
阅读说明
本文主要分为三个部分:基础概念、管道链、异步迭代器
其中基础概念这部分主要讲解 Node.js Stream 是什么,以及内部的工作原理。并附有动画来演示内部工作流程,可以帮助您更清晰的了解不同的流的工作方式以及差别。
如果对基础概念已经有了一个较为清晰的了解,则可以直接看第二及第三部分,将第一部分作为参考来阅读。而管道链这一章则以“动画”+“Demo”的方式来演示 pipe 与 pipeline 的差别。
异步迭代器这部分则为本文的重点部分,本部分主要以Demo代码演示为主,可以让你更快的了解到如何使用异步迭代器 Async Iterator 取代 Stream。
流的基本概念
什么是流?
在计算机处理任务的过程中,通常会把数据加载到内存中,但是当数据过大时,不可能把所有数据都放在内存里。另一个重要的原因是内存的IO速度高于HD和网络的IO速度,又不能让内存一直处于 pending 状态,所以需要缓冲区和 Stream。例如,文件大小可能大于 Node.js 默认缓冲区大小,从而无法将整个文件读入内存以进行处理。
这时就需要一种方法来分段处理数据,而最理想的结果是有序地加载一点,处理一点。所以你可以把流 Stream 理解为——有序的数据块处理过程。
对比其他数据处理的方式,流带来的好处在于无需在内存中加载大量数据,也无需等待所有数据加载到内存后才开始执行处理过程。所以流数据的处理具有以下两个特点:
节约内存:无需先在内存中加载大量数据,然后再进行处理
提升时效:无需等待数据全部加载完成后才能开始处理,在第一个分段数据就可以开始处理数据,这可以极大提升数据处理时效
流有什么作用?
一般来说,使用流来处理大型数据或者是流媒体是比较常见的应用场景。以视频网站或者音乐平台这类流媒体来举例,比方说在你打开一个视频的时候,并不是等待整个视频完整下载完后才开始播放,而是以一种连续数据库的形式接收这些数据,所以从你点击播放的那一刻你就可以开始观看而无需等待。
而流这种有序数据块的处理过程的设计也给我们提供了代码的“可组合性”。你可以想象它为“生产流水线”,一个完整的数据可以被拆分成不同的小块分段加工,就像是生产线单向将原材料传送通过各个加工环节后得到最终产品。
在构建较复杂的系统时,通常将其拆解为功能独立的若干部分,这些部分的接口遵循一定的规范,通过某种方式相连,以共同完成较复杂的任务。
Node.js中常用的流的实现
在 Node.js 生态中,许多内置模块都实现了流接口,以下是对常见的流的记录:

图片来源:Freecodecamp
Node.js Stream 的基本概念
Node.js 中有四种基本的流类型:
Writable - 可写入数据的流(例如 fs.createWriteStream()让我们以流的形式将数据写入文件)。
Readable - 可读取数据的流(例如 fs.createReadStream()让我们以流的形式从文件中读取数据)。
Duplex - 可读又可写的流(例如 net.Socket)。
Transform - 在读写过程中可以修改或转换数据的 Duplex 流,转换流(Transform)也是一种 Duplex 流,但它的输出与输入是相关联的。与 Duplex 流一样, Transform 流也同时实现了 Readable 和 Writable 接口。(例如 zlib.createDeflate())。
除了流的基本类型,还需要了解以下流的特点:
事件:所有流都是 EventEmitter 的实例,所以不同的流也具有不同的事件,事件也就是告知外界自己自身的工作状态的方式。
独立缓冲区:可读流和可写流都有自己的独立缓冲区,而双工流和转换流是同时实现了可读流与可写流,则内部会同时有可读流缓冲区与可写流缓冲区。
