

点击蓝字,关注我们

《新兴数据湖仓设计与实践手册·从分层架构到数据湖仓架构设计(2025 年)》 系列文章将聚焦从数据仓库分层到数据湖仓架构的设计与实践。手册将阐述数据仓库分层的核心价值、常见分层类型,详解分层下的 ETL 架构及数据转换环节,介绍数据仓库分层对应的技术架构,并以贴源层(ODS)、数据仓库层(DW)、数据服务层(DWS)为例,深入剖析数湖仓分层设计,最后探讨数据仓库技术趋势并进行小结。
本文为系列文章末篇,将详细剖析数据仓库分层下的数据服务层和数据应用层设计,并对当下湖仓技术以及未来技术趋势进行系统的总结。
👉上文回顾:《(一)从分层架构到数据湖仓架构:数据仓库分层的概念与设计》
(二)从分层架构到数据湖仓架构:数据仓库分层下的技术架构与举例
(三)从分层架构到数据湖仓架构系列:数据仓库分层之贴源层和数据仓库层设计
数据服务层设计
数据服务层设计(DWS,Data Warehouse Service)- 汇总层宽表
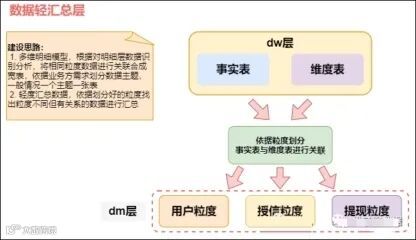
数据服务层(DWS)是基于数据明细层(DWD)构建的汇总层,面向特定业务主题,以宽表形式组织数据,支持分析和业务查询。该层的数据根据不同的主题和分析需求,通过对明细数据进行轻度聚合而成,减少维度数量,以便进行快速、高效的查询。
设计理念与结构
DWS层通过将DWD层的明细数据按主题域(如订单、用户、商品)进行汇总,为分析场景提供预处理的数据支持。数据粒度由细粒度提升至汇总粒度,以更适合多场景的业务查询需求。例如,按交易来源或类型对交易数据进行汇总,可以快速生成每天各主题的行为统计,如商品复购率、用户活跃度等。
特点和用途
-
面向主题:DWS层按业务主题划分数据,如销售、库存、客户等,生成覆盖多个指标的宽表。每张宽表通常包含较多字段,支持复杂的业务分析与数据分发。 -
少表宽表设计:DWS层表数量相对较少,每张宽表涵盖多个业务内容,减少表关联,提升OLAP分析和查询性能。 -
一致性整合:通过整合多个中间层数据(如DWD层),形成一致的企业级汇总事实表(如用户事实表、渠道事实表、终端事实表等),保证数据口径的一致性。
数据聚合与汇总示例
-
按天轻度汇总:基于DWD数据,对各主题对象(如购买行为)按天进行统计。例如,统计某商品的日复购率或销售额,方便后续的时间序列分析。 -
主题宽表示例:按照业务主题,生成具有较多字段的宽表,用于业务查询、OLAP分析等。例如,dws_sales_summary宽表可包含销售额、复购率、用户地域分布等字段。 -
多层次分析:以不同维度进行汇总,如最近一天特定类目(如厨具)商品在各省的销售总额,或者Top 10商品的销售额,支持灵活的多维分析。
场景应用与效率提升
通过汇总层的预聚合,DWS层可以满足80%的常见业务分析需求,减少直接查询ODS层的计算压力。例如,按7天、30天、90天等时间窗口的用户行为分析在DWS层中可以更加高效。
-
实时分析支持:对DWS层数据进行轻度汇总,有助于实现实时或准实时的用户画像、销售趋势分析等需求。 -
典型分析场景:如用户在不同时间段登录的IP及购买商品数量、各地区的购买力分布等。这些分析支持业务决策和营销策略调整。
命名和分区规范
-
表命名规范:建议DWS层表名以dws_主题_宽表描述命名,如dws_sales_summary或dws_user_activity. -
分区设计:通常按天或周创建分区,便于时间序列查询;若无时间属性,则根据业务需求自定义分区字段。
通过DWS层的数据汇总与主题划分,企业可以在汇总宽表的基础上,迅速提取核心业务指标,为上层业务查询、报表和OLAP分析提供高效、结构化的数据支持。
数据服务层(DWS)职责与设计原则
DWS层(数据汇总层)基于DWD层的明细数据,按业务主题对数据进行聚合,以宽表形式存储,支持业务查询、OLAP分析和数据分发。DWS层将多个DWD层表中分散的数据进行汇总,按主题整合到单一宽表中,例如用户、订单、商品、物流等。每张宽表涵盖相关主题的多个维度和指标字段,以满足业务方的多维度分析需求。
DWS层的核心任务
-
主题汇总
将DWD层的明细数据按照业务主题进行聚合,创建单独的宽表。例如,在“用户”主题下,用户注册信息、收货地址和征信数据等内容可以整合到一张宽表中,方便后续的数据查询和分析。 -
主题建模
针对特定业务主题,如流量、订单、用户,构建数据模型,将相关数据从DWD层抽取并聚合。DWS层提供的宽表通常按时间分层,如按天、月汇总的流量会话、每日新增用户、每日活跃用户等。 -
维度汇总
提前将查询需求中的常用维度数据进行聚合处理。例如,将营销渠道、用户来源等维度数据提前整合,简化后续的查询逻辑。
设计规范
-
宽表设计
DWS层通常为每个主题提供1至3张宽表,宽表覆盖多个业务指标,能够满足70%以上的业务需求。典型的宽表包括用户行为宽表、商品宽表、物流宽表和售后宽表等。其中,用户行为宽表是字段最丰富的,可能包含60至200个字段,以支持更全面的用户分析。 -
命名和分区规范 -
dws_asale_trd_byr_subpay_1d:按买家粒度的交易分阶段付款每日汇总。 -
dws_asale_trd_itm_slr_hh:按卖家粒度的商品小时汇总。 -
命名:DWS层表名以dws_开头,后接业务主题和时间周期标识(如_1d代表每日汇总,_1w代表每周汇总)。 -
分区:通常按天或小时创建分区(如_hh表示小时分区),如无时间维度,则根据业务逻辑选择分区字段。 -
示例命名: -
数据存储
DWS层数据采用Impala内表和Parquet文件格式存储,具备高效的查询性能。一般以覆盖旧表的方式更新数据,定期生成历史快照用于数据存档和溯源分析。
典型的DWS宽表设计示例
-
用户维度宽表示例
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表注释:每日购买行为
分区字段:dt(STRING 类型)
存储格式:PARQUET
存储路径:/warehouse/gmall/dws/dws_sale_detail_daycount/
表属性:"parquet.compression" = "lzo"

