SQL Server 2025正式发布,微软用全新Logo宣告数据库进入“AI时代”。阿里云RDS SQL Server紧随其后,成为国内首家支持该版本的云厂商!本文从一线用户视角出发,深度解析SQL Server 2025的五大核心升级的同时,结合阿里云数据库的云原生和企业级能力,解读SQL Server 2025版如何赋能企业实现“数据即智能”。
欢迎点击文末「阅读原文」申请免费试用 RDS SQL Server 2025版 1个月(新老用户同享)
阿里云RDS SQL Server 2025正式上线:国内首家支持,开启AI数据库新时代
在数字化转型与大模型技术爆发的双重驱动下,数据库不再只是“存数据”的工具,而是企业智能化的核心引擎。阿里云RDS SQL Server 2025的发布,标志着我们率先将SQL Server 2025的创新特性融入云原生架构,为企业提供开箱即用的AI能力、极致开发体验与高可用架构。
-
国内首家支持:紧随微软步伐,率先完成技术适配与云化改造,保障企业无缝迁移。
-
云原生深度优化:存算分离,释放SQL Server 2025的性能潜能。
-
一键升级能力:低版本RDS SQL Server实例支持一键完成2025大版本升级。
-
全面托管服务:提供数据库管理、备份恢复、高可用容灾、监控告警、深度诊断等全链路解决方案,简化数据库运维成本。
SQL Server 2025 核心升级解读:AI-Ready Enterprise Database
SQL Server 2025版的重点改进,主要集中在以下5个方面:
1、AI 内置能力:原生向量数据类型、DiskANN 向量索引,及与外部模型服务的集成,通过实际 RAG 案例看 SQL Server 如何把 AI 向量检索和模型调用收拢进数据库。
2、开发体验增强:原生二进制 JSON 类型及函数、聚合操作,以及基于 Google RE2 的正则表达式支持,如何改进数据建模、清洗和日志解析的体验。
3、内核深度优化:锁机制升级(消除锁升级、LAQ)、参数化查询优化(OPTIMIZED_SP_EXECUTESQL、OPPO、CE Feedback)、列存索引和 TempDB 改进等,提高数据库并发和性能。
4、版本与规格演进:标准版资源上限提升、Web 版下线,这些变化在阿里云 RDS SQL Server 产品规格和一键升级上的体现。
