
veDB MySQL 版是火山引擎自研的云原生关系型数据库产品,100% 兼容原生 MySQL。而 veDB-Search,则是基于 veDB MySQL 版的技术底座,拓展出的一站式混合检索的全新服务:用户仅使用 SQL ,即可完成对向量+全文+标量数据的存储和混合检索。
更多详细内容可阅读综述篇:veDB-Search:AI 混合检索,懂 SQL 就行
本文为实战篇,首先介绍业务如何基于 veDB-Search 使用一条 SQL 高效解决真实场景的多路召回问题,解锁更多功能以解决业务痛点。然后介绍内置的 In-DB Embedding 功能,体现将向量嵌入逻辑从业务侧全透明下沉到数据库内的优势。最后以电商业务案例演示 veDB-Search 如何支持文搜万物。
多路召回:一条 SQL 完成多路向量+文本+标量召回
传统多路召回的架构之痛
-
架构复杂: 需要同时维护向量数据库、全文搜索引擎(如 ES)和关系型数据库。且向量数据库内不止维护一路 embedding。 -
数据同步: 需构建复杂的 ETL 或 CDC 链路保证数据一致性。 -
业务逻辑沉重: 业务层需要分别调用不同系统的 SDK,进行结果召回、聚合、去重和排序,代码复杂,维护难度大。
veDB-Search 的破局之道
-
一条 SQL 实现多路召回
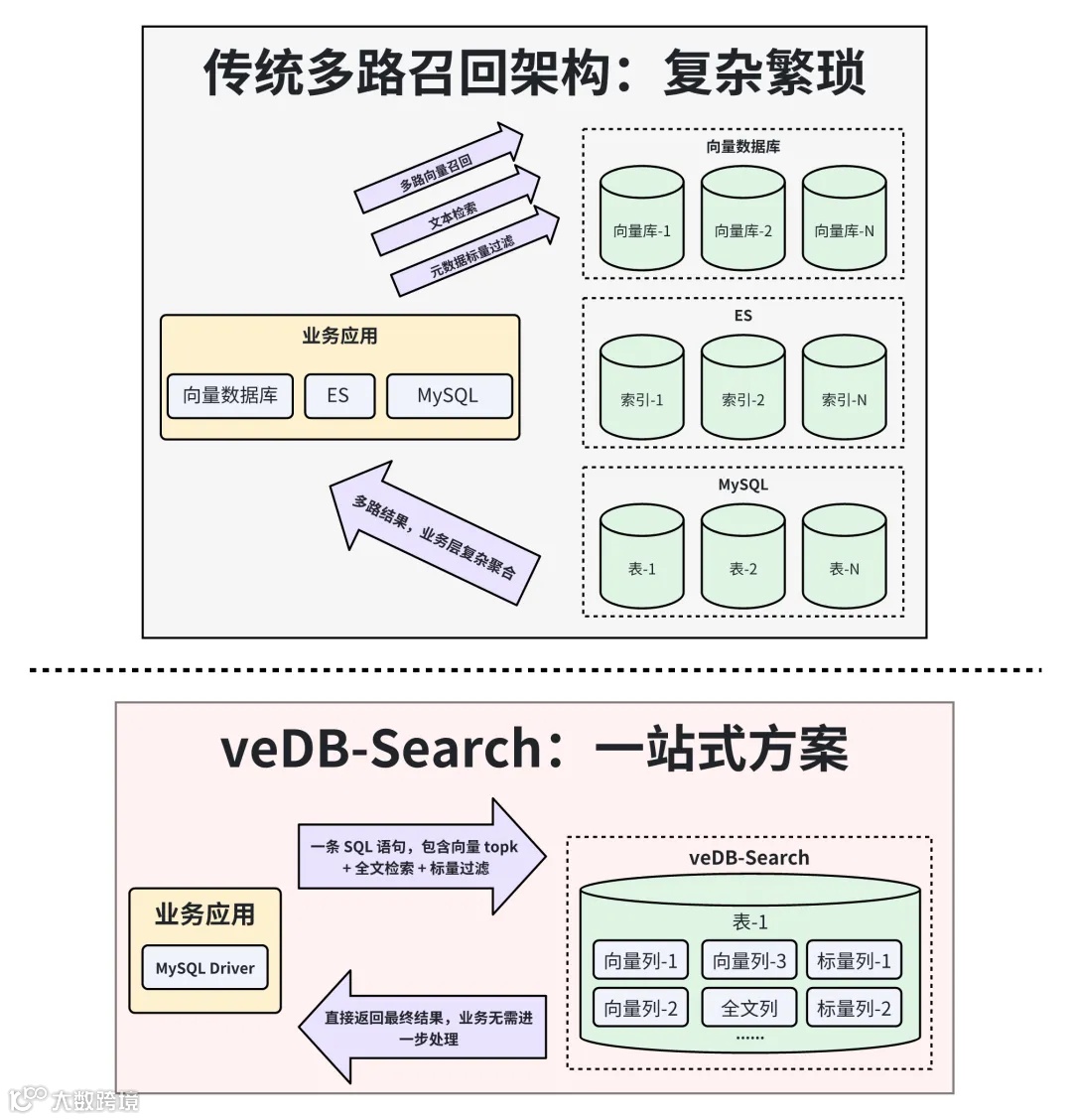
-
多路召回的执行流程
-
解析标准 SQL -
优化器自动选择最优索引,生成最优计划 -
调度器将各路检索下推到向量索引上执行过滤 -
根据权重进行分数融合与排序 -
返回最终结果集
-
veDB-Search 核心优势
-
开发提效: 将复杂的多系统交互代码简化为一条 SQL 语句。 -
运维减负: 只需维护一个 veDB 实例,无需关心数据同步。 -
性能保障: 内置优化器选择最优执行路径,分布式架构保障性能。
三路召回实战示例
下面以电商场景为例,演示如何使用 veDB-Search,通过一条 SQL 语句来高效完成多路向量召回+条件过滤。
-
【STEP 1】在 products表上创建包含多个向量列的混合索引
ALTER TABLE products ADD VECTOR INDEX `hybrid_idx`(
-- context 为文本列,用于文本内容检索
`context`,
-- emb1/emb2/emb3为三路独立的向量列,用于多路近似检索
`emb1`, `emb2`, `emb3`)
SECONDARY_ENGINE_ATTRIBUTE = '{
"distance": "cosine", -- 指定距离算法
"scalar_fields": "category, discount, price" -- 指定标量过滤列
}'
;
-
【STEP 2】一条 SQL 语句完成三路向量召回+文本检索+标量过滤
WITH
-- 第一路:文本向量topk + 文本内容检索
description_recall AS (
SELECT id, name, 2.0 as score, 'description' as recall_type
FROM products
WHERE MATCH(context) AGAINST("户外远足装备") -- 支持文本检索
ORDER BY similarity(emb1, [0.1, 0.2, 0.3, 0.4]) DESC
LIMIT 50
),
-- 第二路:商品图向量topk + 价格过滤 + 折扣过滤
hot_item_recall AS (
SELECT id, name, 1.5 as score, 'item' as recall_type
FROM products
WHERE price BETWEEN 200 AND 400
AND discount > 0.10 --支持标量过滤
ORDER BY similarity(emb2, [0.1, 0.2, 0.3, 0.4]) DESC
LIMIT 50
),
-- 第三路:商品详情图向量topk
detailed_recall AS (
SELECT id, name, 0.8 as score, 'detailed_item' as recall_type
FROM products
ORDER BY similarity(emb3, [0.1, 0.2, 0.3, 0.4]) DESC
LIMIT 50
),
-- 合并三路结果
combined AS (
SELECT * FROM description_recall
UNION ALL SELECT * FROM hot_item_recall
UNION ALL SELECT * FROM detailed_recall
)
-- 最终排序输出
