

大家好!欢迎关注小号:医学统计数据分析,今天我们来介绍一下医学统计学中常用统计学方法的R语言基本操作。R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。

我们先下载R与Rstudio的安装包,先安装R,再安装Rstudio。RStudio是一款R语言的集成开发环境(IDE),R自带的环境操作起来可能不是方便,而Rstudio很好地解决了这个问题,RStudio只是辅助你使用R进行编辑的工具,因为它自身并不附带R程序。
R下载地址(官网):
https://cran.r-project.org/bin/windows/base/
Rstudio(官网):
https://rstudio.com/

打开RStudio之后,会出现上图所示的窗口,其中有四个独立的面板。RStudio界面分为左上角的源码编辑、脚本显示,左下角的代码执行、控制台,右上角的代码历史记录、数据对象列表,右下角的代码组织管理、包安装、更新、绘图。
我们先把需要分析的Excel表格另存为.csv格式,使用<-read.csv("")语句读取待分析的表格。
数据读取后,在脚本显示窗口可见数据预览:

使用summary()语句,对导入的数据大致分布做一下基本了解:

使用 anova<-aov(研究因素~分组因素)
summary(anova) 语句,可得方差分析结果:DF/SS/MS/F值/P值

使用plot(分组因素,研究因素)语句,可画出三组比较的箱形图:

使用chisq.test(分组因素,研究因素)做卡方检验,可见下图输出:

使用cor.test(testdata$1,testdata$2)语句做相关性分析,

使用plot(因素1,因素2)语句画出散点图。

使用> lm(Y~X+1)语句及

summary(lm(Y~X+1))语句得到一元线性回归的B值、R2、残差分析等结果。

根据整理好的时间序列资料,使用plot()语句,即可直接画出时间序列图(散点):
安装包:
install.packages("zoo")
install.packages("xts")
载入包:
library(zoo)
library(xts)
计算与画图:
ts<- xts(data3$分析数据, as.Date(data3$日期, format='%Y/%m/%d'))
plot(ts)
xts可画出线图:

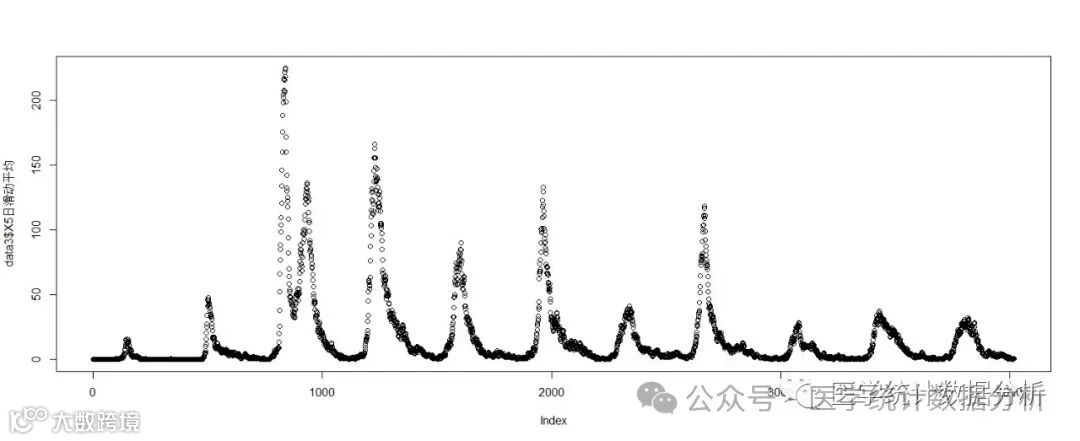
同样,我们也可以画出五日平均线等平滑曲线:

