-
商品维度宽表示例
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表注释:商品粒度交易最近一天汇总事实表
分区字段:ds(STRING 类型,注释为“分区字段YYYYMMDD”)
生命周期:36000
DWS层的作用与数据集市的关系
DWS层通常被称为数据集市层,因其按业务主题对数据进行预处理和汇总,形成可供业务直接使用的宽表。如果DWS层提供的数据直接用于业务应用,则其可以被视为数据集市。DWS层中的数据集市宽表适合业务用户查询、生成报表、支持OLAP分析等。
DWS层是数据仓库的重要组成部分,提供了一个结构化、按主题分层的数据视图,通过提前汇总和聚合数据,DWS层有效降低了查询和计算成本,是数据仓库面向业务的核心数据服务层。
数据应用层设计
数据应用层设计(ADS,Application Data Store)
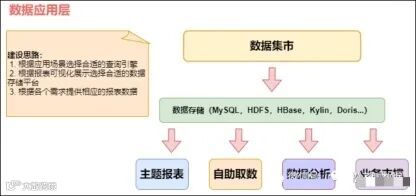
数据应用层(ADS)用于存储个性化的统计指标和报表数据,为数据产品、业务应用和数据分析提供专门的数据支持。ADS层的数据是高度汇总或定制化的数据集,覆盖流量、订单、用户等主题,以宽表形式存储,支持多维分析、查询、数据分发等。该层的数据粒度通常较粗,涵盖汇总数据和部分重要的明细数据,满足用户对近期数据的分析需求。
ADS层的核心功能
-
应用场景定制
在DWS层基础上,面向应用场景进一步聚合数据,生成高定制化的宽表(如用户行为、订单趋势)。这些数据可以直接供业务系统调用或导入至应用系统(如MySQL、Redis、Druid)中,用于前端展示、实时查询和分析。 -
满足部门需求
ADS层的数据按业务部门需求进行划分,仅包含与部门分析相关的数据子集。例如,流量数据集市提供流量分析指标,用户数据集市提供活跃度、转化率等用户行为数据,为业务方提供更直观的分析数据。 -
数据集市和宽表支持
数据集市在ADS层按主题划分,如流量、订单、用户等,生成字段丰富的宽表。这些宽表汇总了各类业务指标和维度,支持多种分析需求,广泛用于OLAP分析、KPI展示和业务监控。
数据生成和存储方式
-
数据生成
ADS层的数据源于DWD和DWS层,按业务需求从这些基础层数据中抽取并加工。ADS层表的数据更新频率依赖于业务需求,可以是每日或每小时刷新。 -
存储与分区
使用Impala内表和Parquet格式存储ADS数据,按天或业务字段进行分区,以优化查询效率。对于没有时间属性的表,根据具体业务选择适当的分区字段。 -
表命名规范
库名暂定为ads,表名格式建议为ads_主题_业务表名,按业务需求进行定制。
数据应用层示例
-
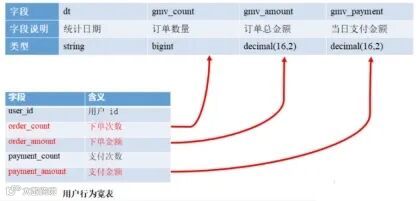
用户行为宽表
用于存储用户的互动、消费等行为数据,包含各类用户活动信息,如评论、点赞、收藏、分享、GMV等字段。每张宽表大约包含60-200个字段,满足多维度的用户分析需求。