5、运维与分析提升:备份压缩算法升级、辅助节点备份支持、直接读取 OSS/S3 上 Parquet/文本数据等实用特性。
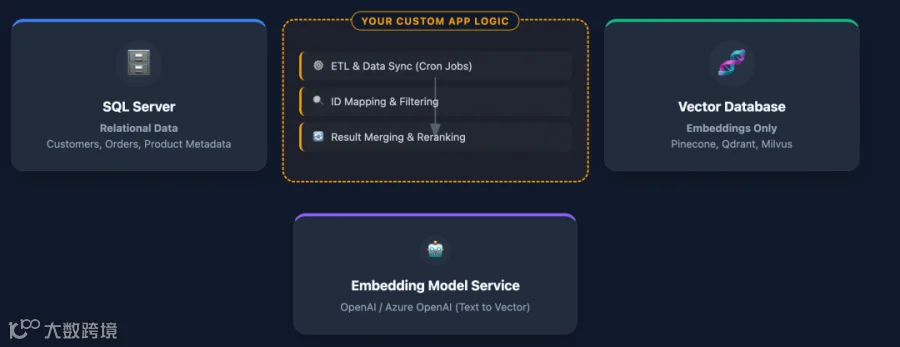
向量是 AI 时代的基石,可为文本、图像、音频、视频等信息赋予“语义坐标”,也就是 AI 理解世界的语言。以往在业务系统中计算语义相似度,往往需要引入外部向量数据库——数据多存一份、链路多一跳、运维多一套,安全和一致性也更复杂。“任何问题加一层都能解决”,但每多一层架构、成本、延迟和故障风险都随之上升。
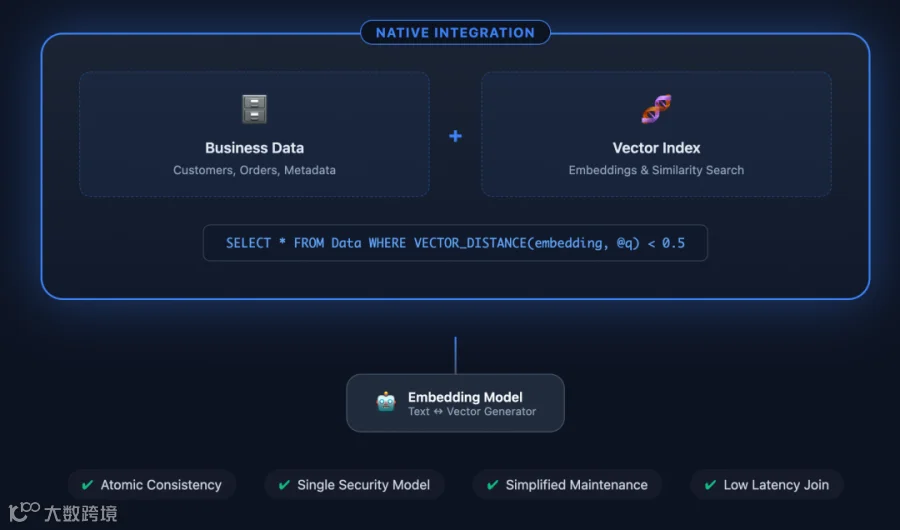
如果能把“向量存储 + 最近邻搜索”直接内置到数据库,引擎内部完成这一切,是不是就省掉了那层麻烦?事实证明可以。下图对比了有无原生向量支持时的架构差异:没有内置向量功能时,一个简单的 RAG 应用需要先从 SQL Server 捞数据,调用外部模型将文本切片并生成 Embedding,再把向量存入诸如 Milvus 等向量库,然后才能向量查询,整个流程繁琐且需处理数据同步、权限和一致性等问题。而有了 SQL Server 2025 内置向量支持后,这些操作都能在一台数据库内完成,架构一下子简单许多。
图:有向量支持之后的 SQL Server 2025
-
原生向量类型:SQL Server 2025 新增 VECTOR(n) 数据类型,即长度为 n 的浮点数数组,例如 VECTOR(3) 表示三维向量 [0.1, 2, 30]。向量在磁盘上以紧凑的二进制格式存储,避免了文本解析开销,存储空间占用也大幅减少。
-
DiskANN 向量索引:为了高效实现向量近似搜索,SQL 2025 引入了微软研究院的 DiskANN 算法。它将庞大的向量图索引存储在 SSD 上,只在内存中保留极小的导航信息,通过很少的随机磁盘读就能找到近似最近邻。虽然性能略逊于纯内存方案,但换来了 90% 以上的内存节省,查询延迟仍能达到毫秒级。配合阿里云 ESSD 云盘提供的高 IOPS 和低延迟,DiskANN 在云上可以实现接近本地 NVMe 的检索性能,性价比极高。
-
向量函数:SQL Server 提供了向量相似度计算和搜索的内置函数,例如用 VECTOR_DISTANCE 计算两个向量的距离,用 VECTOR_SEARCH 在表中执行向量最近邻查询等,方便开发者进行各种向量运算。