字符编码:而我们通常在进行文件读写时,操作的其实是字节流,所以在设置流参数 options 时需要注意编码格式,这是会影响 chunk 的内容和大小。而可读流与可写流默认的编码格式并不同,而每种不同的流也都不相同,所以在使用流操作前一定要先看默认参数设定,以免发生数据积压问题。
1 // fs.createReadStream 默认 encoding为 null
2 const readableStream = fs.createReadStream(smallFile, { encoding: 'utf-8', highWaterMark: 1 * 256 });
3 /**
4 * 1. fs.createWriteStream 默认encoding为utf-8, 但是如果在创建时不设置,则具体encoding 以实际write()时写入数据为准
5 * 2. 可以通过writable.setDefaultEncoding(encoding)去设置,效果同上
6 * 3. 如果设置了默认的encoding,则写入时只可以写入指定类型
7 * 4. 编码类型直接影响字节数,如果以下代码不设置,则会影响write()方法写入压缩数据(导致写入文件字节数与定义highWaterMark不符合预期)
8 */
9 const writeableStream = fs.createWriteStream(upperFile, { encoding: 'utf-8', highWaterMark: 1 * 25 });
10 // 读取文件的内容chunk size 远大于 可写流一次写入的字节的大小,所以会触发 'drain' 事件以等待排空积压在可写流缓冲器中的数据
highWaterMark:可读流和可写流都会在内部的缓冲器中存储数据,对于非对象流来说,highWaterMark 指定了字节的总数。实际上 highWaterMark 只是一个阈值,它并不会限制写入缓冲的数据大小,除非直接突破 Node.js 缓冲区最大值。这里要明确一件事,数据是被缓冲,而不是缓存。缓冲(Buffer)与缓存(Cache)的区别可以看这篇文章
可读流
可读流的两种模式
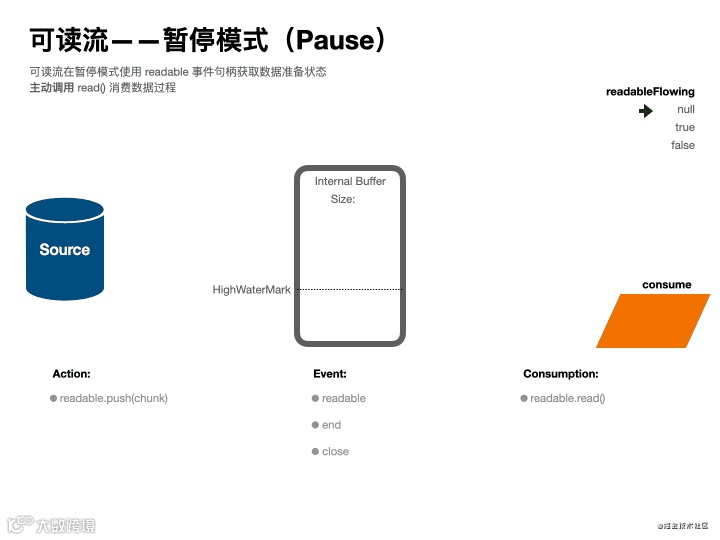
根据上述“生产流水线”的描述,可以了解到,作为源头的可读流有两个工作模式:流动(flowing) 和 暂停(paused),你可以理解为被动消费模式和主动消费模式,他们的不同点在于获取数据消费的方式不同。
在流动模式中,数据自动从底层系统读取,并通过 EventEmitter 接口的事件尽可能快地被提供给应用程序。
在暂停模式中,数据会堆积在内部缓冲器中,必须显式调用 stream.read() 读取数据块。
所有可读流都开始于暂停模式,可以通过以下方式切换到流动模式:
添加 'data' 事件句柄。
调用 stream.resume() 方法。
调用 stream.pipe() 方法将数据发送到可写流。
可读流可以通过以下方式切换回暂停模式:
如果没有管道目标,则调用 stream.pause()。
如果有管道目标,则移除所有管道目标。调用 stream.unpipe() 可以移除多个管道目标。
默认情况下,所有可读流均以暂停模式开始,但可以很轻易地将其切换为流动模式,如有必要也可以在两种模式中来回切换。当可读流处于暂停模式时,我们可以使用 read() 方法按需从流中读取数据。但是,在流动模式下,数据会一直不断地被读取,如果没有及时消费数据,则可能丢失数据。所以在流动模式中,我们需要通过 'data' 事件来获取并处理数据。
流动模式动画演示
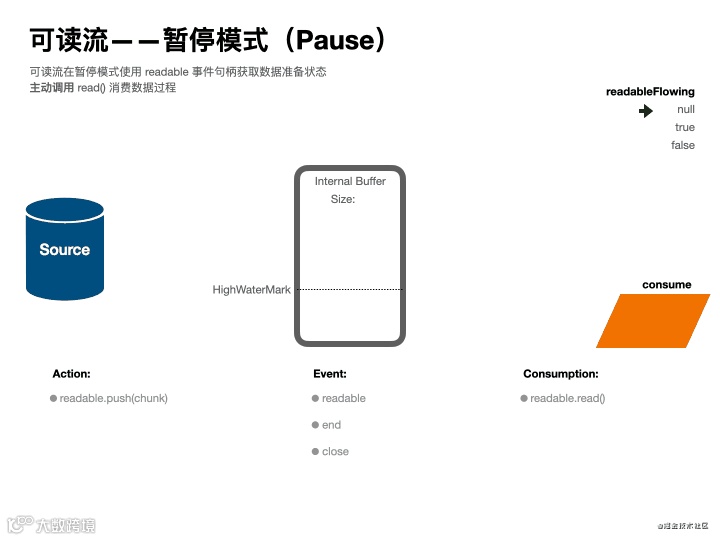
暂停模式动画演示
