
随着LLM能力的提升和面向LLM的强化学习算法的成熟,最近一段时间的AI论文,特别是关于智能体学习与训练方向的工作,呈现一种趋同的思路:在一个LLM基座模型上,通过强化学习进行能力的内化与强化。
在这个基础框架上,论文的主要贡献点可能在以下几个方面:
-合成高质量数据,以支撑RL所需的大规模交互经验,使模型能够在多样化任务和验证器约束下持续学习;
-优化强化学习算法,通过改进信用分配、过程奖励或混合离线/在线训练策略,提高训练稳定性与样本效率;
-设计更有效的奖励函数,在结果难以直接验证的复杂推理或交互任务中,设计更精巧的奖励函数,例如探索结果奖励与过程奖励的权衡,或引入辅助奖励来约束行为;
-构建模拟环境与评测基准,为模型提供可交互、可验证、可复现的训练场景,设计能够真实反映并能持续提升智能体能力的评估任务。
这些贡献都和任务的设计有关,无论是数据的来源、算法的适用场景、奖励的定义,还是训练与评估的环境。
这正是LLM + RL + Task这个公式的由来。其中Task不仅指最终的目标,而是代表了一个可交互的学习世界,包括智能体所处的环境、可用的工具集、交互规则以及定义成功与否的奖励信号。
下面,结合最近整理的综述来进一步讨论这个公式。

项目地址:
https://github.com/ADaM-BJTU/model-native-agentic-ai
1. 模型原生的智能体构建:能力和应用
综述回顾了智能体的三种核心能力-规划(Planning)、工具使用(Tool Use)与记忆(Memory),以及两类典型应用-深度研究智能体(Deep Research Agent)与图形界面智能体(GUI Agent),从“流水线式(Pipeline-based)”到“模型原生(Model-native)”的演变趋势。
规划
流水线范式中,规划依赖外部组件,如符号规划器(PDDL)
模型原生的规划主要通过两条路径实现:一是监督学习(SFT),即模仿高质量的推理轨迹数据
工具使用
流水线范式最初是单轮的Functional call,后续发展为以ReAct为代表的多轮框架,通过提示词引导模型在外部“think-action-observation”循环中执行推理和工具调用。
模型原生的工具使用将何时、如何调用工具的决策能力内化为模型自身的策略,通过模块化训练或端到端RL进行优化。代表工作是OpenAI o3, K2,让模型自主学习工具使用,并重点解决“信用分配”和“环境噪声”等问题。
记忆
短期记忆方面,早期通过外部RAG或摘要弥补上下文长度的不足,随着基于RL的数据合成的发展,Gemini-2.5 pro、Qwen-2.5-1M等扩展了原生上下文的长度。
在长上下文让“记得住”之外,短期记忆解决的另一个问题是是“用得好”—即上下文管理,从记得住的内容中主动筛选对于执行当前任务有益的部分。这个领域也在从流水线式的上下文重排和动态检索,向模型原生的上下文管理发展,即将上下文管理内化为模型的一种行为进行训练和增强。
长期记忆方面,记忆管理的方法和短期记忆类似。它的模型原生的趋势体现在记忆的载体上:除了外部文档/向量数据库/知识库的显式记忆,MemoryLLM等工作尝试实现基于模型参数的隐式记忆存储和更新。
深度研究智能体
智能体核心能力构建范式的发展也影响了智能体应用的构建范式,包括深度研究智能体,和GUI智能体。
深度研究智能体扮演“大脑”的角色,擅长复杂推理与分析,适用于知识密集型任务。其起源于AI搜索,最初通过流水线方式整合检索、生成与总结模块。Google率先提出“深度研究”的概念,将AI搜索扩展为多轮、迭代式的信息探究过程,但仍依赖外部模块的精细编排。
OpenAI基于o3模型微调的Deep Research Agent首次实现了端到端的研究规划学习,能够自主决定研究路径与信息组织方式,在一致性与探索深度上显著超越流水线系统。
这个方向面临的主要挑战是:1)信息噪声与事实幻觉-在开放环境中保证事实可靠性与防止幻觉累积;(2)奖励定义困难-研究报告等开放任务缺乏客观指标,需要设计能衡量洞察与分析深度的高层次奖励模型。
GUI智能体
GUI智能体扮演“眼睛和手”的角色,模拟人类与图形用户界面的交互,适用于操作密集型的任务。其早期的流水线范式依赖外部工作流来编排大模型,例如AppAgent通过解析界面XML结构、Mobile-Agent调用OCR等专用感知工具来完成操作。
这几个月来的趋势也转向了模型原生范式,致力于将感知、规划和动作执行能力全部内化到一个统一模型中。从早期主要基于监督学习训练的UI-TARS,到近期采用强化学习的GUI-Owl和OpenCUA,模型原生智能体摆脱了外部脚本的束缚,鲁棒性和适应性更强。
2. 算法驱动力:强化学习
推动智能体的核心能力和应用从流水线范式向模型原生范式转变的主要驱动力,是强化学习、特别是大规模强化学习在 LLM 训练中的成功应用。