机器学习是人工智能的一个重要分支,近年来在数据分析、图像识别、自然语言处理等领域发挥的作用越来越重要。机器学习的基本概念围绕着如何让计算机利用数据来进行学习和预测。而R语言,作为一种统计分析和图形表示的强大工具,因其丰富的包和灵活的数据处理能力,在机器学习领域中占有一席之地。今天我们开始R语言机器学习的第一篇,数据准备与包的批量安装。
机器学习是一门研究如何使计算机系统从数据中学习和改进性能的学科。它通过训练模型来识别模式、预测趋势和做出决策从而实现对数据的自动处理和分析。
机器学习算法通过对大量数据进行学习,提取出有用的特征并建立模型来预测新数据。这些模型可以不断优化,以适应不同类型的数据和任务。常见的机器学习算法包括KNN、决策树、随机森林、贝叶斯等。
我们先打开Rstudio,对于单个包的安装与加载想必大家都已经很熟悉:
rm(list=ls()) #移除所有变量数据
install.packages() #安装包
library() #加载包
然后读取和写入Excel的包需要用到readxl和writexl:
#读取Excel数据
install.packages("readxl")
library(readxl) #加载包
data <- read_excel("路径/示例数据.xlsx")
#写入Excel数据导出
install.packages("writexl")
library(writexl) #加载包
write_xlsx(data.all, "路径/总表.xlsx")
我们今天用到的示例数据是一个1000个个案的
数据库,我们用readxl读取进Rstudio进行处理。


我们可以
#定义要加载机器学习所需要的包列表,检查每个包是否已经安装,如果没有安装,则进行安装并加载
packages<-c("readxl","ggplot2","caret","lattice","gmodels",
"glmnet","Matrix","pROC","Hmisc","rms",
"tidyverse","Boruta","car","carData",
"rmda","dplyr","rpart","rattle","tibble","bitops",
"probably","tidymodels","fastshap",
"shapviz","e1071")
for(pkg in packages) {
if (!require(pkg, quietly = TRUE)) {
install.packages(pkg, dependencies = TRUE)
library(pkg, character.only = TRUE)
}
}
# 使用library()函数一次性加载多个包
lapply(packages,library,character.only = TRUE)
或者可以
#直接定义并批量安装包
packages<-c("readxl","ggplot2","caret",
"lattice","gmodels","glmnet","Matrix","pROC",
"Hmisc","rms","tidyverse","Boruta","car",
"carData","rmda","dplyr","rpart","rattle","tibble",
"bitops","probably","tidymodels","fastshap",
"shapviz","e1071")
install.packages(c("readxl","ggplot2","caret",
"lattice","gmodels","glmnet","Matrix","pROC",
"Hmisc","rms","tidyverse","Boruta","car","carData",
"rmda","dplyr","rpart","rattle","tibble","bitops", "probably","tidymodels","fastshap",
"shapviz","e1071"))
install.packages(packages)
# 使用library()函数一次性加载多个包
lapply(packages,library,character.only = TRUE)
进一步我们可以进行简单分析:
#独立样本t检验
t.test(data$指标1 ~ 结局, data = data, var.equal = TRUE)
t.test(data$指标2 ~ 结局, data = data, var.equal = TRUE)
t.test(data$指标3 ~ 结局, data = data, var.equal = TRUE)

#卡方检验
CrossTable(data$结局,data$指标8,expected = T,chisq = T,fisher = T, mcnemar = T, format = "SPSS")

#logistic回归
data$Group<-as.factor(data$结局)
model1 <- glm(Group ~ 指标1, data = data, family = "binomial")
summary(model1)
model2 <- glm(Group ~ 指标1+指标2, data = data, family = "binomial")
summary(model2)
model3 <- glm(Group ~ 指标1+指标2+指标3, data = data, family = "binomial")
summary(model3)

#ROC曲线
roc1 <- roc(data$结局,data$指标1);roc1
roc2 <- roc(data$结局,data$指标2);roc2
roc3 <- roc(data$结局,data$指标3);roc3
plot(roc1,
max.auc.polygon=FALSE, # 填充整个图像
smooth=F, # 绘制不平滑曲线
main="Comparison of ROC curves", # 添加标题
col="red", # 曲线颜色
legacy.axes=TRUE) # 使横轴从0到1,表示为1-特异度
plot.roc(roc2,
add=T, # 增加曲线
col="orange", # 曲线颜色为红色
smooth = F) # 绘制不平滑曲线
plot.roc(roc3,
add=T, # 增加曲线
col="yellow", # 曲线颜色为红色
smooth = F) # 绘制不平滑曲线



#列线图
dd<-datadist(data)
options(datadist="dd")
data$Group<-as.factor(data$结局)
f_lrm<-lrm(Group~指标1+指标2+指标3+指标4+指标5+指标6+指标7+指标8,data=data)
summary(f_lrm)
par(mgp=c(1.6,0.6,0),mar=c(5,5,3,1))
nomogram <- nomogram(f_lrm,fun=function(x)1/(1+exp(-x)),
fun.at=c(0.01,0.05,0.2,0.5,0.8,0.95,1),
funlabel ="Prob of 结局",
conf.int = F,
abbrev = F )
plot(nomogram)

