
关注上方“公众号”,有福利哦!
小伙伴们好,我是阿旭。专注于人工智能、计算机视觉领域相关分享研究。【目标检测、图像分类、图像分割、目标跟踪等项目都可做,也可做不同模型对比实验;需要的可联系(备注来意)。】
《------往期经典推荐------》
一、AI应用系统实战项目
《------正文------》
引言

SAM(Segment Anything Model)系列模型作为Meta FAIR推出的视觉分割基础模型,从最初的图像交互式分割,逐步拓展到视频领域,再到支持概念级prompt理解,实现了从“分割特定对象”到“分割任意概念”的跨越。本文将详细拆解SAM、SAM 2、SAM 3三个版本的核心特点、技术创新与能力升级,展现其如何持续重塑视觉分割的技术边界。
一、SAM:图像分割的“交互革命”(2023)
作为系列开篇之作,SAM首次将“可提示性分割(Promptable Segmentation)”概念落地,为图像分割带来了全新的交互范式。
核心定位

专注于静态图像的交互式分割,支持点、框、掩码等视觉提示输入,用户通过简单交互即可实现任意对象的分割,无需针对特定任务微调。
关键创新
-
通用分割能力:基于SA-1B数据集(10亿级掩码标注)训练,实现“分割一切”的零样本泛化能力,可适配医疗影像、遥感图像等多种场景。 -
高效交互设计:采用轻量级掩码解码器,针对模糊提示(如单个点击)会输出多个候选掩码,确保总能生成有效结果。 -
模块化架构:由图像编码器、提示编码器和掩码解码器组成,图像编码器采用ViT-H/L/B架构,兼顾精度与速度。
核心局限
-
仅支持静态图像,无法处理视频的时间维度信息; -
依赖视觉提示,不支持文本等高层概念输入; -
一次交互仅能分割单个对象实例,无法批量处理同类对象。
二、SAM 2:打通图像与视频的“时空分割”(2024)
SAM 2作为系列的第二代模型,核心突破是将分割能力从静态图像拓展到动态视频,实现了图像与视频的统一分割框架。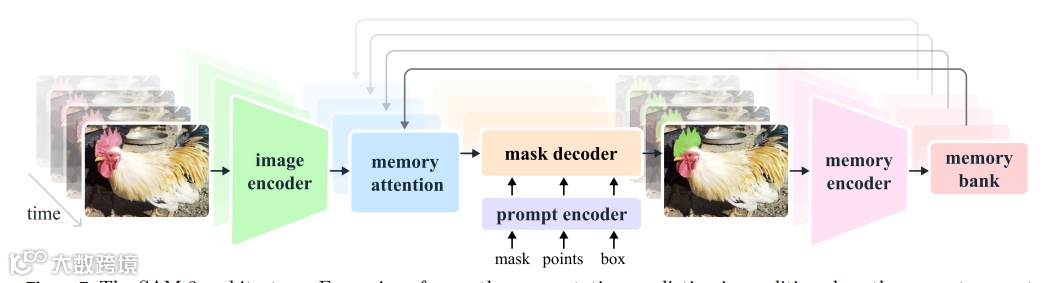
核心定位
统一图像与视频的可提示性分割,支持在视频任意帧添加提示,自动生成跨帧掩码序列(masklet),兼顾实时性与准确性。
关键创新
-
流式内存架构:引入内存注意力模块和内存银行,存储过往帧的对象信息与交互历史,支持视频帧的逐帧流式处理,无需一次性加载全部视频。 -
视频分割优化:针对视频的运动、遮挡、模糊等问题,通过内存上下文校正分割结果,仅需3倍 fewer交互即可达到优于前代的视频分割精度。 -
效率与精度双升:采用MAE预训练的Hiera图像编码器,相比SAM快6倍,同时在图像分割任务上保持更高精度。 -
大规模数据集支撑:构建SA-V数据集,包含50.9K视频、35.5M掩码,是当时最大的视频分割数据集,覆盖室内外多种场景,支持“分割任意视频对象”。
核心升级
-
从“单帧图像”到“多帧视频”,新增时空维度建模; -
支持视频任意帧交互 refinement,解决遮挡后重识别等视频特有问题; -
保持与SAM一致的图像分割能力,实现“一套模型适配两类任务”。
三、SAM 3:迈向概念级理解的“全能分割”(2026)
SAM 3作为系列的第三代模型,实现了从“视觉提示驱动”到“概念提示驱动”的质变,支持文本短语、图像示例等高层概念输入,开启了开放词汇分割的新篇章。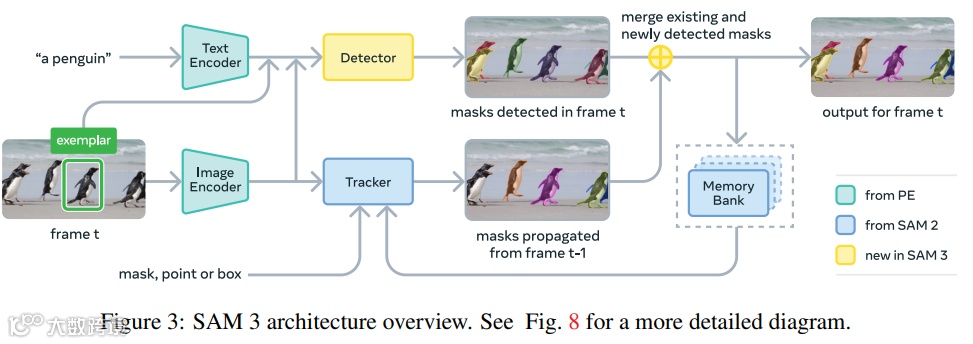
核心定位
Promptable Concept Segmentation(PCS),支持文本短语(如“黄色校车”)、图像示例等概念提示,可分割图像/视频中所有匹配该概念的对象实例,并保持跨帧身份一致性。
关键创新

