
北京时间2025年11月18日晚,全球知名网络基础设施服务商 Cloudflare 发生了一起重大故障。
导致包括 ChatGPT、X(推特)、Spotify等在内的众多知名互联网服务在全球范围内无法访问。
业内人士称,“本次事件在互联网灾难史上,绝对可以单独摘出来写一篇传记了。”
事件梳理
基于Cloudflare官方发布的博客以及各方报道,以下是本次事故的详细梳理情况:
发生时间:2025年11月18日19:20 - 22:30(主要影响时段)。
持续时长:核心故障持续约3小时,完全恢复正常耗时约6小时。
影响范围:全球性。
根本原因:非网络攻击。系内部数据库权限变更导致的一个“潜伏Bug”被触发,引发机器人管理(Bot Management)配置文件体积异常膨胀,导致全球节点软件崩溃。
具体时间线:
19:05:Cloudflare工程师部署了一项关于ClickHouse数据库访问控制的变更。
19:28:变更生效,故障开始。
19:32-21:05:Cloudflare团队介入调查。
21:05:实施第一阶段缓解,但核心问题仍存在。
21:37:找到原因。
22:24:停止生成新的异常配置文件,并强制节点回滚到旧版正常文件。
22:30:核心服务恢复。
次日01:06:所有系统完全恢复正常。

此次中断引发连锁反应,全球近半数互联网服务受到影响,包括社交媒体、人工智能平台、在线工具及游戏服务等大量网站出现访问错误或加载失败。
比如AI圈的ChatGPT, Claude, Perplexity等,社交圈的X (Twitter), Spotify, Discord, Grindr等,游戏圈的英雄联盟, Minecraft服务器等。
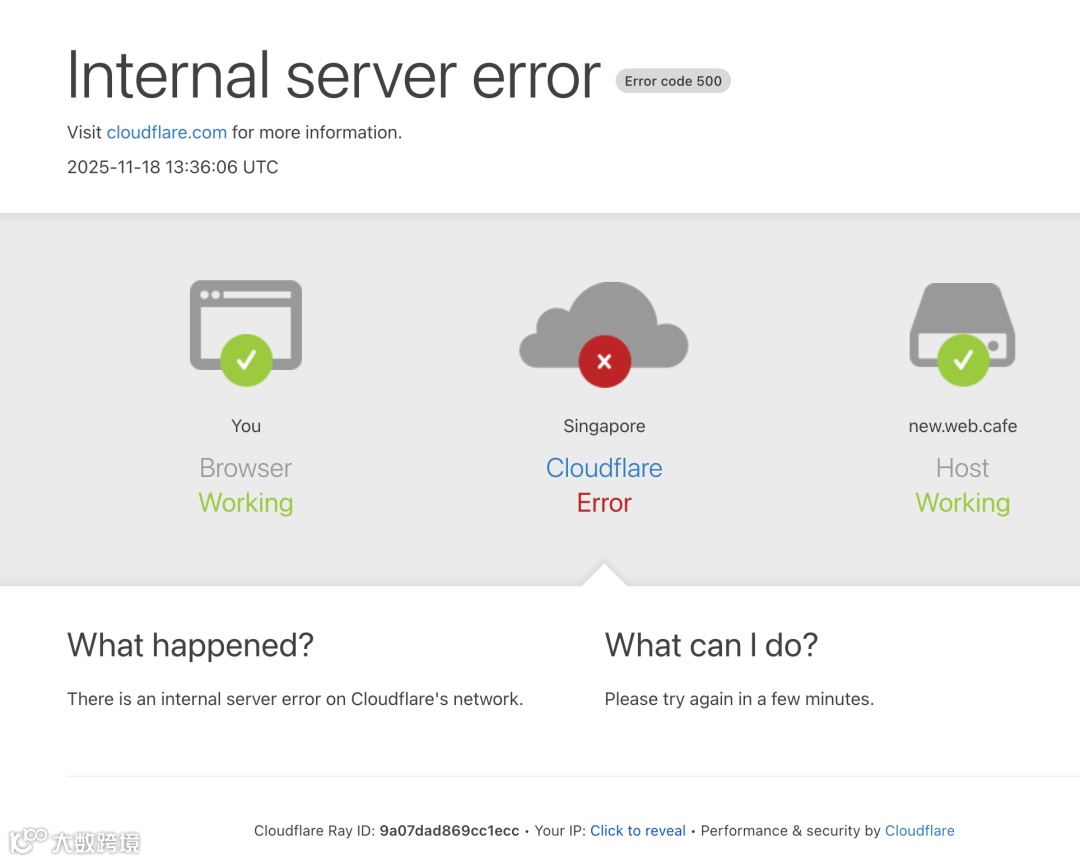
上述网站及应用在用户访问时,均出现500错误、"Internal Server Error"提示,或卡在"正在验证您是否是人类"的验证页面。
官方披露:宕机的深层原因
Cloudflare已对本次故障事件发布了报告,详细报告请见:https://blog.cloudflare.com/18-november-2025-outage/

以下是结合官方详细报告对本次故障事件的解读:
Cloudflare 运营着全球约20%网站所依赖的内容分发网络(CDN)。该平台通过创建网站内容的多个副本,并将其分布在全球各地的数据中心来运作。当用户访问网页时,Cloudflare 会从距离用户最近的数据中心加载内容。该公司表示,这种架构能为全球 95% 的人口提供 50 毫秒或更低的延迟。
除了提升网站速度,Cloudflare 的平台还有其他用途。将流量处理任务卸载到 CDN 可减轻网站运营商的服务器负载,进而提高运营效率。此外,Cloudflare 还提供网络安全功能,能够过滤恶意机器人程序及其他威胁。