|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
分区字段:dt(STRING 类型)
存储格式:PARQUET
-
商品销售汇总表
汇总商品的销售数据,按日或更细粒度进行存储,为分析商品的销售趋势、库存管理等提供支持。
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 分区字段 | ds (STRING) | 分区字段 YYYYMMDD |
| 生命周期 | 36000 |
|
-
用户活跃度 -
日活、周活、月活:统计用户的活跃频率,通过设备ID计算不同时间范围内的活跃用户。 -
留存率:统计新增用户的留存情况,计算1天、7天等时间范围内的用户留存率。 -
用户增长与回流 -
新增用户:基于每日新增用户的统计。 -
回流用户:分析在一段时间内回归活跃的用户数量。 -
用户转化与行为分析 -
转化率:从商品详情到下单、支付的转化率。 -
复购率:按用户或商品的复购情况统计,支持商品或品类的复购趋势分析。 -
商品分析 -
销售额和GMV:按商品或品类计算销售额和GMV,分析热销产品。 -
Top N商品:计算销售排名前N的商品,支持流行度和消费偏好的分析。 -
用户留存与流失分析 -
沉默用户:统计登录时间为7天前且登录频率极低的用户。 -
流失用户:识别近期未登录或活跃度降低的用户,便于后续的用户运营和召回策略。
数据应用层的角色与更新策略
-
应用层角色
ADS层主要面向业务方和数据产品团队,数据经过多层处理和汇总后直接支持报表、KPI、OLAP分析和仪表盘等应用。作为面向最终用户的数据集市,ADS层能够快速响应业务需求。 -
更新方式
旧数据通常采用覆盖更新,按业务需求定期刷新,确保数据时效性。
临时表支持
-
TMP层
数据处理过程中常需临时表以支持复杂计算,ADS层提供独立的TMP层(DW TMP)用于存储这些中间计算结果,避免主数据表的反复更新,提高数据处理的效率和稳定性。
通过ADS层的数据集市和宽表设计,企业能够更灵活地支持多种数据产品和分析需求,为业务增长、用户行为分析、市场洞察等提供强有力的数据支撑。
层次调用规范
在数据仓库分层架构中,必须遵循严格的调用规范,以确保数据流动的单向性,避免复杂的依赖关系和反向调用。
-
禁止反向调用:下层数据不可调用上层数据,保持数据流向的单向性和清晰性。 -
调用规范: -
oODS层:仅允许被DWD层调用。 -
oDWD层:允许被DWS和ADS层调用。 -
oDWS层:仅允许被ADS层调用。 -
oADS层:可调用DWD、DWS及其他ADS表,但建议优先使用汇总度更高的数据,以减少数据冗余和性能消耗。
调用路径概述
数据的标准调用路径包括:
-
ODS -> DWD -> DWS -> ADS -
ODS -> DWD -> ADS
数据仓库技术趋势与小结
数据仓库技术趋势与小结
数据仓库分层架构为企业构建了高效、稳定的海量数据管理体系,支持数据治理、业务逻辑隔离、数据追踪和复用。通过ODS、DWD、DWS和ADS的分层设计,数据在逐层传递和加工中实现标准化和清洗,确保了一致性和数据可追溯性。
这一架构不仅提高了数据使用的规范性,还降低了系统耦合,提升了数据共享的便捷性。
-
ODS层:作为原始数据接入层,ODS层负责保留细粒度数据,通过ETL或CDC方式捕获源系统的变更数据,确保数据完整性。 -
DWD层:标准化数据并进行清洗和脱敏,去除冗余,确保数据一致性,为后续分析和建模提供了基础。 -
DWS层:将DWD数据聚合为符合业务主题的宽表,构建面向主题的数据服务,优化计算性能并促进数据复用。 -
ADS层:进一步聚合数据,生成高性能、面向应用的宽表,支持数据产品和业务应用场景,如OLAP分析、KPI监控和仪表盘展示。
随着数据规模和数据源的多样化,数据仓库的架构和技术也在不断演进,当前的主要趋势包括:
- 实时数据处理与CDC技术
传统的批量数据处理已经无法满足现代企业的需求,CDC技术成为数据实时同步和更新的主流方法,确保数据仓库中数据的实时性。 - 数据湖与数据仓库的融合
在成为行业的热门趋势,例如Data Lakehouse架构,将数据湖的灵活性与数据仓库的高效分析能力相结合,为企业提供更强的数据管理能力。 - DataOps与自动化数据管理
随着企业对数据管理自动化要求的提高,DataOps逐渐成为数据管理的核心工具。例如,白鲸开源的DataOps工具能够实现从数据采集到数据质量控制的全流程自动化管理。
白鲸开源数据集成调度系统(WhaleStudio) 是 ApacheDolphinScheduler 和Apache SeaTunnel 原班人马打造的商业版数据同步与调度工具,提供功能更多、稳定性更强的商业版本解决用户调度,数据开发、数据同步和 ETL 的问题,目前支持 200+ 种数据库(信创、云、开源、ERP 等)的 ETL 与数据开发,全面替换Informatica 与 Talend 等工具相应功能,在中信证券等多个行业头部企业都有成功商业版和实施替换案例。
如有意咨询,发送邮件至 service@whaleops.com,或者扫码二维码咨询:


