
关注上方“公众号”,有福利哦!
小伙伴们好,我是阿旭。专注于人工智能、计算机视觉领域相关分享研究。【目标检测、图像分类、图像分割、目标跟踪等项目都可做,也可做不同模型对比实验;需要的可联系(备注来意)。】
《------往期经典推荐------》
一、AI应用系统实战项目
《------正文------》
引言
在目标检测领域,「速度与精度不可兼得」曾是行业共识——YOLO系列以轻量化和实时性称王,却困于NMS后处理的精度瓶颈;DETR类模型凭Transformer端到端优势引领革新,却被高昂的计算成本拖慢推理速度。直到RT-DETR横空出世,这个由百度飞桨团队首创的「实时端到端检测器」,不仅打破了这一魔咒,更通过持续迭代将「高效+精准」的平衡推向新高度。
今天,我们就来深挖RT-DETR的进化史:从初代破局到v4的「VFM免费赋能」,它如何一步步成为实时检测领域的顶流?
一、RT-DETR初代(2023.4):端到端实时检测的「破冰者」

核心使命:解决DETR系列「推理慢」的痛点,实现「无NMS+实时高精度」的初步平衡。
作为系列开山之作,RT-DETR首次将Transformer架构与实时检测需求深度融合,提出了两大革命性设计:
1. 混合编码器(Hybrid Encoder)
传统DETR依赖全局自注意力机制处理多尺度特征,计算复杂度随图像分辨率平方级增长,导致速度瓶颈。RT-DETR的混合编码器通过解耦尺度内交互(AIFI,自适应交互融合集成)与跨尺度融合(CCFM,跨尺度特征融合模块),高效整合低层细节(如边缘、纹理)与高层语义(如物体类别),既保留了多尺度检测能力,又将计算量降低到可实时运行的水平。
2. IoU-aware查询选择(IoU-aware Query Selection)
DETR原版的查询(Query)初始化依赖随机或固定策略,易选中低质量特征导致漏检或误检。RT-DETR创新性地引入IoU(交并比)感知机制——根据特征与真实框的潜在匹配度(通过分类分数和IoU分数联合评估)筛选初始查询,让模型从训练初期就聚焦于「最可能包含物体」的区域,显著提升检测精度与效率。
实测表现:
-
R50骨干在COCO val2017上达到53.1% AP(平均精度),推理速度108 FPS(T4 GPU); -
R101骨干达54.3% AP,速度74 FPS; -
对比同期YOLOv5/v8,精度相当甚至更优,且彻底告别NMS后处理延迟。
意义:首次证明「端到端Transformer检测器」能在实时场景中与YOLO正面竞争,被业界称为「YOLO终结者候选者」。
二、RT-DETRv2(2024.7):训练侧的优化
 核心使命:在不增加推理成本的条件下,通过训练策略升级挖掘模型潜力。
核心使命:在不增加推理成本的条件下,通过训练策略升级挖掘模型潜力。
如果说初代解决了「能不能实时」的问题,v2则聚焦「如何更高效地变强」。百度团队提出了一系列「Bag of Freebies(BoF)」训练侧优化技术,核心围绕「解耦多尺度采样」与「部署友好性」展开:
1. 训练策略增强
-
动态数据增强:根据训练阶段动态调整图像缩放、颜色抖动等策略,提升模型泛化性; -
尺度自适应超参:自动优化学习率、正负样本比例等超参数,减少人工调参成本; -
离散采样算子优化:改进多尺度特征采样方式,让模型更精准地关注关键区域。
2. 部署友好设计
通过解耦多尺度特征的处理逻辑,v2模型在保持精度的同时,显著降低了推理时的计算冗余,对边缘设备(如Jetson Xavier NX)更友好。
实测表现:在相同硬件下,v2相比初代进一步提升了小物体检测能力(如PCB焊点、交通标志等细节),且训练效率提升约30%,成为工业质检等场景的优选。
三、RT-DETRv3(2024.9):查询能力的「精准进化」