可读流事件要点解读
可读流事件中,需要重点了解用来读取可写流中的数据的两个事件:
Event: 'data' 【流动模式】 当 'data' 事件被添加后,可写流中有数据后会将数据推到该事件回调函数中,你需要自己去消费数据块,如果不处理则该数据会丢失。[如果不手动切换可读流状态为暂停模式 paused,则一直处于流动模式 flowing,数据会不断传入直到可读数据全部被读取]
Event: 'readable' 【暂停模式】 <主动消费>可写流在数据准备好后会触发该事件回调,此时需要在回调函数中使用 stream.read() 来主动消费数据。[在暂停模式中,多次 stream.push() 后一次性使用 stream.read() 读取,则会将当前缓冲区数据合并读取。]
'readable' 事件表明流有新的动态:要么有新的数据,要么流已经读取所有数据。对于前者,stream.read() 会返回可用的数据。对于后者,stream.read() 会返回 null。
在 Node.js 中,可读流和可写流都会在内部的缓冲器中存储数据 ,所以当可读流不断地把数据一直塞给可写流很可能会导致可写流内部缓冲数据流积压(Backpressure)。
所以当使用 'data' 事件时,数据读取的速度和下游消费速率不一致,则很容易造成数据流积压问题从而影响性能。而当数据量非常大时,使用 'readable' 事件则它会自动切换可读流模式所以可以带来更好的性能,但是相应的它也比 'data' 事件更难理解。
1 // 👨🏫 知识点:readable 和 data 事件同时存在,readable 事件会抢占 data 事件控制权,只有在 read() 之后,数据会流向 data 事件
2 readableStream.on('readable', function (this: any) {
3 // paused
4 let chunk;
5 while ((chunk = readableStream.read() !== null)) {
6 // flowing
7 // do something
8 }
9 // 当 readableStream.read() 为 null 时,则表示不再有新的数据
10 });
11 readableStream.on('end', () => {
12 console.log('已没有数据');
13 });
对比理解一下 'data' 事件的使用
1 // 👨🏫 知识点:添加 'data' 事件,触发可读流模式切换 paused --> flowing
2 readableStream.on('data', (chunk: string) => {
3 // 📌如果有必要,需要手动,切换流状态暂停
4 readableStream.pause();
5 // do something
6 if (whenYouDone) {
7 // 📌恢复流动
8 readableStream.resume();
9 }
10 });
11 readableStream.on('end', () => {
12 console.log('已没有数据');
13 });
注意,目前这里讨论是是单独使用可读流的情况,如果要涉及到组合使用,不建议使用事件的方式,接下来会讲到使用管道组合形成管道链的方式。
数据积压动画演示

可写流
可写流相比可读流,其实要好容易理解的多得多得多,可以认为它就是“生产线”的末端,负责将最终的引导向最终目的地。
可写流事件要点解读
可写流事件中,需要重点了解可写流如何处理写入速度与读取速度不一致时,会用到的事件:
Event: 'drain' 如果调用 stream.write(chunk) 时返回 false,则表示当前缓冲区数据已经大于或等于可写流的 highWaterMark 的值,当可以继续写入数据到流时会触发 'drain' 事件。