·END·
白鲸开源
白鲸开源是一家开源原生的DataOps商业公司,是国家高新技术企业,由多个Apache Foundation Member成立,80%员工都是 Apache Committer,运营2个全球Apache开源项目(DolphinScheduler, SeaTunnel)。白鲸开源已根据全球最佳实践发布商业版产品WhaleStudio(含白鲸数据调度平台WhaleScheduler和白鲸数据集成平台WhaleTunnel)。我们致力于打造下一代开源原生的DataOps 平台,助力企业在大数据和云时代,智能化地完成多数据源、多云及信创环境的数据集成、调度开发和治理,以提高企业解决数据问题的效率,提升企业分析洞察能力和决策能力。
了解更多

金融行业的应用实例
国内某头部理财服务提供商基于白鲸调度系统建立统一调度和监控运维
白鲸调度系统助力国内头部券商打造国产信创化 DataOps 平台
白鲸开源 DataOps 平台助力证券行业实现信创数字化转型
最佳实践 | 从Airflow迁移到Apache DolphinScheduler
Apache DolphinScheduler VS WhaleScheduler
代立冬:基于Apache Doris+WhaleTunnel 实现多源实时数据仓库解决方案探索实践
商业版技术解析实例
驾驭数据的未来:WhaleStudio与DataOps的完美结合
运营开源项目

点个在看你最好看