-
概念级理解能力:突破视觉提示局限,支持简单名词短语、图像示例及组合提示,可批量分割同类对象(如“所有猫咪”),而非单个实例。 -
解耦识别-定位架构:引入全局存在令牌(Presence Token),专门负责判断概念是否存在于图像/帧中,对象查询仅负责定位,大幅提升开放词汇场景下的检测精度。 -
高效数据引擎:构建SA-Co数据集,包含4M独特概念标签、52M高质量掩码,通过“人类+AI验证”机制,标注效率较前代提升8.4倍,覆盖15个视觉领域。 -
视频跟踪优化:结合检测器与SAM 2风格的跟踪器,通过IoU匹配、周期性重提示等策略,解决拥挤场景、遮挡等跟踪难题,支持多对象并行跟踪。 -
多能力融合:在保留图像/视频分割能力的基础上,新增对象计数、复杂查询理解(需结合MLLM)等功能,零-shot性能超越现有开放词汇分割模型。
核心突破
-
从“分割特定对象”到“分割一类概念”,实现开放词汇场景的泛化; -
从“单一视觉提示”到“多模态概念提示”,更贴近人类自然交互习惯; -
数据引擎引入AI验证器,大幅降低高质量标注成本,支撑概念级分割训练。
四、SAM系列的进化脉络与行业影响
技术进化主线
-
任务边界拓展:图像分割(SAM)→ 图像+视频统一分割(SAM 2)→ 概念级开放词汇分割(SAM 3),逐步突破任务场景限制; -
提示能力升级:视觉提示(点/框/掩码)→ 时空视觉提示 → 概念提示(文本/图像示例),交互方式更自然、更高层; -
架构持续优化:模块化基础架构 → 流式内存扩展 → 解耦识别-定位架构,逐步适配更复杂的任务需求; -
数据驱动升级:SA-1B(图像)→ SA-V(视频)→ SA-Co(概念),数据集规模与多样性持续扩大,支撑模型泛化能力提升。
行业价值
-
降低分割技术使用门槛:从专业标注工具到“自然语言/简单交互”即可使用,赋能非专业用户; -
拓展应用场景:覆盖AR/VR、机器人、视频编辑、医疗影像等,从静态场景到动态场景,从特定对象到一类概念; -
树立基础模型标杆:证明视觉分割模型可通过“基础模型+提示工程”实现通用化,为后续开放词汇视觉任务提供范式。

好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
end
福利!!!本公众号为粉丝精心整理了超级全面的python学习、算法、大数据、人工智能等重磅干货资源,关注公众号即可免费领取!无套路!
看到这里,如果你喜欢这篇文章的话,
点击下方【在看】【转发】就是对我最大支持!
如果觉得有用就点个“赞”呗