这里可能不太好理解,可以把可写流想象成一个漏斗,我们给漏斗上标记了一个刻度,如果 水位 < 刻度 则说明此时处于安全的状态,可以继续进行。而当 水位 ≥ 刻度 则说明此时不建议继续灌水,要等我把当前漏斗内的水排空后,我通过 drain 事件通知你继续。
注意我上面的用词,这也是 Stream 让人迷惑的地方,可写流的 highWaterMark 仅仅是起到警示作用,或者说,Stream 并没有强制流的开发者必须让控制积压。所以我们还是可以忽视 stream.write(chunk) === false 不断调用 stream.write(chunk) 写入数据。而未被处理的数据会一直积压在可写流的内部缓冲区中,直到积压沾满 Node.js 缓冲区后,才会被强行中断。
补充:编程语言在设计的时候会考虑到设备的物理特性,从而会设定一些”安全限制“。比如 Node.js 的默认缓冲区(Buffer)就根据不同设备架构而有不同的大小。
On 32-bit architectures, this value currently is 2^30 - 1 (~1GB).On 64-bit architectures, this value currently is 2^31 - 1 (~2GB)
再回到可写流中,在之前说过流都有自己的独立缓冲区,当可写流内部的可写缓冲的总大小小于 highWaterMark 设置的阈值时,调用 writeableStream.write() 会返回 true。一旦内部缓冲的大小达到或超过 highWaterMark 时,则会返回 false。如果是通过事件手动操作的话,则需要手动暂停可写流,直到可写流触发 'drain' 事件后再开启。
1 // 👨🏫 知识点:添加 'data' 事件,触发可读流模式切换 paused --> flowing
2 readableStream.on('data', (chunk: string) => {
3 // 📌切换流状态暂停
4 readableStream.pause();
5 // 如果 水位 ≥ 刻度 则会返回false,需要等待drain事件
6 const writeResult = writeableStream.write(chunk, (err) => {
7 if (err) {
8 console.error('写入错误:', err);
9 process.exitCode = 1;
10 }
11 });
12 if (writeResult) {
13 // 📌恢复流动
14 readableStream.resume();
15 }
16 });
17
18 // 如果writeableStream.write()写入字节数大于可写流highWaterMark,则会触发drain事件
19 writeableStream.on('drain', function () {
20 console.log(chalk.gray('可写流drain'));
21 // 📌恢复流动
22 readableStream.resume();
23 });
可写流动画演示

双工流与转换流
其实只要明白了可读流与可写流的工作方式,则很好理解双工流与转换流。双工流 Duplex 与转换流 Transform 都是同时实现了 Readable 和 Writable 接口的流,也可以说转换流是一种特殊的双工流。具体区别是:可以将双工流视为具有可写流的可读流。两者都是独立的,每个都有独立的内部缓冲区,读写事件独立发生。而转换流也是双工的,其中读写有顺序要求的,写事件发生后才可以读。
