表示法(Token-Orientated Object Notation,简称 TOON)。
什么是 JSON?
JavaScript 对象表示法(JSON)是一种轻量级的数据交换格式,它易于计算机解析和生成,也易于人类阅读和编写。它将数据表示为键值对、数组和嵌套结构,非常适合在系统之间(例如 Web 应用程序中的客户端和服务器之间)交换结构化数据。由于 JSON 是基于文本且独立于语言的,几乎所有编程语言都可以原生接受它。一个 JSON 格式的数据示例如下:
{
"name": "Hamzah",
"age": 22,
"skills": ["Gen AI", "CV", "NLP"],
"work": {
"organization": "Analytics Vidhya",
"role": "Data Scientist"
}}
什么是 TOON?
面向标记的对象表示法(Token-Oriented Object Notation, TOON) 是一种紧凑、人类可读的序列化格式,专为高效地向**大语言模型(LLM)**传递结构化数据而设计,同时显著减少标记用量。它是 JSON 的无损、即插即用的替代品,专门针对 LLM 输入进行了优化。
对于具有均匀对象数组(即每个项目都具有相同结构,例如表格中的行)的数据集,TOON 的表现尤其出色。它结合了 CSV 的表格紧凑性与 YAML 的基于缩进的可读性,创建了一种结构化且标记效率高的格式。需要注意的是,对于深度嵌套或不规则的数据,JSON 可能仍然是更好的表示形式,即使 TOON 在管理表格化或结构可靠的数据方面表现出色。
本质上,TOON 提供了 CSV 的紧凑性以及 JSON 的结构感知能力,有助于 LLM 更可靠地解析数据并进行推理。您可以将其视为一个翻译层:您可以使用 JSON 进行编程,然后将其转换为 TOON 以实现高效的 LLM 输入。
例如:
|
|
|
|
|---|---|---|
|
|
{"users": [{"id": 1, "name": "Alice", "role": "admin"}, {"id": 2, "name": "Bob", "role": "user"}]} |
|
|
|
users[2]{id,name,role}:1,Alice,admin2,Bob,user |
|
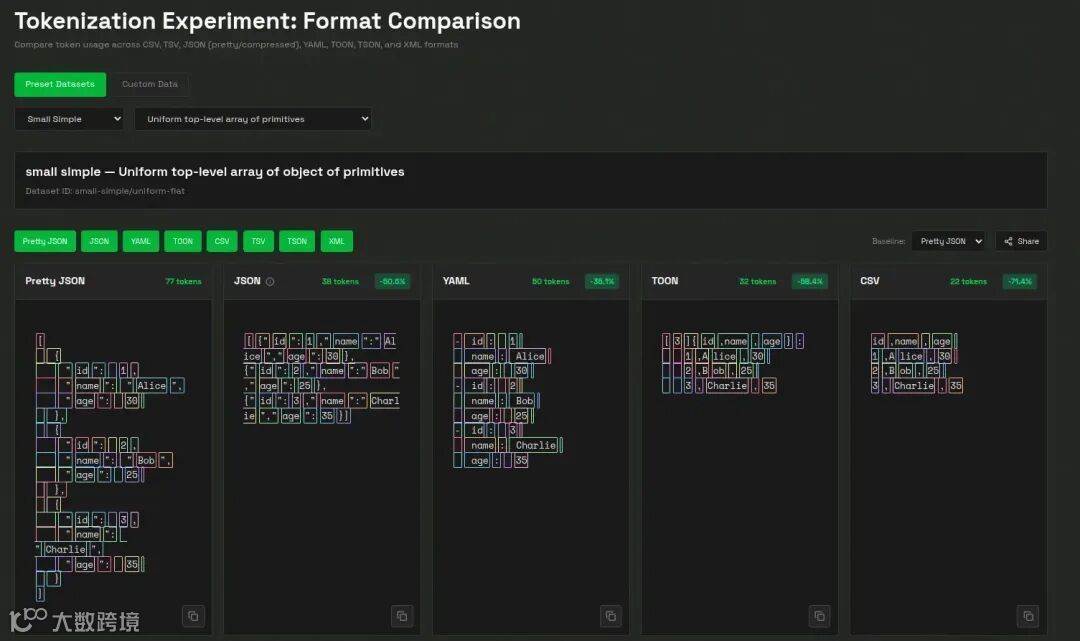
关键特性
-
标记效率高: 对于大型、均匀的数据集,比格式化的 JSON 减少 30% 至 60% 的标记,显著降低 LLM 输入成本。 -
LLM 友好的保护机制: 显式的字段名和声明的数组长度使模型更容易验证结构和保持一致性。 -
极简语法: 消除了冗余的标点符号,例如大括号、方括号和大多数引号,使格式保持轻量且可读。 -
基于缩进的结构: 与 YAML 类似,TOON 使用缩进而非嵌套大括号来表示层级结构,增强了清晰度。 -
表格化数组: 仅定义一次键,然后高效地流式传输数据行,非常适合具有一致模式的数据集。 -
可选的键折叠(Key Folding): 允许将嵌套的单键包装器折叠成点状路径(例如 data.metadata.items),进一步减少缩进和标记数量。
运行 TOON
目前,TOON 的实现涵盖了多种编程语言,并得到了官方和社区的共同支持。许多成熟的版本已经可用,同时仍有五个实现处于积极开发中,这表明其生态系统正在持续增长和扩展。正在开发的实现包括:.NET (toon_format)、Dart (toon)、Go (gotoon)、Python (toon_format) 和 Rust (toon_format)。
可以从 https://github.com/toon-format/toon-python/ 来查看 TOON 的安装和基本使用方式。接下来,我们将使用 toon-python 包来演示 TOON 的实现。
让我们运行一些基础代码,看看 toon-python 的主要功能:
安装
首先从安装开始:
!pip install git+https://github.com/toon-format/toon-python.git -q
TOON API 围绕两个主要功能展开:encode(编码)和 decode(解码)。
-
encode():将任何 JSON 可序列化的值转换为紧凑的 TOON 格式,自动处理嵌套对象、数组、日期和 BigInt,同时提供缩进和键折叠等可选控制。 -
decode():反转此过程,读取 TOON 文本并重建原始的 JavaScript 值,并提供严格的验证功能以捕获格式错误或不一致的结构。
TOON 还支持可自定义的分隔符,例如逗号、制表符(Tab)和竖线(Pipe)。这些分隔符影响数组行和表格数据的分离方式,允许用户优化可读性或标记效率。特别是制表符,由于其标记成本低廉且能最大限度地减少引号的使用,可以进一步减少标记用量。
可以 https://github.com/toon-format/toon-python 查看更多信息。
代码实现