关于造成流量激增的原因,当晚,Cloudflare 首席技术官 Dane Knecht 在 X 平台的帖子中透露,此次宕机由公司的恶意机器人流量过滤功能引发,并非攻击所致。这位高管强调,“我们的机器人防护功能所依赖的一项服务中存在潜在漏洞,在一次常规配置变更后开始崩溃,进而导致我们的网络及其他服务大范围出现性能下降。”
同时,Cloudflare 发言人也向外媒提供了更详细的最新进展。据称,“此次宕机的根本原因是一个自动生成的威胁流量管理配置文件。该文件的条目数量超出预期规模,引发了为 Cloudflare 多项服务处理流量的软件系统崩溃。”发言人表示,“需要明确的是,目前没有证据表明这是攻击行为或恶意活动导致的。我们预计,事件结束后流量会自然激增,部分 Cloudflare 服务可能会出现短暂性能下降,但所有服务将在未来几小时内恢复正常。”
在后续发布的博客中,Cloudflare 进一步解释了出现故障的完整经过、受影响系统和处理流程。据称,“问题是由于我们数据库系统的一项权限更改触发的,该更改导致数据库向一个由 Bot 管理系统使用的功能文件中输出了多个条目。该功能文件的大小随后翻倍。预期之外的大功能文件随后被传播到构成我们网络的全部机器上。这些设备上运行的网络流量路由软件会读取这份特征文件,确保机器人管理系统能及时应对不断变化的威胁。该软件对特征文件的大小设有限制,而此次文件大小翻倍后超出了这一限制,导致软件故障。”
具体来说,“机器人管理”模块正是此次宕机的根源。据介绍,Cloudflare 的机器人管理模块包含多个系统,其中一款机器学习模型会为流经其网络的每一项请求生成机器人评分。客户借助这些评分决定是否允许特定机器人访问其网站。该模型的输入数据是一份“特征”配置文件,这份特征文件每几分钟更新一次,并同步至整个网络,使其能够应对互联网流量的变化。
而正是底层 ClickHouse 查询行为的一项变更,导致生成的文件中出现大量重复的 “特征” 行。这一变化改变了此前固定大小的特征配置文件的尺寸,引发机器人模块触发错误。结果是,负责为客户处理流量的核心代理系统,向所有依赖该机器人模块的流量返回了 HTTP 5xx 错误码。这一问题还影响了依赖核心代理的 Workers KV 和 Access 服务。
其做出的变更是,让所有用户都能获取其有权访问的表的准确元数据。但问题在于,他们过去的代码中存在一个预设前提:此类查询返回的列列表只会包含 default 数据库的内容,该查询不会对数据库名进行过滤。随着他们逐步向目标 ClickHouse 集群的用户推出这一显式权限,上述查询开始返回列的 “重复项”,这些重复项来自存储在 r0 数据库中的底层表。不巧的是,机器人管理模块的特征文件生成逻辑,正是通过这类查询来构建本节开头提到的文件中的每个输入 “特征”。