1 Duplex Stream
2 ------------------|
3 Read <----- External Source
4 You ------------------|
5 Write -----> External Sink
6 ------------------|
7 You don't get what you write. It is sent to another source.
8
9 Transform Stream
10 --------------|--------------
11 You Write ----> ----> Read You
12 --------------|--------------
13 You write something, it is transformed, then you read something.
比如 Socket 模块就是一个非常典型的双工流(Duplex ),在 Socket 接收消息的同时也可以通过写入发送消息,而“读、写”并没有关系。而转换流则与其相反,适用于一些有先后执行顺序的环节,而实现 Transform 需要实现 transform() 方法,该方法表示数据的中转。
管道链
理解流的组合
仔细阅读以下内容,这可以帮助你更好的理解并使用流。上文我们提到过,可以把流想象成“生产流水线”,那可以认为管道链相当于是生产线上组合了不同的任务单元的强大生产流水线。

图片来源:Google 搜索(源自搜狐文章)
那则可以认为当创建一条生产线后,只是定义了该生产线的工作目的(规定了上游(可读流)从哪开始,而下游(可写流)需要谁来处理),而此时生产线并未启动。而可读流作为生产的源头,生产线也会因为上游原材料消耗殆尽后而关闭,不可能生产线一直处于运行状态。
所以生产线的源头需要有一个开关来控制运行状态,而且如果下游处理比较慢,需要先暂停等待下游处理完成后再开启,这样以确保不必要的生产事故。而该上游没有输入后需要关闭并通知下游,但是并不意味着整条流水线的其他任务单元都也完成了自己的任务。所以每个处理单元都是独立的,也都有自己的响应事件。所以如果其中一个处理单元出了故障,作为管理员应该立即让整条生产线停止,以免造成损失。
所以当组合不同的流时,不仅需要关注源头,也需要关注每个生产单元是否正常工作。但当这个“生产流水线”足够复杂的时候,“关注一切”并不是一个好主意,可能会给开发者造成很多心智负担,而这时需要一个更为高效并且现代的处理方式。
完全使用事件回调的方式操作流,相当于是手动模式,不仅低效,而且大大增加了出错的概率。而Nodejs也提供了半自动模式,也就是接下来要讲的pipe,这也是官方所推荐的消费流数据的方式。而随着 Node.js 的发展,现在有了更棒的 全自动模式——pipeline 。当然如果对数据有更精细的操作,确实也可以通过混用事件与管道的方式,但是要注意可能会导致不明确的行为。
pipe管道与管道链
一个可读流的管道连接的是一个可写流,如果想要用多个(>2)管道组合来处理流,需要使用 Duplex 流或 Transform 流组合形成管道链。
还以上面的代码举例,为了让他更复杂一点,又添加一个压缩的处理单元和一个“故障单元”(模拟管道链中间段出错)。
1 import * as path from 'path';
2 import * as fs from 'fs';
3 import * as chalk from 'chalk';
4 import { createGzip } from 'zlib';
5 import { Transform } from 'stream';
6
7 // 改写之前的写入写入准备文件代码,得到一个1KB大小的文件
8 const smallFile = path.join(__dirname, '../../temp/1KB.txt');
9 const upperFile = path.join(__dirname, '../../temp/upper_text_pipe.gz');
10
11 const readableStream = fs.createReadStream(smallFile, { encoding: 'utf-8', highWaterMark: 1 * 256 });
12 const writeableStream = fs.createWriteStream(upperFile, { encoding: 'utf-8', highWaterMark: 1 * 10 }); // 修改小是为了触发drain
13
14 const upperCaseTr = new Transform({
15 transform(chunk, encoding, callback) {
16 console.log('chunk', chunk);
17 this.push(chunk.toString().toUpperCase());
18 // 故障
19 callback(new Error('error'));
20 },
21 });
22
23 // 组合管道链
24 readableStream.pipe(createGzip()).pipe(upperCaseTr).pipe(writeableStream);
25
26 upperCaseTr.on('error', (err) => {
27 console.log('upperCaseTr error', err);
28 // 如果中间段出错,应该关闭管道链其他流
29 writeableStream.destroy();
30 readableStream.destroy();
31 });
32
33 // end
34 readableStream.on('end', function () {
35 console.log(chalk.redBright('可读流end'));
36 });
37
38 // close
39 readableStream.on('close', function () {
40 console.error('可读流close');
41 });
42
43 readableStream.on('data', (chunk: string) => {
44 console.log(chalk.green('压缩前--->', Buffer.byteLength(chunk)));
45 });
46
47 writeableStream.on('drain', function () {
48 console.log(chalk.gray('可写流drain'));
49 });
50
51 writeableStream.on('close', function () {
52 console.log(chalk.redBright('可写流close'));
53 });
54
55 writeableStream.on('finish', function () {
56 console.log(chalk.redBright('可写流finish'));
57 });
58
59 writeableStream.on('error', function (err) {
60 console.error('可写流error', err);
61 });
通过上面的代码可以看到,所以如果需要组合不同的流,使用事件是一件很繁琐的事,你需要关注每一个流的状态,然后还需要根据不同的事件做不同的处理。上面的代码只是简单的一个可读流组合一个可写流,如果再多组合一些,复杂度会成倍增长。
而且这种方式很难使用 Promise,这对于今天的前端开发工作来说,是十分不好的体验。对于管道链来说,任何一个处理单元出错后,整条正产线都应该停下。
pipe动画演示

更加实际的例子
说明:创建一个Node Server,该服务需要访问一个本地一个较大的文件,并传送给前端:
1 import * as fs from 'fs';
2 import { createServer } from 'http';
3 import * as path from 'path';
4
5 const server = createServer();
6
7 server.on('request', async (req, res) => {
8 // `req` is an http.IncomingMessage, which is a readable stream.