SELECT id, name, score, recall_type
FROM combined
ORDER BY score DESC
LIMIT 100;
解锁更多高阶功能
-
过滤条件
veDB-Search 支持使用标准 SQL的 WHERE 语法,在召回时进行精准过滤。用户只需要按业务需求编写各种过滤条件,veDB-Search 会自动优化以选择 per-filter/post-filter 策略。在极端情况下,如果标量过滤性极强,优化器会采用 KNN 暴搜反而带来更优的执行效果。用户可按标准 SQL 进行复杂过滤,例如:
WHERE
MATCH(context) AGAINST("户外远足装备")
AND (
price BETWEEN 200 AND 400
OR
discount > 0.10
)
-
文本匹配
veDB-Search 支持使用增强的 MATCH AGAINST 语法,支持布尔查询、短语查询、模糊查询等。veDB-Search会对目标列构建倒排索引,实时更新新写入的数据,支持与其它过滤条件混合使用。例如:
SELECT * FROM articles
WHERE
MATCH(title) AGAINST('database search' IN BOOLEAN MODE)
AND price BETWEEN 100.00 and 200.00;
-
倒数排序融合(RRF)
veDB-Search支持对多路召回结果进行加权,既能确保标量和全文检索的精确性,同时也能保障向量搜索的语义理解能力。
RRF 计算公式:
RRF_score = (1 / (k + 在列表1中的排名)) + (1 / (k + 在列表2中的排名)) + ... -
rank_i:文档在第 i 个搜索结果列表中的位置(第1名,第2名...)。 -
k:一个可调节的常数,通常 >= 60,用于控制排名的影响程度。
例如:
SELECT
id,
title,
1 / (@k + RANK() OVER (ORDER BY score DESC)) AS partial_rrf -- 结合窗口函数
RRF 对多路召回结果加权具有重要实际作用,如平衡不同召回路径的优势,提高结果相关性,提供统一排序标准。
如果用户不想使用 RRF,或是想获取具体 score 值,可以使用 veDB-Search 提供的 similarity 函数,此函数返回已经范式化的 score 值,可直接参与 ORDER BY 排序。
SELECT
cosine_distance(emb1, [0.1, 0.2, 0.3]) as distance,
similarity(distance) * FACTOR as similarity -- 用户可以指定加权因子
FROM articles
ORDER BY similarity DESC
-
距离或相似度过滤
veDB-Search 支持指定最大距离,在搜索过程中过滤掉相似度不高(距离远)的数据点,以进一步提高精确率。
-- 指定最大距离过滤
SELECT * FROM articles
WHERE
cosine_distance(emb1, [0.1, 0.2, 0.3]) as distance < 2.0
In-DB Embedding:支持端到端“文搜万物”
前面介绍了如何使用单条 SQL 语句高效实现多路召回。在本章节,我们将探讨另一个高阶功能 —— In-DB Embedding,即将向量嵌入过程从业务侧全透明地下沉至 veDB-Search 内。最后以电商业务为例,演示 veDB-Search 如何支持“文搜万物”能力。
veDB-Search 支持两种 In-DB Embedding 功能:
-
提供 to_embedding()函数,用户直接调用,即可对传入的文本/图像生成 embedding -
支持 embedding_pipeline()函数,在混合索引中设置,即可透明地完成从原始数据到 embedding 的隐式转换,无需用户显式调用 上述功能的特点,以及适用场景如下:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
显式存储 embedding 列(VECTOR 类型)。
|
写仅存储原始数据列(文本/图片 URL),不存储 embedding 列。
|
|
|
|
|
|
|
|
|
|
|
|
|
to_embedding()函数
功能定位:将文本、图像等数据转换为 embedding,以支持跨模态向量检索。
技术实现
-
文本向量化:支持无缝对接火山方舟提供的模型(如 Doubao-embedding-large),将商品标题、描述等转换为 embedding。 -