核心使命:通过强化Query的表达能力,让模型「更懂」要检测什么。
v3的突破点在于通过密集正样本监督(Dense Positive Supervision)与自注意力扰动(Self-Attention Perturbation),从训练机制上提升Query的质量:
1. Dense Positive Supervision(密集正样本监督)
传统DETR仅依赖匈牙利匹配生成稀疏的正负样本标签(每个Query对应一个真实框或背景),v3则引入CNN分支与Transformer分支的双重监督——CNN分支提供局部细节特征指导,Transformer分支保留全局上下文信息,两者协同为Query提供更丰富的正样本信号,尤其对小物体和遮挡场景更有效。
2. Self-Attention Perturbation(自注意力扰动)
通过轻微扰动Query的自注意力权重(如随机遮盖部分注意力头),强制模型学习更鲁棒的特征表示,避免过拟合特定场景,提升泛化能力。
实测表现:以轻量版R18为例,AP提升约**1.6%**,推理速度几乎不变;更大模型(如R50/R101)在复杂场景(如夜间车辆检测、密集人群计数)中漏检率显著降低。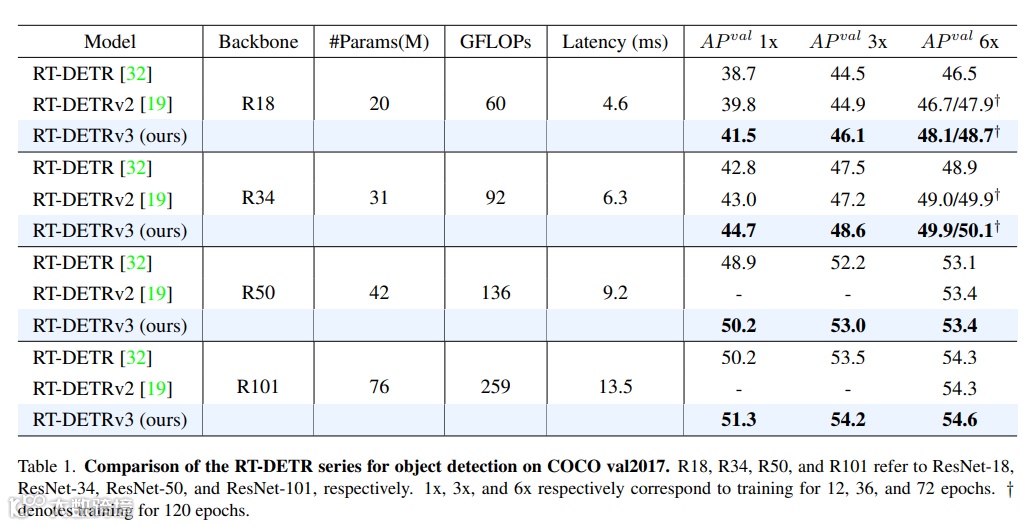
四、RT-DETRv4(2025.10):VFM赋能的「无痛升级」

核心使命:让轻量级检测器「零成本」享受视觉大模型(VFM)的强大语义能力。
这是目前最前沿的版本(论文发表于2025年10月),由北大&清华团队与百度合作推出,核心创新在于「训练时知识蒸馏,推理时零开销」的VFM协同框架,解决了轻量检测器「特征表示弱」的固有缺陷。
1. 核心组件:DSI(深度语义注入器)+ GAM(梯度引导自适应调制)
-
DSI(Deep Semantic Injector):以视觉大模型(如DINOv3)为「教师」,提取其预训练的海量语义特征(如物体的高层语义、复杂场景理解),并通过仅对混合编码器输出的顶层特征F5(语义最丰富层)进行精准对齐注入,避免多层级注入的梯度冲突。 -
GAM(Gradient-guided Adaptive Modulation):动态监测训练过程中检测器自身特征梯度的强度,智能调整VFM知识的注入权重——若检测器学得顺利,则降低VFM影响;若遇到困难(如模糊物体),则增强VFM辅助,确保知识迁移既有效又不干扰原任务优化。
2. 效果:SOTA精度+实时速度

在COCO数据集上,RT-DETRv4系列模型全面超越YOLOv13等竞品:
-
RT-DETRv4-X(最大模型):57.0% AP @ 78 FPS(兼顾高精度与实时性); -
RT-DETRv4-L:55.4% AP @ 124 FPS; -
RT-DETRv4-S(轻量版):49.7% AP @ 273 FPS(边缘设备友好)。
更重要的是,所有性能提升均来自训练阶段的VFM辅助,推理时无需加载大模型,完全零计算开销,真正实现了「用大模型的能力,跑小模型的速度」。
五、总结
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
从初代打破实时检测的「NMS枷锁」,到v2/v3通过训练优化挖掘潜力,再到v4借助VFM实现「无痛升级」,RT-DETR的每一次迭代都紧扣「实时性」与「精度」的核心矛盾,逐步解锁更广阔的应用场景:
-
工业质检(如PCB缺陷检测、零件分类):高精度+低延迟,漏检率大幅降低; -
智能安防(如交通监控、人流统计):复杂环境(雨雪、逆光)下的鲁棒性优势; -
边缘计算(如无人机、可穿戴设备):轻量版模型在ARM芯片上也能流畅运行。
正如开发者所言:「RT-DETR的进化没有终点——未来或许会进一步融合多模态信息(如文本+视觉),或拓展到3D检测领域。」 对于开发者而言,无论是追求极致速度的小模型,还是需要高精度的旗舰版,RT-DETR家族总有一款适合你。

好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
end
福利!!!本公众号为粉丝精心整理了超级全面的python学习、算法、大数据、人工智能等重磅干货资源,关注公众号即可免费领取!无套路!
看到这里,如果你喜欢这篇文章的话,
点击下方【在看】【转发】就是对我最大支持!
如果觉得有用就点个“赞”呗