9 // `res` is an http.ServerResponse, which is a writable stream.
10 const readableStream = fs.createReadStream(path.join(__dirname, '../../../temp/big.txt'));
11
12 readableStream.pipe(res);
13
14 readableStream.on('close', () => {
15 console.log('readableStream close');
16 });
17 res.on('close', () => {
18 console.log('response close');
19 });
20 res.on('end', () => {
21 console.log('response end');
22 });
23 });
24
25 server.listen(8000);
如果用户端浏览器关闭,但传输并未完成,则从理论上应该认为传输过程应该停止。但是使用 pipe 并不会帮你处理这一环节,你需要监听 res.on('error') 事件来帮助你判断是否该停止可读流。
总结pipe
源码位置
仅提供了数据管理,避免出现读写速度不一致的情况,有效避免数据积压
处理管道链的流的错误非常麻烦
如果可读流在处理期间发送错误,则可写流目标不会自动关闭。如果发生错误,则需要手动关闭每个流以防止内存泄漏。
无法得知管道完整的状态(是否已经结束)
使用pipeline代替pipe
直到 Node.js@V10.0.0 版本的发布,才带来了 pipeline ,而对于消费方来说,官方直接建议使用 pipeline 来替代 pipe 以确保安全。

图片来源:Node.js 官方文档截图
使用 pipeline 改造上文中的Demo代码
1 import * as fs from 'fs';
2 import { createServer } from 'http';
3 import * as path from 'path';
4 import { pipeline } from 'stream';
5
6 const server = createServer();
7
8 server.on('request', async (req, res) => {
9 // `req` is an http.IncomingMessage, which is a readable stream.
10 // `res` is an http.ServerResponse, which is a writable stream.
11 const readableStream = fs.createReadStream(path.join(__dirname, '../../../temp/big.txt'));
12
13 pipeline(readableStream, res, (error) => {
14 console.log('pipeline', error);
15 });
16 readableStream.on('close', () => {
17 console.log('readableStream close');
18 });
19 res.on('close', () => {
20 console.log('response close');
21 });
22 res.on('end', () => {
23 console.log('response end');
24 });
25 });
26
27 server.listen(8000);
运行结果可以看到,如果发生了错误,pipeline 会将管道链上所有流关闭,这也代表着该管道链的关闭,而通过回调来的方式来监控管道链状态相比 pipe 的方式也更加容易使用。
总结pipeline
源码位置
提供了数据管理,避免出现读写速度不一致的情况,有效避免数据积压
很容易处理管道链报错
如果可读流在处理期间发送错误,则当前管道链所有流都将关闭,避免内存泄漏。
管道链有自己的运行状态,更容易理解。
回顾一下Node.js Stream
通过上面的介绍,相信大家已经对流有了一个较为全面的了解,我们了解了 Node.js Stream 的基本概念,也了解到如何组合使用 Stream 和使用 pipeline 的方式更安全高效的组合管道链。
但是 Stream 依然有较为高的学习和使用成本,即使大部分 Node.js 的模块已经封装好了这些功能,但是对于想要自己实现 Stream 来说,依旧很麻烦。而有了 pipeline 后,仅方便了我们组合流使用管道链的问题,对于流来说,使用依旧麻烦。
比如当你仅需要可读流来读取数据,而并不需要进行其他操作,则操作可读流这一过程也可能会有报错或者是其他问题,所以当你没办法使用 pipeline 时,你还是得通过事件来操作。但是这就也说明,Stream 并不能很愉快的使用 Promise,当然也无法使用 async/await 这种我们更加熟悉的开发方式。
那该如何提升 Stream 在 Node.js 中的开发体验呢?接下来使用异步迭代器 Async Iterator 来实现 Stream。
异步迭代器Async Iterator与流Stream
什么是异步迭代器?