当前限制:目前表上建立了向量索引就不支持插入/更新操作(表会变只读),要修改数据必须先删除索引。据悉这个限制未来会取消。
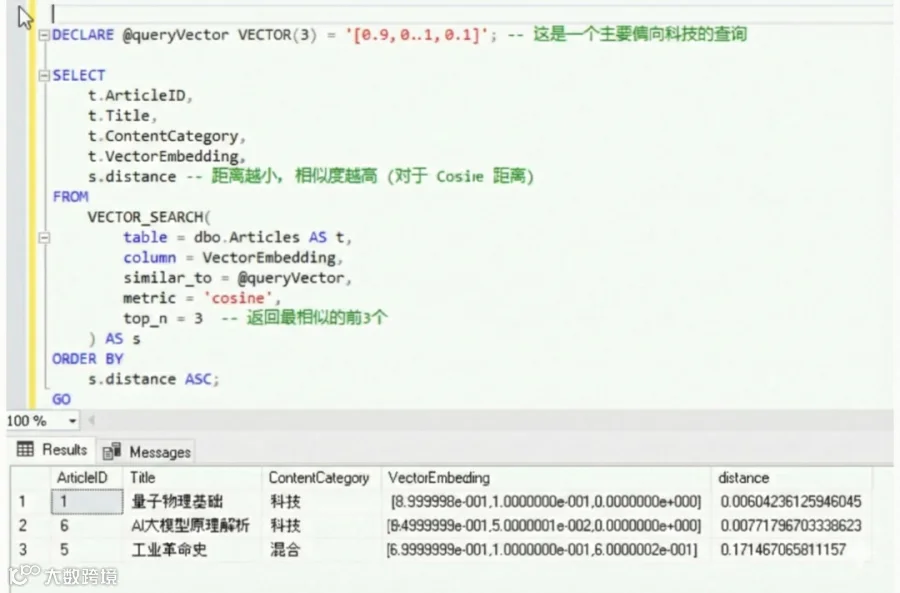
使用示例:比如,我们可以对文章库的 Embedding 列创建 DiskANN 索引,然后通过一条 SQL 查询找出与某个给定向量最相似的几篇文章(如图所示),整个过程完全在数据库内完成。
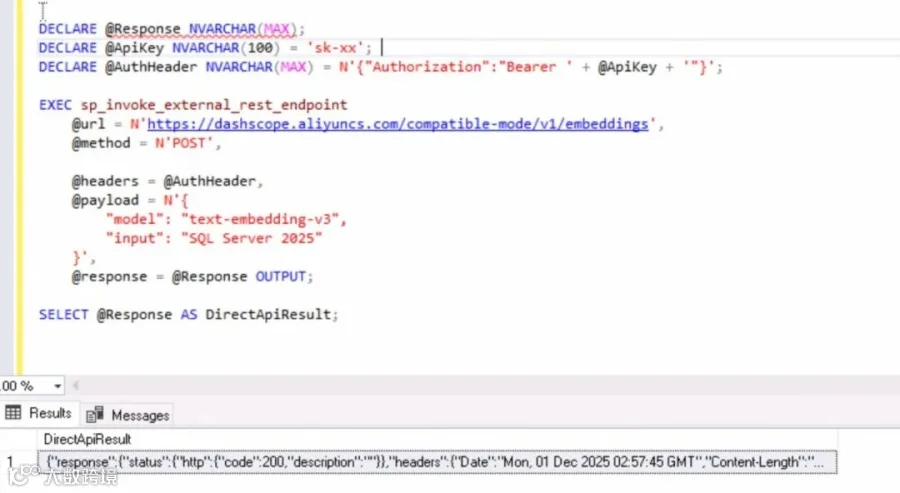
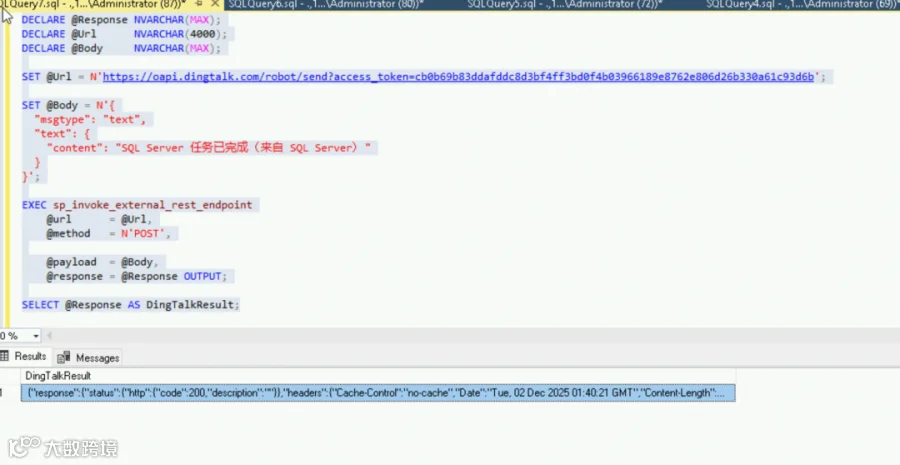
SQL Server 2025 内置了通过 HTTP 调用外部服务的能力(存储过程 sp_invoke_external_rest_endpoint),让数据库也能直接访问外部 REST API。这意味着我们可以在 T-SQL 脚本里调用 AI 模型的接口来处理数据——比如请求一个文本 Embedding API 得到向量,或者调用外部服务执行某种计算,把结果拿回来。同样,我们甚至可以直接在数据库中触发钉钉机器人的 Webhook 发送通知,实现真正由数据库驱动的自动化流程。
下图展示了在 T-SQL 中调用 AI 接口获取文本 Embedding 以及发送钉钉消息通知的例子:
此外,SQL Server 2025 还提供了 CREATE EXTERNAL MODEL 语法,方便注册第三方 AI 模型并通过内置函数调用。例如我们可以将 OpenAI 的 Embedding 接口注册为 External Model,随后直接使用 AI_GENERATE_CHUNKS、AI_GENERATE_EMBEDDINGS 等函数完成长文本切割和向量化。不过目前该功能只允许调用 OpenAI 官方域名,对于国内的大模型服务暂时无法直接使用(依然需要通过 sp_invoke_external_rest_endpoint 低层调用)。
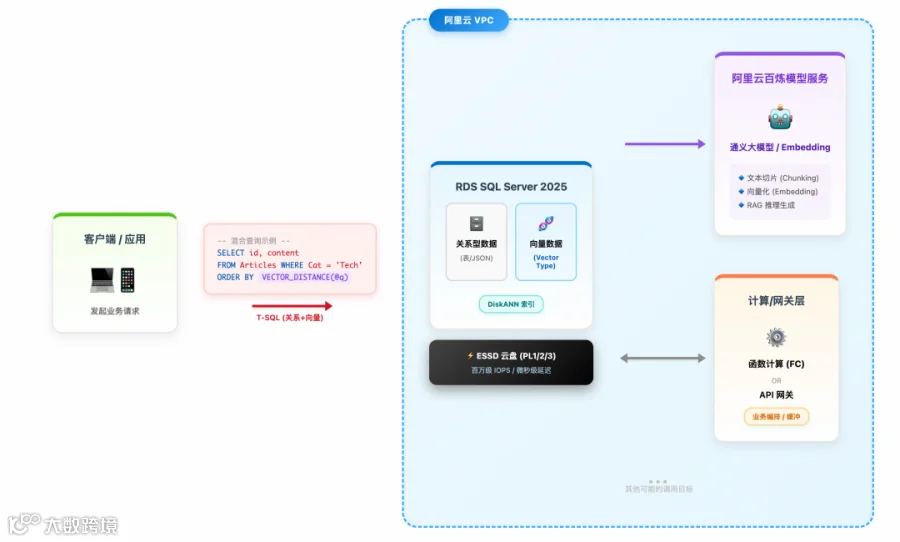
云上集成实践:对于阿里云用户,可以利用 SQL Server 2025 打造“业务库 + 向量库”的统一数据层。底层选用高性能 ESSD 云盘支撑 DiskANN 快速检索,同时通过函数计算或 API 网关对接阿里云通义千问等大模型服务,把文本切片、Embedding 生成、到最后的问答推理全流程都放在云上的内网完成。相比传统“业务库 + 外部向量库 + 公网 AI 服务”的架构,这种方案更简单高效,链路风险和延迟大大降低。