AI领域几十年的发展,一直在重复一个规律:从依赖“外部人工设计”转向“内部数据驱动学习”
知识获取的内化,由人工构建的规则系统转为模型自动学习知识;
特征表示的内化,由人工设计特征转为深度网络端到端自动提取;
目标函数的内化,从依赖外部显式标签的监督学习转向强化学习中通过与环境交互自我探索最优策略。
而这一次智能体能力和应用从流水线到模型原生的内化,除了契合了这一规律,也是此前三次内化、特别是最近一次目标函数转向强化学习的动态探索后的结果。下面我们分几个方面来分析。

必要性:过程标注的缺失
监督微调需要详细的、一步步如何完成任务的过程标注数据
可行性:传统RL vs. 基于LLM的RL
经典强化学习通常在低维、封闭的环境中进行,要求状态、动作和奖励都是明确的;而LLM所处的语言环境是开放且高维的,交互形式是自然语言。
基于预训练后的大语言模型进行RL,有两个优势。一是探索效率:LLM拥有预训练带来的丰富世界知识,这为RL提供了一个强大的起点,“探索”从物理行动转化为语言推理与对话过程,比从零开始的随机搜索更高效;二是任务泛化性:语言充当了通用接口,使得状态、动作甚至奖励都能用语言或语义token表示。这让RL训练的LLM智能体可以实现一定程度的任务泛化。

基础LLM提供了世界知识先验,RL算法则提供了学习机制,当两者结合并应用于特定任务环境时,就形成了这种统一的智能体训练范式:LLM(基座模型)+ RL(学习算法)+ Task(任务环境与奖励信号)。
这个统一的方法论对应了最近广泛讨论的“AI的下半场”。它其实说的是研究范式从“为问题找方法”转变为“用统一方法(LLM+RL)挑战更难的任务”:这些任务一方面可以评估模型在真实场景中的表现,另一方面可以基于这些任务来持续提升模型能力。

数据合成的视角
近几十年AI发展的一条暗线是将算力以最高的效率转化为智能。早期通过改进模型架构实现,近期则转向以数据为中心:先是通过自监督学习利用海量网络文本进行预训练,接着通过强化学习进行后训练。
RL在后训练阶段本质上合成了两类数据:一是“外推知识”,指模型通过内部推理生成的、预训练语料中不存在的程序化知识,如数学解题步骤

3. 未来展望
新兴的模型原生智能体能力
基于LLM+RL+Task的统一方法论,除了规划、工具使用和记忆,更多智能体能力也将转向模型原生模式。
根据模型原生化程度和实现难度,智能体能力的内化路径可分为三类:
- 可快速实现:难度较低,任务边界清晰,如输出格式化、自动化验证,短期内有望完全模型原生化。
- 近期核心焦点:难度中等,是当前研究热点且已有进展,如多智能体协作、反思与自我修正,未来1-2年有突破潜力 。
- 长期挑战:难度高,涉及安全/对齐、奖励建模等基础问题,需要长期探索和理论突破