简单来说就是使用async/await的方式循环迭代器的过程,理解以下这段代码:
1 async function* generator() {
2 yield "aaa"
3 }
4
5 for await (let chunk of generator()) {
6 chunk.toUpperCase();
7 }
这不是本文的重点,所以如果对概念不是很熟悉,可以看以下的文章参考:
异步迭代器
For await ... of MDN
异步迭代器与可读流
在使用可读流的过程中,可读流读取数据的过程有点类似从一个数组中取数据的过程。假设这个数组就是可读流的数据源,那么只需要有序地一个一个地将内容读出来,也就实现了可读流的工作模型。
首先实现一个可读流作为我们的参照组:
1 import { Readable } from 'stream';
2
3 const array = [];
4 for (let i = 0; i < 1024; i++) {
5 array.push(i);
6 }
7
8 const readableStream = new Readable({
9 objectMode: true,
10 read() {
11 for (let i = 0; i <= array.length; i++) {
12 readableStream.push(i);
13 }
14 readableStream.push(null);
15 },
16 });
17
18 readableStream.on('data', (chunk) => {
19 console.log(chunk);
20 });
使用Readable.from()转化数组为可读流
Node.js 12 提供了一个内置方法 stream.Readable.from(iterable, [options]) 可以将迭代器或可迭代对象创建为可读流。
1 import { Readable } from 'stream';
2
3 const array = [];
4 for (let i = 0; i < 1024; i++) {
5 array.push(i);
6 }
7
8 const readableStream = Readable.from(array);
9
10 readableStream.on('data', (chunk) => {
11 console.log(chunk);
12 });
运行结果和上文可读流参照组结果一致。
使用generator可迭代对象
由上面的API可知,Readable.from 对象可以接受一个迭代器的话,那么可以a === b --> b === c 推断出:a === c 这个关系🤔。
则有:
1 import { Readable } from 'stream';
2
3 function* generator() {
4 for (let i = 0; i < 1024; i++) {
5 yield i;
6 }
7 }
8
9 const readableStream = Readable.from(generator());
10
11 readableStream.on('data', (chunk) => {
12 console.log(chunk);
13 });
运行结果和上文可读流参照组结果一致。
异步迭代器
1 import { Readable } from 'stream';
2
3 // or: function* generator()
4 async function* generator() {
5 for (let i = 0; i < 1024; i++) {
6 yield i;
7 }
8 }
9
10 const readableStream = Readable.from(generator());
11
12 async function run() {
13 for await (let chunk of readableStream) {
14 console.log(chunk);
15 }
16 }
17
18 run();
由于:for...of语句在可迭代对象(包括 Array,Map,Set,String,TypedArray,arguments 对象等等)上创建一个迭代循环,调用自定义迭代钩子,并为每个不同属性的值执行语句。则可以直接迭代 generator 函数,可以有同样的效果:
1 import { Readable } from 'stream';
2 import { promisify } from 'util';
3 const sleep = promisify(setTimeout);
4
5 // or: function* generator()
6 async function* generator() {
7 for (let i = 0; i < 1024; i++) {
8 yield i;
9 }
10 }
11
12 async function run() {
13 for await (let chunk of generator()) {
14 console.log(chunk);
15 await sleep(1000);
16 }
17 }
18
19 run();
如果需要使generator具有Stream的特性,则最好使用 Readable.from() 将其转换为可读流,这样就可以拥有流的特性。
异步迭代器与转换流Transform
如果我们需要组合多个流,前面也说了,最好的方式是使用pipeline。那使用异步迭代器创建的可读流可以组合进 pipeline 中,是不是也可以使用同样的方式创建中间执行单元呢?以转换流举例:
1 import { Readable, Transform, pipeline } from 'stream';
2 import { createWriteStream } from 'fs';
3
4 async function* generate() {
5 for (let i = 0; i < 1024; i++) {
6 yield i;
7 }
8 }
9
10 async function* transform(source: Readable) {
11 for await (let chunk of source) {