图:阿里云 RDS 向量库与内网大模型集成的架构示意
SQL Server 2025 引入了 TempDB 空间配额控制:DBA 可以为不同工作负载组设置 TempDB 使用上限,一旦某个查询超出额度会被立即终止(错误 1138),以保护 TempDB 不被耗尽。我感觉这个功能有点“鸡肋”——如今单实例通常只跑特定业务,很少有人需要这么精细地管 TempDB。不过在云上多租户隔离或防范“烂 SQL”耗光资源方面,它多提供了一道保障。
此外,TempDB 现在支持启用加速数据库恢复(ADR)。这意味着即使 TempDB 中有庞大的未提交事务,服务器意外宕机重启后也能在几分钟内完成数据库恢复,不会像以前那样可能卡住很久(我职业生涯中就遇到过 TempDB 恢复花了一整夜的惨痛案例)。这一增强大大提高了 SQL Server 在异常恢复时的可用性。
SQL Server 2025 增加了原生 JSON 数据类型(内部以二进制存储),而不只是简单地存储 JSON 字符串。这使 JSON 数据的存储效率显著提升(空间占用约减少 50%,并能自动验证格式),更重要的是支持对 JSON 文档的局部原地更新,不需要整段替换,修改 JSON 字段的性能和效率大幅提高。
除此之外,还新增了许多 JSON 处理函数和索引支持。例如 JSON_ARRAYAGG、JSON_OBJECTAGG 可以直接将查询结果组合成 JSON 数组或对象;JSON_CONTAINS 能判断 JSON 某路径下是否包含指定值,并且这些操作都可以利用 JSON 列上的专用索引加速查询。可以说,原生 JSON 支持相当于在 SQL Server 中嵌入了一个小型高效的 NoSQL 引擎,从此 JSON 数据在库里“存得下、改得快”。在我看来,这对大量使用 JSON 的场景(如物联网遥测、游戏配置)以及处理 AI 模型输入输出的数据都大有裨益。
SQL Server 2025 终于加入了原生正则表达式支持(基于 Google RE2 库),提供了 REGEXP_LIKE、REGEXP_REPLACE、REGEXP_SUBSTR/INSTR、REGEXP_SPLIT_TO_TABLE 等函数,可以在数据库内直接进行复杂的字符串匹配、替换、提取和拆分操作。例如可以用 REGEXP_LIKE 判断字符串是否符合邮箱格式,用 REGEXP_SPLIT_TO_TABLE 按正则分隔符拆解日志字符串成多行记录。