系统层的定位变化
虽然学术界对“模型原生智能体”保持乐观,期望智能完全由模型内部驱动;而更关注工程可落地的产业界有一种普遍观点:现实中的Agent系统仍是“90%的工程、10%的智能”。
这反映了技术落地初期的现实,是很多颠覆性技术早期的必经阶段。如互联网从静态网页到智能服务的演进:从纯工程的静态页面,到工程为主、智能为辅的动态交互,再到工程标准化、AI 驱动个性化成为核心价值的阶段。
这预示着Agent领域工程占主导的阶段也是过渡性的:
流水线设计阶段(约2023–2025):LLM被视为工具组件,由人工逻辑控制。
模型原生转型阶段(约2025–2027):模型逐渐成为核心驱动力,承担规划、工具使用和记忆等主要功能,工程框架(如LangChain、AutoGen、AgentCore)作为中间层起桥梁作用。
自主演化阶段(2027以后):系统工程趋于标准化(AgentOps),智能体具备自我任务发现、动态软件生成甚至架构自演化等能力.

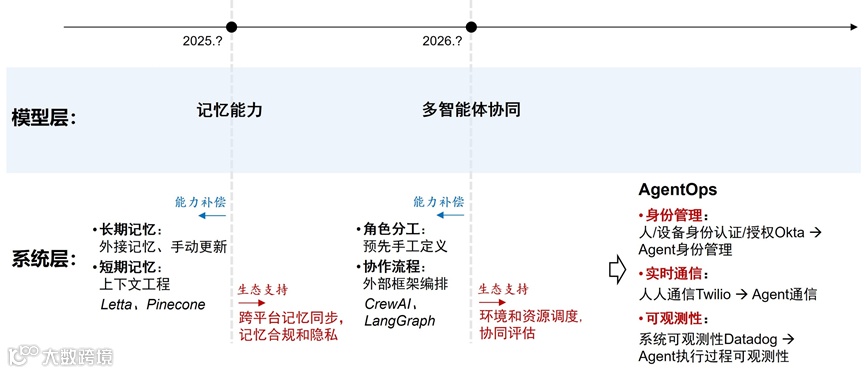
随着模型能力的增强,系统层的角色将从“补偿能力”转变为“支持生态”的基础设施。最近几年大模型的发展,也在重复着这一模式:
对话能力增强 (ChatGPT):系统层定位从原来补偿传统对话系统的能力,转变为支撑外部数据接入、上下文管理的生态
推理能力增强 (o1):系统层定位从原来补偿提示词编排的能力,转变为支撑强化微调、评估监督的生态
工具使用能力增强 (o3):系统层定位从原来补偿工作流编排的能力,转变为支撑MCP 工具转换、Server 集成的生态

接下来,我们可能会看到
记忆能力增强:系统层定位从原来补偿外接记忆、上下文工程的能力 (如 Letta, Pinecone),转变为支撑跨平台记忆同步、记忆合规和隐私的生态
多智能体协同能力增强:系统层定位从原来补偿预先手工定义角色分工、外部框架编排协作流程的能力 (如 CrewAI, LangGraph),转变为支撑环境和资源调度、协同评估的生态
AgentOps: 随着模型层能力普遍增强,系统层会演变为提供AgentOps基础设施,专注于支撑身份管理、实时通信、可观测性等生态能力。
从“流水线”到“模型原生”的范式转变,意味着正从“使用智能的系统 (systems that use intelligence)”迈向“可以自主生长智能的系统 (systems that grow intelligence)”:让智能体在与环境交互和完成任务的经验中学习、协作和进化。