
本文作者:赵晓岚,河南大学经济学院
本文编辑:崔雨晨
技术总编:马梦杰
Stata and Python 数据分析
爬虫俱乐部Stata基础课程、Stata进阶课程和Python课程可在小鹅通平台查看,欢迎大家多多支持订阅!如需了解详情,可以通过课程链接(https://appbqiqpzi66527.h5.xiaoeknow.com/homepage/10)或课程二维码进行访问哦~



describe 命令:快速查看数据结构。 describe 命令是查看数据集的基本结构的第一步,输出结果包含每个变量的名称、储存方式、显示格式、变量标签和变量值标签。
summarize:生成核心描述统计。 summarize(简称sum)命令用来汇总一个变量或者多个变量的描述性统计信息,描述数据变量的分布特征,生成五大关键指标:均值mean、标准差sd、最小值min、最大值max以及样本量n,是最常用的描述性统计命令之一。
tabulate命令:探索类别变量的频率分布。tabulate(简称tab)命令可以生成频数表,它能够帮助我们了解变量的类别分布情况。
clear allimport excel "D:\data\数据.xlsx", firstrow clear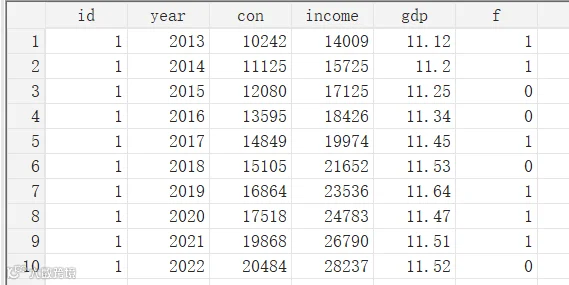

describe命令

基本用法:查看特定变量的信息。
describe id year //精准定位特定变量 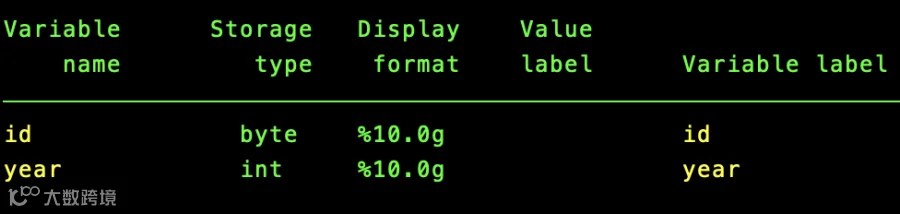
describe, detail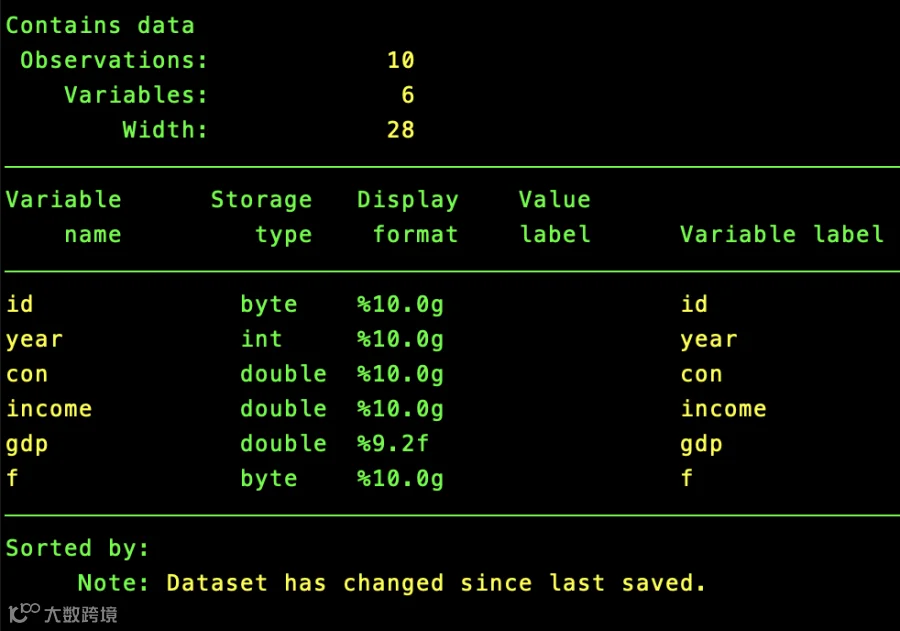
format gdp %9.2fdescribe gdp