下面我们来看一些代码实现。
Python 实现的主要导入函数来自toon_format。
1.estimate_savings + compare_formats + count_tokens
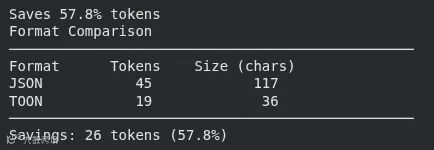
此代码块接受一个 Python 字典,将其转换为 JSON 和 TOON 两种格式,并计算每种格式将消耗的标记数量。然后,它打印出节省的标记百分比,展示格式的并排比较,并直接计算 TOON 字符串的标记数量。
from toon_format import estimate_savings, compare_formats, count_tokens
# 测量节省量
data = {
"users": [
{
"id": 1,
"name": "Alice"
},
{
"id": 2,
"name": "Bob"
}
]
}
result = estimate_savings(data)
print(f"Saves {result['savings_percent']:.1f}% tokens") # 节省 42.3% tokens
# 可视化比较
print(compare_formats(data))
# 直接计算 tokens
toon_str = encode(data)
tokens = count_tokens(toon_str) # 使用 tiktoken (gpt5/gpt5-mini)
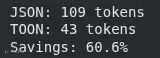
2. 对user_data使用estimate_savings
此部分测量用户的真实数据在 JSON 和 TOON 格式下分别会产生多少标记。它打印出两种格式的标记数量以及切换到 TOON 所实现的节省百分比。
from toon_format import estimate_savings
# 你的实际数据结构
user_data = {
"users": [
{"id": 1, "name": "Alice", "email": "alice@example.com", "active": True},
{"id": 2, "name": "Bob", "email": "bob@example.com", "active": True},
{"id": 3, "name": "Charlie", "email": "charlie@example.com", "active": False}
]
}
# 比较格式
result = estimate_savings(user_data)
print(f"JSON: {result['json_tokens']} tokens")
print(f"TOON: {result['toon_tokens']} tokens")
print(f"Savings: {result['savings_percent']:.1f}%")
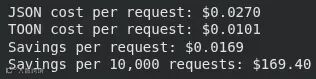
3. 使用 TOON 预估节省的费用
此代码块在一个更大的数据集(100 个项目)上运行标记节省计算,然后应用 GPT-5 的定价来计算每种请求格式(JSON vs. TOON)的成本。它打印出每次请求的成本差异以及预估 10,000 次请求的总节省金额。
from toon_format import estimate_savings
# 你的典型提示数据
prompt_data = {
"context": [
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Analyze this data"}
],
"data": [
{"id": i, "value": f"Item {i}", "score": i * 10}
for i in range(1, 101) # 100 个项目
]
}
result = estimate_savings(prompt_data["data"])
# GPT-5 定价(示例:每 1K tokens 0.01 美元)
cost_per_1k = 0.01
json_cost = (result['json_tokens'] / 1000) * cost_per_1k
toon_cost = (result['toon_tokens'] / 1000) * cost_per_1k
print(f"JSON cost per request: ${json_cost:.4f}")
print(f"TOON cost per request: ${toon_cost:.4f}")
print(f"Savings per request: ${json_cost - toon_cost:.4f}")
print(f"Savings per 10,000 requests: ${(json_cost - toon_cost) * 10000:.2f}")
何时避免使用 TOON?
