




本节所使用的尾鸢花数据集是Python中自带的数据集,常用于机器学习分类算法模型,其中sepal_length_cm、sepal_width_cm、petal_length_cm、petal_width_cm、class字段代表的含义分别是花萼长度、花萼宽度、花瓣长度、花瓣宽度、尾鸢花的类别。
from pandas import Series,DataFrameimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport matplotlib as mplimport seaborn as sns #导入seaborn绘图库%matplotlib inline
iris_data = pd.read_csv(open('D:\python数据分析\数据\iris-data.csv'))iris_data.head()

通过数据可视化和分析,按照尾鸢花的特征分出尾鸢花的类别。
iris_data.shapeiris_data.describe()
iris_data['class'].unique() #查看唯一值array(['Iris-setosa', 'Iris-setossa', 'Iris-versicolor', 'versicolor','Iris-virginica'], dtype=object)iris_data.ix[iris_data['class'] == 'versicolor', 'class'] = 'Iris-versicolor'iris_data.ix[iris_data['class'] == 'Iris-setossa', 'class'] = 'Iris-setosa'iris_data['class'].unique() #查看唯一值
array(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'], dtype=object)sns.pairplot(iris_data, hue='class')
iris_data.ix[iris_data['class'] == 'Iris-setosa', 'sepal_width_cm'].hist()
iris_data = iris_data.loc[(iris_data['class'] != 'Iris-setosa') | (iris_data['sepal_width_cm'] >= 2.5)]iris_data.loc[iris_data['class'] == 'Iris-setosa', 'sepal_width_cm'].hist()
iris_data.loc[(iris_data['class'] == 'Iris-versicolor') &(iris_data['sepal_length_cm'] < 1.0)]
iris_data.loc[(iris_data['class'] == 'Iris-versicolor') &(iris_data['sepal_length_cm'] < 1.0),'sepal_length_cm'] *= 100.0iris_data.isnull().sum()
iris_data[iris_data['petal_width_cm'].isnull()] #处理缺失值
iris_data.dropna(inplace=True)iris_data.to_csv('D:\python数据分析\数据\iris-clean-data.csv', index=False) #保存清洗后的数据iris_data = pd.read_csv(open('D:\python数据分析\数据\iris-clean-data.csv'))iris_data.head()

iris_data.shapesns.pairplot(iris_data, hue='class')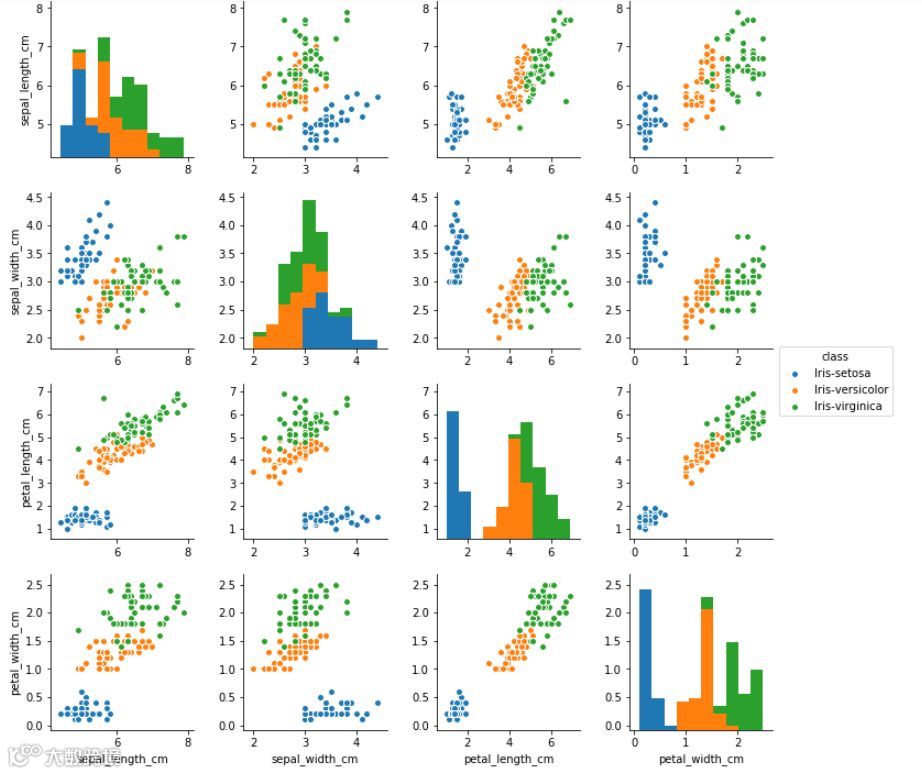
iris_data.boxplot(column='petal_length_cm', by='class',grid=False,figsize=(6,6))
通过petal_length_cm(花瓣长度)可以轻松区分Iris-setosa与其他两种花。