这个特性让 SQL Server 在日志分析、数据清洗等方面的能力大大增强。不过由于正则匹配对性能有一定影响,我认为这更像是与 Oracle、PostgreSQL 等其他数据库“看齐”的一项锦上添花功能,对日常 OLTP 负载而言影响不大。
锁机制:2025 版通过 ADR 带来了两项重大改进:一是不再发生锁升级,无论事务修改多少行都只保持极少的行版本锁,不升级表锁(大幅降低长事务对其他查询的阻塞);二是LAQ(资格后加锁),执行 UPDATE 时先筛选符合条件的行,确定要改哪些行后才加锁更新(避免扫描全表过程中对无关行加锁造成的干扰)。这些优化让高并发写入场景下的阻塞明显减少。
参数化查询:提供了 OPTIMIZED_SP_EXECUTESQL 选项,保证高并发情况下相同结构的参数化查询只编译一次、共享执行计划,避免“编译风暴”导致的 CPU 飙升。再结合 SQL 2022 引入的 PSPO(参数敏感计划优化),数据库会为不同参数值缓存多套计划并智能选择,解决了一刀切的单一计划对部分参数不友好的问题。
优化器增强:新增了 OPPO(可选参数优化),针对参数有时提供有时省略的查询分别生成不同执行计划,避免因为参数为空而生成全表扫描计划;以及更智能的基数估计反馈机制,可以跨查询学习常见过滤/连接模式的真实行数并调整估算,减少统计偏差造成的性能问题。
查询拦截:Query Store 新增 ABORT_QUERY_EXECUTION Hint,可以给特定查询打上标签,使之每次执行都会被引擎立刻终止(返回错误 8778)。对于无关紧要却异常耗资源的查询,这是个紧急止损的办法(当然治标不治本,该功能主要用于应急场景)。
列存索引:非聚集列存索引(NCCI)现在支持指定排序键,并且创建和重建都支持在线执行。这意味着在 OLTP 表上附加列存索引进行分析时,也能利用排序提升查询效率,并且可以不停机维护索引,非常有利于 HTAP(混合事务/分析处理)场景。列存索引本身在压缩和分析性能方面优势明显,这些改进进一步降低了使用门槛。
备份压缩:引入了新的 ZSTD 压缩算法,在相同压缩等级下压缩率更高且速度更快。阿里云 RDS 未来会将其作为2025备份的默认算法,备份文件体积明显减小,备份恢复的效率也随之提高。