summarize命令

基本用法:查看一个或多个变量的描述性统计信息
summarize con
summarize id year con income gdp f ,separator(3) //每3个变量画一条分界线,视觉更清晰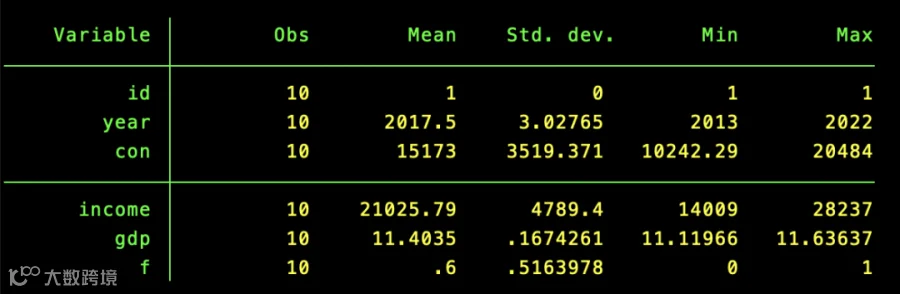
summarize con income, detail //显示con和income的细节情况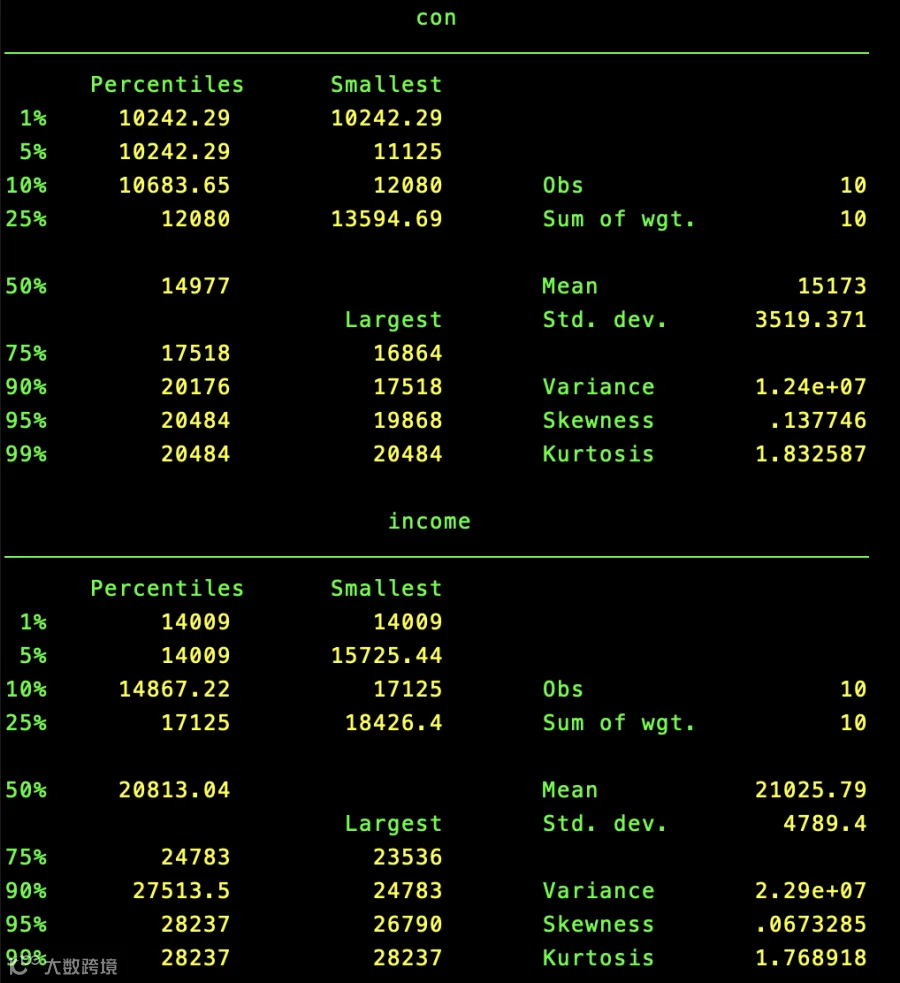
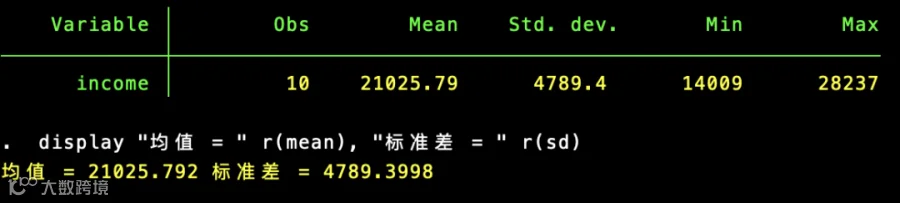
summarize income //计算统计量display "均值 = " r(mean), "标准差 = " r(sd) //展示统计量
*if子句:如果我们只想查看满足某个条件的数据的描述性统计量,可以使用 if命令。例如,查看 income 在大于2017年的描述性统计:
summarize income if year > 2017