由于用户获得了额外权限,查询响应现在包含了 r0 数据库模式的所有元数据,导致响应行数增加了一倍多,最终影响了输出文件中的行数(即特征数量)。起初,他们还误判观察到的症状是由超大规模分布式拒绝服务(DDoS)攻击引发,但随后准确识别出核心问题,成功阻止了这份超出预期大小的特征文件继续传播,并替换为早期版本。
补救和后续步骤
Cloudflare官方表示:
现在系统已恢复正常运行,此次发生的故障是 Cloudflare自 2019 年以来最严重的。我们之前也遇到过导致控制面板无法访问的故障,也曾出现过导致一些新功能暂时无法使用的情况。但在过去的六年多时间里,我们从未遇到过像今天这样导致大部分核心流量停止通过我们网络的故障。
像今天这样的故障是不可接受的。我们的系统架构设计使其具有极高的故障容错能力,以确保流量始终畅通无阻。过去每次发生故障,我们都会着手构建新的、更具容错性的系统。
据悉,Cloudflare暂未公布赔付计划。
但是在其官网的对Business和Enterprise计划客户提供SLA(服务水平协议)信用补偿:如果可用性低于99.9%,可获部分月费退款(本次约4.5小时中断,预计10-20%信用)。
现阶段推特已经开启收集故障期间付费用户的赔付申请了。

对此,你怎么看?是否有在该重大故障中受到影响?欢迎评论区讨论~
参考资料
-
昨晚,Cloudflare全球故障,搞瘫了半个互联网!
https://mp.weixin.qq.com/s/XmM9pjejZcMfH3gtO5DyZg?scene=1&click_id=30
-
Cloudflare酿六年最惨宕机:一行Rust代码,全球一半流量瘫痪!ChatGPT、Claude集体失联
https://mp.weixin.qq.com/s/Lx2BiBiQPgsA5gbpJlNl3Q?scene=1
Cloudflare outage on November 18, 2025
https://blog.cloudflare.com/18-november-2025-outage/
如喜欢本文,请点击右上角,把文章分享到朋友圈
如有想了解学习的技术点,请留言给若飞安排分享
因公众号更改推送规则,请点“在看”并加“星标”第一时间获取精彩技术分享
·END·
相关阅读:
-
一张图看懂微服务架构路线
-
基于Spring Cloud的微服务架构分析 -
微服务等于Spring Cloud?了解微服务架构和框架
-
如何构建基于 DDD 领域驱动的微服务? -
微服务架构实施原理详解
-
微服务的简介和技术栈 -
微服务场景下的数据一致性解决方案 -
设计一个容错的微服务架构 整理来源:扩展迷AIGC、infoQ、dbaplus社群
版权申明:内容来源网络,仅供学习研究,版权归原创者所有。如有侵权烦请告知,我们会立即删除并表示歉意。谢谢!
架构师 我们都是架构师!

关注架构师(JiaGouX),添加“星标”
获取每天技术干货,一起成为牛逼架构师
技术群请加若飞:1321113940 进架构师群
投稿、合作、版权等邮箱:admin@137x.com