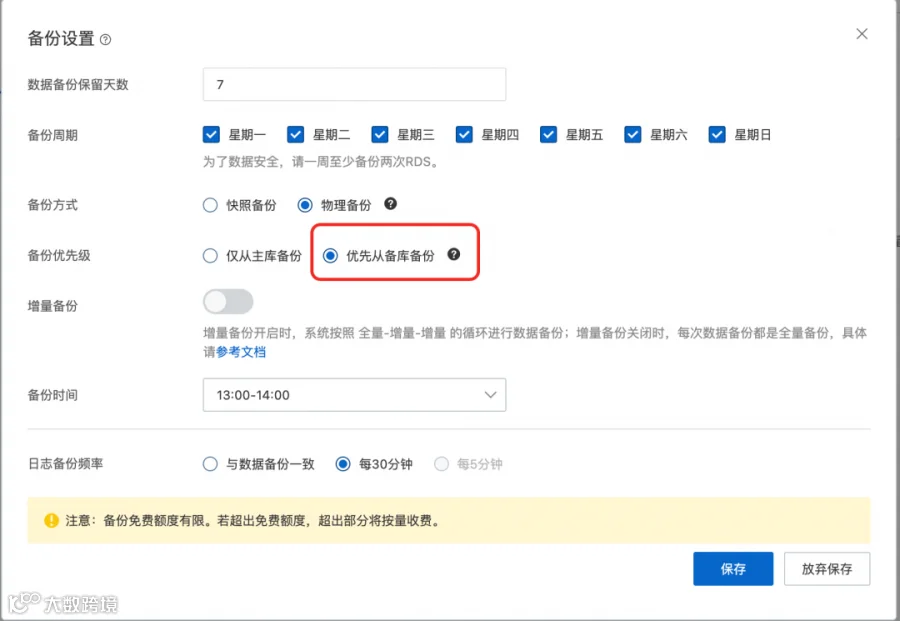
辅助副本备份:支持在 Always On 集群的辅助副本上执行完整和差异备份,不再必须由主库来承担备份工作,主库压力更小,备份安排更加灵活。
图:阿里云 RDS SQL Server 集群版支持备库备份
此外,2025 版默认在只读副本上启用 Query Store 并改进了统计信息同步,使只读副本的执行计划与主库更加一致,相同查询在副本上不再莫名“变慢”。
-
外部数据查询:无需安装 PolyBase,即可使用 OPENROWSET 在 T-SQL 中直接查询 OSS/S3 上的 Parquet、CSV 等文件,将对象存储视作数据库的一部分来访问。这实现了冷热数据分离、零 ETL 即席分析等场景,进一步打通了 SQL Server 同数据湖的融合。
-
内存表卸载:现在支持移除内存优化(In-Memory OLTP)功能的文件组。过去一旦启用了内存优化就无法删除文件组的限制终于解除,运维更加方便。
SQL Server 2025 无疑是一次飞跃,标志着数据库从传统的关系型存储演进为全面“AI 就绪”的数据平台。原生向量数据类型、高效 DiskANN 向量索引以及外部 AI 模型调用支持,让语义向量检索和 AI 推理可以直接在库内完成,极大简化了像 RAG 这类应用的架构。与此同时,JSON 原生支持、正则函数等开发增强和锁机制、参数化查询等内核升级,又解决了许多历史痛点,大幅提升了数据库的性能与易用性。
阿里云 RDS SQL Server 已同步支持这些新特性,并提供了一键升级能力,帮助用户以最低成本用上 SQL Server 2025 的强大功能。结合 DAS 智能诊断、Always On 高可用架构等云上优势,以及通过百炼平台对接通义千问大模型,RDS 上的 SQL Server 2025 将释放更大的潜力和价值。
目前阿里云 RDS SQL Server 2025 已正式发布。如果您希望在现有架构上无缝引入向量数据库和 AI 能力,欢迎点击文末「阅读原文」申请试用。
欢迎点击文末「阅读原文」申请免费试用 RDS SQL Server 2025版 1个月(新老用户同享)
欢迎加入RDS SQL Server 用户交流群(钉群号:117615001139)