图像向量化:支持无缝对接火山方舟提供的模型(如 Doubao-embedding-vision),将商品主图 URL 转换为 embedding。
函数签名
to_embedding('model_id', 'model_key', 'user_input','model_type')
-
model_id:火山方舟模型 ID -
model_key:火山方舟模型密钥 -
user_input:用户需要生成 embedding 的原始数据(文本/图片 URL) -
model_type:支持三种取值 -
content:文本类模型,适配原始数据为文本的场景 -
image:多模模型,适配原始数据为图片 URL 的场景 -
text:多模模型,适配原始数据为文本的场景
使用示例
在 veDB-Search 中创建一张document_asset表,通过调用to_embedding()函数将原始文本数据转换为 4096 维的 embedding,存入 VECTOR 列。然后根据用户提出的问题,基于该向量列进行 topk 相似性检索,最终给用户召回内容贴切的帮助文档。
/* 生成“三合一冲锋衣”对应的 embedding */
SELECT to_embedding('doubao-embedding-large', '$model_key','三合一冲锋衣', 'content') AS title_vec;
/* 生成冲锋衣图片对应的 embedding */
SELECT to_embedding('doubao-embedding-vision', '$model_key', 'https://example.com/product.jpg', 'image') AS img_vec;
/* 创建一张带 VECTOR 列的文档表,并创建一个 ANN Index 加速查询 */
CREATE TABLE `document_asset` (
`id` BIGINT PRIMARY KEY AUTO_INCREMENT COMMENT '主键ID,自增唯一标识',
`content_vec` VECTOR (4096) NOT NULL COMMENT '文本内容,用于向量化',
ANN KEY `idx` (`content_vec`))
ENGINE=InnoDB COMMENT='文档表';
/* 插入一些示例数据 */
INSERT INTO document_asset VALUES
(1, (select to_embedding('$model_id', '$model_key', 'MySQL 用户指南', 'content'))),
(2, (select to_embedding('$model_id', '$model_key', 'veDB-Search介绍', 'content'))),
(3, (select to_embedding('$model_id', '$model_key', 'RAG实际应用', 'content'))),
(4, (select to_embedding('$model_id', '$model_key', '定制AI Agent', 'content'))),
(5, (select to_embedding('$model_id', '$model_key', '向量数据库介绍', 'content')));
/* 对用户的输入语句:“如何试用MySQL”,完成 top 2 相似性召回 */
SELECT id FROM document_asset
ORDER BY
l2_distance(to_embedding('$model_id', '$model_key', '如何试用MySQL', 'content'), content_vec)
LIMIT 2;
embedding_pipeline函数
功能定位
-
透明易用:在表上建索引时,为索引设置 embedding_pipeline,即可对文本/图像URL 列的数据在底层引擎自动生成 embedding 并写入索引结构。 -
成本友好:在 veDB 表上不存储具体的 embedding 数据,仅存储原始数据(文本/图像URL),大大降低了存储成本。
函数签名
embedding_pipeline('user_input','model_type')
-
user_input:用户需要生成 embedding 的原始数据(文本/图片 URL) -
model_type:支持三种取值 -
content:文本类模型,适配原始数据为文本的场景 -
image:多模模型,适配原始数据为图片 URL 的场景 -
text:多模模型,适配原始数据为文本的场景
使用示例
/* 创建一张电商产品表,带有混合索引。混合索引上定义了 embedding_pipeline */
