
数据的来源千奇百怪,如果是属于自己的数据可直接从系统导出或者数据库获取非常省事;但如果数据是由别人提供的或者陈年累月积累下来的,并且在几十个表以上,如果每个表的格式和数据列是同类型的数据那么这个方法就很高效处理这个问题。
该方法的前提是需要保证列数相同,并且是同类型的数据。将所有需要合并的表格放在同一个文件夹中。如下面的例子共28个不同时间的表需要合并

示例代码如下:
# 加载所需的包import pandas as pdimport glob ,osfrom warnings import filterwarningsfilterwarnings('ignore')
path = r'E:\数据分析之渔\批量合并文件' #文件夹路径file = glob.glob(os.path.join(path,'*.csv'))print(file)d1 = []for f in file:d1.append(pd.read_csv(f))for i in d1:print("共 {} 列,列名称:{}".format(i.shape[1],i.columns)) # 查看每个表有多少列 ,查看每个表的列名称print("一共{}个表".format(len(d1))) # 查看该文件夹下一共有多少个表df = pd.concat(d1) #合并所有表
结果


如不同的表是按月份或者人名、或地名进行命名但表中不含有该信息的时候,需要根据表名来添加识别的数据,可按如下方法
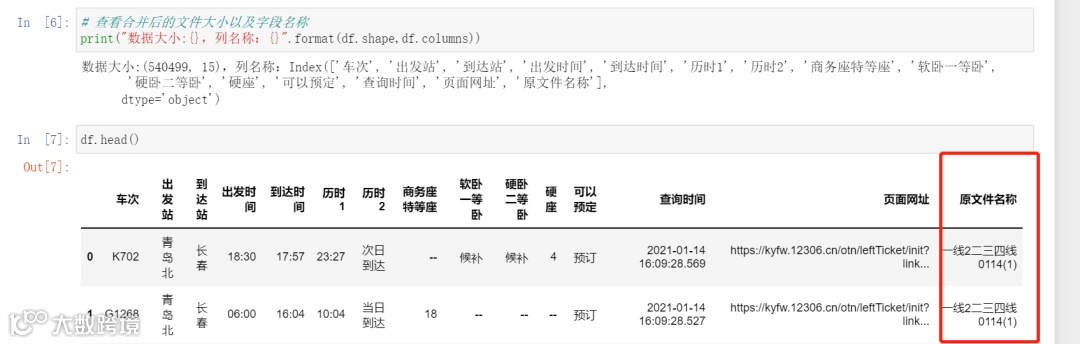
path = r'E:\数据分析之渔\批量合并文件'file = glob.glob(os.path.join(path,'*.csv'))d1 = []for f in file:a = pd.read_csv(f) # 读取文件a['原文件名称'] = os.path.basename(f).split('.')[0] # 新增的列,os.path.basename() 函数为获取文件名d1.append(a)df = pd.concat(d1) # 合并文件
# 查看合并后的文件大小以及字段名称print("数据大小:{},列名称:{}".format(df.shape,df.columns))
结果,“原文件名称”便是新增用于识别的列,如果表格是利用日期命名但表中不含日期信息那么这个方法就很有效
end~~


数据分析之渔
碎片时间提升自己