尽管 TOON 在均匀对象数组方面表现优异,但在某些场景下,其他数据格式可能更高效或更实用:
-
深层嵌套或非均匀结构: 当数据具有许多嵌套层级或字段不一致时(表格适用性 ≈ 0%),紧凑的 JSON 实际上可能使用更少的标记。这在复杂的配置文件或分层元数据中很常见。 -
半均匀数组(~40%–60% 表格适用性): 随着结构一致性的降低,标记节省量也会变得不那么显著。如果您的现有数据管道已经围绕 JSON 构建,坚持使用 JSON 可能更方便。 -
纯表格式数据: 对于扁平的数据集,CSV 仍然是最紧凑的格式。TOON 会引入一小部分开销(约 5%–10%)来包含字段标题和数组声明等结构元素,虽然这提高了 LLM 的可靠性,但会略微增加大小。 -
对延迟要求严格的应用: 在端到端响应时间是首要任务的设置中,在做决定之前应对 TOON 和 JSON 进行基准测试。某些部署,尤其是使用本地或量化模型(例如 Ollama)时,处理紧凑的 JSON 可能会更快,尽管 TOON 节省了标记。务必比较两种格式的 TTFT(首个标记生成时间)、每秒标记数和总处理时间。
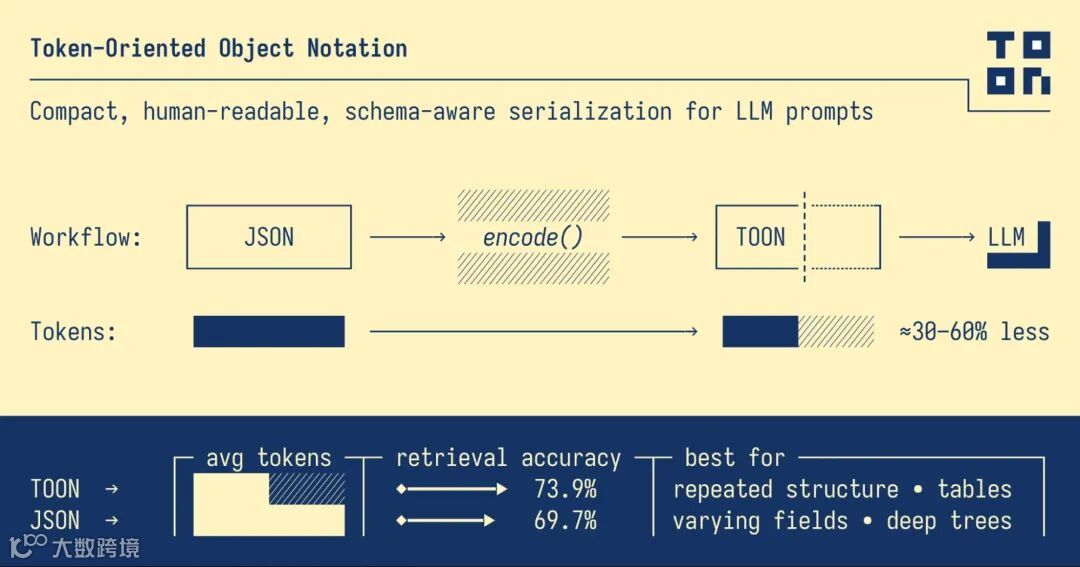
通过为 JSON 等传统格式提供一种有组织、紧凑且标记效率极高的替代品,TOON 标志着我们为 LLM 准备数据的方式发生了重大变化。随着越来越多的开发人员依赖 LLM 进行自动化、分析和应用程序工作流,标记用量的减少会立即带来更低的运营费用,特别是对于通过 API 积分按标记付费的用户而言。
TOON 通过使数据更具可预测性,并更易于模型消化,提高了提取的准确性,降低了歧义性,并提升了模型在各种数据集上的可靠性。
像 TOON 这样的格式有潜力彻底改变未来 LLM 处理结构化数据的方式。随着 AI 系统进步到处理更大、更复杂的上下文,高效的表示法在管理成本、延迟和性能方面将变得越来越重要。有了能够降低标记用量而又不损害结构的工具,开发人员将能够创建更丰富的应用程序,更有效地扩展其工作负载,并提供更快、更准确的结果。TOON 不仅仅是一种新的数据格式。它是迈向一个所有人都能够更智能、更经济、更高效地与 LLM 交互的时代的重要一步。