CREATE TABLE `products` (
`id` BIGINT PRIMARY KEY AUTO_INCREMENT COMMENT '主键ID,自增唯一标识',
`image_url` MEDIUMTEXT NOT NULL COMMENT '图片的url地址',
`type` INT NOT NULL DEFAULT 0 COMMENT '商品类型,用于标量过滤',
ANN KEY `idx` (`image_url`) SECONDARY_ENGINE_ATTRIBUTE = '{
"scalar_fields": "type",
"distance": "cosine",
"emb_pipeline": [
{
"col_name": "image_url",
"model_id": "$model_id",
"auth_key": "$model_key",
"type": "image"
}
]
}'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='选品向量表';
/* 插入一些原始图片URL数据,无需业务显式生成 embedding 值 */
INSERT INTO products(id, image_url, type) values
(1, 'https://example.com/iphone17.jpg', 1),
(2, 'https://example.com/macbook.jpg', 1),
(3, 'https://example.com/ipad.jpg', 1),
(4, 'https://example.com/toothbrush.jpg', 2);
/* 召回 top 2 相似图片 */
SELECT id FROM products
ORDER BY
l2_distance(embedding_pipeline('https://example.com/iphone15.jpg', 'image'), image_url)
LIMIT 2;
电商选品实战案例
【Case 1】以文搜图:文本描述匹配商品图像
场景需求:用户输入文本“三合一冲锋衣”,需要召回与文本描述相似的商品。
实现步骤
-
创建商品表和混合索引:索引指定 emb_pipeline,设置多模态 embedding 模型 -
数据写入:将产品图片 URL 和其他商品元数据信息写入 veDB-Search 中的商品表 -
结果过滤:结合销量、价格等标量条件,根据用户的输入信息筛选优质商品
SQL 示例
SELECT product_id, title, img_url
FROM products
WHERE sales > 100 AND price < 500
ORDER BY
l2_distance(embedding_pipeline('三合一冲锋衣', 'text'), image_url)
LIMIT 10;

【Case 2】以图搜图:根据用户购物车的内容,进行相似产品的推荐
场景需求:用户上传一张商品图,结合其他商品元数据信息,返回平台内同款或相似商品。
实现步骤:
-
创建商品表和混合索引:索引指定 emb_pipeline,设置多模态 embedding 模型 -
数据写入:将产品图片 URL 和其他商品元数据信息写入 veDB-Search 中的商品表 -
结果排序:按图片相似度、销量、价格综合排序。
SQL 示例:
SELECT product_id, title, img_url
FROM products
WHERE sales > 100 AND price < 500
ORDER BY
l2_distance(embedding_pipeline('https://example.com/product.jpg', 'image'), image_url)
LIMIT 10;

最佳实践技巧
veDB-Search 通过一条 SQL 实现多路召回和 In-DB Embedding 两大能力,直接支撑了业务“文搜万物”的需求,同时大幅降低开发复杂性和运维成本。
更多技巧:
-
路径设计:根据业务核心维度(如商品图、描述、标签)设计召回路径。 -
权重调优:通过 A/B Test 持续调整多路召回 SQL 语句中各路的权重分数,以优化召回效果。 -
索引优化:创建混合索引,把 embedding 列和常用的标量列都包含在索引内。且在大数据规模下,利用 veDB 的云原生能力实现弹性扩缩容。
veDB-Search 正将数据库从被动的“数据容器”转变为主动的“认知引擎”,是构建下一代AI应用的关键基础设施。
基于 veDB MySQL 版的强大技术底座,veDB-Search 混合检索功能在火山引擎目前已支持开通测试白名单,欢迎点击【阅读原文】提交工单参与试用。