tabulate命令

tabulate con,sort //通过sort排序并创建一维频数表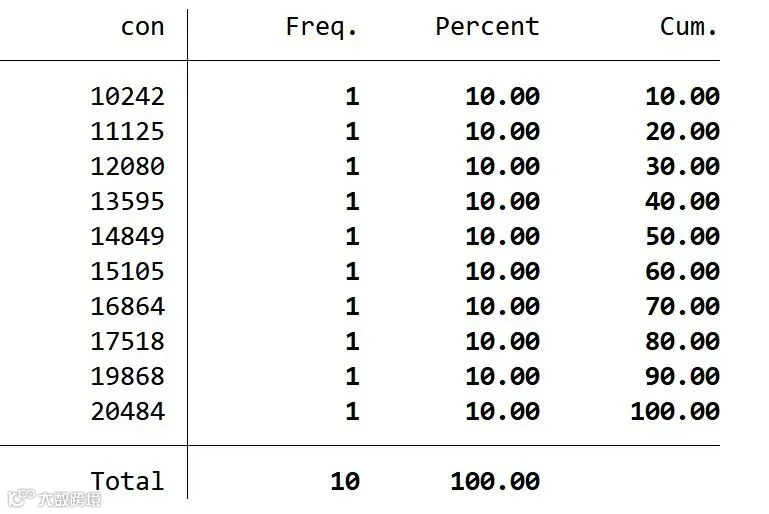
tabulate f, nolabel //显示原始数据,而不是其标签值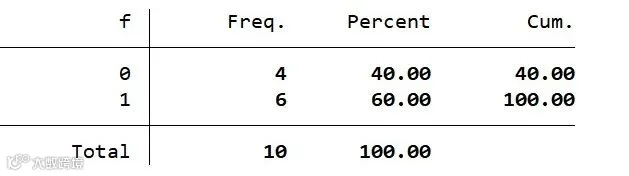
tabulate con income
高级技巧:
tabulate con, plot // 自动生成条形图,更加直观地理解频数分布。stata17版本以上tabulate income, nofreq // 只显示百分比tabulate con, matcell(frequency_matrix) // 把频数表存入名为frequency_matrix的矩阵中tabulate con income, chi2 expected // 卡方检验

导出结果

ssc install sum2docx //没有安装的话,先安装此命令sum2docx con income gdp f using myfile.docx, ///replace stats(N mean(%9.2f) sd(%9.2f) min(%9.4f) max(%9.4f)) ///landscape title("描述性统计") font("Times New Roman",14,"black") ///pagesize(A4)

重磅福利!为了更好地服务各位同学的研究,爬虫俱乐部将在小鹅通平台上持续提供金融研究所需要的各类指标,包括上市公司十大股东、股价崩盘、投资效率、融资约束、企业避税、分析师跟踪、净资产收益率、资产回报率、国际四大审计、托宾Q值、第一大股东持股比例、账面市值比、沪深A股上市公司研究常用控制变量等一系列深加工数据,基于各交易所信息披露的数据利用Stata在实现数据实时更新的同时还将不断上线更多的数据指标。我们以最前沿的数据处理技术、最好的服务质量、最大的诚意望能助力大家的研究工作!相关数据链接,请大家访问:(https://appbqiqpzi66527.h5.xiaoeknow.com/homepage/10)或扫描二维码:

对我们的推文累计打赏超过1000元,我们即可给您开具发票,发票类别为“咨询费”。用心做事,不负您的支持!
用Bokeh搞定大型数据集流式可视化,超实用!
探索 Stata 绘图:基于 S&P500 数据的可视化分析
Python Selenium爬取裁判文书网:从登录到批量下载全流程自动化
万物皆有方程组吗?——利用deepseek构建基于极坐标下的莲花曲线
爬虫俱乐部2025暑期Stata&Python编程训练营开始报名啦!
当Stata遇上周易:数据分析师的Cyber算命指南与玄学新副业
【Stata神技】Winsor2缩尾处理:3分钟拯救被"土豪"带偏的数据!
当川普遇到GPT——TimeGPT对川普币价格的时间序列预测分析
微信公众号“Stata and Python数据分析”分享实用的Stata、Python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
武汉字符串数据科技有限公司一直为广大用户提供数据采集和分析的服务工作,如果您有这方面的需求,请发邮件到statatraining@163.com。
此外,欢迎大家踊跃投稿,介绍一些关于Stata和Python的数据处理和分析技巧。