训练集和测试集是深度学习技术中经常使用的一种数据划分方式。它可以将数据自动划分为训练集和测试集,用于模型开发的评估。
训练集是为训练模型而准备的一组数据,它通常是人类标记过的,表明它们拥有特定方面的属性。通常情况下,为了训练有效的模型,训练集的采样大小最好是足够大的,而且应该有足够的多样性,可以代表它们的数据集中的所有可能的情况
测试集是一组样本,用于测试训练好的模型,通过测试集检验训练好的模型,从而测试模型的正确率和准确性。它本质上是一组未知的数据样本,用于测试模型性能的时候,而不受训练集采样的偏向,可以更可靠的评估模型的性能。
那么怎么划分测试集与训练集呢?
#分层抽样划分训练集和测试集
set.seed(123)
train <- sample(1:nrow(data),nrow(data)*7/10) #取70%做训练集、其余30%为测试集
#数据读取拆分与组合
Train <- data[train,] #定义训练集数据
Test <- data[-train,] #定义测试集数据
All <- rbind(Train, Test) #将拆分数据合并

#写入Excel数据导出
install.packages("writexl")
library(writexl) #加载包
write_xlsx(Train, "C:/Users/L/Desktop/Train.xlsx")
write_xlsx(Test, "C:/Users/L/Desktop/Test.xlsx")
write_xlsx(All, "C:/Users/L/Desktop/All.xlsx")

Python是一种广泛使用的语言,可以用于构建和应用各种机器学习模型。
以下是一些最常见的机器学习模型及其Python实现:
1.线性回归:用于回归分析,可以预测单个或多个输出。
2.逻辑回归:用于二分类问题,可以预测二进制输出。
3.决策树:用于二分类和多分类问题,可以可视化决策边界。
4.K最近邻(KNN):用于分类和回归问题,主要是基于实例的学习算法。
5.支持向量机(SVM):用于二分类和回归问题,可以找到最优分离超平面。
6.集成方法:如随机森林、Boosting等,可以提高预测精度并降低方差。
7.神经网络:用于复杂函数逼近和大规模数据集分类。
8.主成分分析(PCA)和 t-SNE:用于数据降维和可视化。
9.特征工程:包括数据清洗、特征缩放、特征选择等。
10.深度学习:用于复杂的数据分析和模式识别。
今天我们以临床医学数据中最常见的二分类因变量的logistic回归为例,开始Python机器学习系列的第一篇。
Scikit-learn(sklearn)是一个基于Python的开源机器学习库,它建立在NumPy、SciPy和Matplotlib之上,为数据建模提供了一整套工具。
Scikit-learn提供了大量的算法和工具,涵盖了数据挖掘、数据分析和机器学习领域的各种任务,包括分类、回归、聚类、降维等。
主要特点和功能
1.简单易用:Scikit-learn的设计非常简洁,易于上手,即使对于机器学习的新手也能快速掌握。
2.功能强大:它包含了从基础的线性回归、逻辑回归到复杂的支持向量机等多种机器学习算法。
3.集成性好:Scikit-learn与NumPy、Pandas、Matplotlib等Python科学计算库紧密集成,方便进行数据预处理、模型训练和结果可视化。
4.社区活跃:Scikit-learn有一个活跃的开源社区,不断更新和完善库的功能,同时提供丰富的文档和教程资源。

今天我们仍以熟悉的示例数据集为例,演示一下Python机器学习的数据准备:train_test_split训练集及测试集拆分。

加载程序包(openpyxl和pandas等)
#使用pandas读取示例数据xlsx文件
import openpyxl
import pandas as pd
import matplotlib.pyplot as plt
import sklearn
from sklearn.model_selection import train_test_split
# 加载数据集
dataknn = pd.read_excel(r'C:\Users\L\Desktop\示例数据.xlsx')
# 查看前几行数据
print(dataknn.head())
# 分离特征和目标变量
X = dataknn[['指标1', '指标2', '指标3','指标4','指标5','指标6']]
y = dataknn['结局']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)

在后续的分享中,我们将继续一起学习R语言和Python机器学习的各个模型简单示例,欢迎大家。