12 yield chunk.toString().toUpperCase();
13 }
14 }
15 const readableStream = Readable.from(generate());
16
17 pipeline(
18 readableStream,
19 Transform.by(transform), // 还未正式支持
20 createWriteStream(''),
21 (error) => {
22 console.log(error);
23 }
24 );
我们知道转换流的实现是需要实现 transform 函数,上面也讲过转换流的工作原理,则可以认为通过异步迭代器是可以完成这种实现的。不过该方式还暂未被Node.js 所实现,可能在 Node.js@15 以后的版本会有实现。
可写流
非常抱歉,可写流暂时还未能很好的使用异步迭代器,不过可写流也相对来说简单很多。唯一需要注意的就是 'drain' 事件避免数据积压。那么可以结合 Promise 对可写流进行包装,这也是常用的方式。
1 import Stream, { Readable, Writable } from 'stream';
2 import { promisify } from 'util';
3 import { once } from 'events';
4
5 const finished = promisify(Stream.finished);
6
7 const myWritable = new Writable({
8 highWaterMark: 4,
9 objectMode: true,
10 defaultEncoding: 'utf-8', // write() 默认编码
11 write(chunk, encoding, callback) {
12 console.log('myWritable write:', chunk.toString());
13 console.log('myWritableLength:', myWritable.writableLength); // 放在callback()调用之前
14 // setTimeout(() => { // 模拟异步
15 if (chunk.toString() === '123') {
16 return callback(new Error('写入出错'));
17 }
18 callback();
19 // }, 0);
20 },
21 });
22
23 async function* generator() {
24 for (let i = 0; i < 1024; i++) {
25 yield i;
26 }
27 }
28
29 const readableStream = Readable.from(generator());
30
31 readableStream.on('close', () => {
32 console.log('readableStream close');
33 });
34
35 myWritable.on('close', () => {
36 console.log('myWritable close');
37 });
38
39 async function run() {
40 try {
41 const write = buildWrite(myWritable);
42
43 for await (let chunk of readableStream) {
44 console.log(chunk);
45 const writeResult = await write(chunk);
46 console.log('--->', writeResult);
47 }
48 await finished(readableStream);
49 } catch (error) {
50 console.log(error);
51 }
52 }
53
54 // 可写流的包装
55 function buildWrite(stream: Writable) {
56 let streamError: any = null;
57 // 可写流需要通过 error 事件来捕获错误
58 stream.on('error', (error) => {
59 streamError = error;
60 });
61 return function (chunk: Buffer) {
62 if (streamError) {
63 return Promise.reject(streamError);
64 }
65 const res = stream.write(chunk);
66 if (res) {
67 return Promise.resolve(true);
68 }
69 return once(stream, 'drain');
70 };
71 }
72
73 run();
可以运行上面的代码,观察可写流运行结果。
总结一下
看到这里,也到了文章该结束的时候了,接下来总结一下在2021年该如何拥抱 Node.js Stream。
通过上面所有的内容,可以了解到 Node.js Stream 已经开始全面拥抱异步迭代器,但是这还是需要一个过程才能实现全面拥抱。而异步迭代器不仅大大降低了使用 Stream 的成本,也在使用上也更加符合现代开发的习惯。
在 Node.js@12 以后可读流可以使用
Readable.from() 直接将迭代器或可迭代对象创建为可读流,这个 API 带来的是对可读流的简化。同时从代码的可组合性来说,也可以带来更多的玩法。
不过到 Node.js@14 为止,双工流、转换流和可写流还并未支持这种特性,期待在 Node.js@15 可以发布这些支持的 API 来让管道链也全面拥抱异步迭代器。
而 pipeline 的出现,它的到来和 pipe 一样有自动数据管理能力,也在一定程度上降低了管道链的使用复杂度(对比原 pipe 的方式),同时大大简化了错误处理方式并且可以自动关闭管道链上的所有 Stream 处理单元。
简单说就是:
使用 pipeline 替代 pipe
可读流可以使用 Readable.from() 直接创建
使用 Promise 包装可写流避免数据积压问题
可以使用异步迭代器消费可读流(异步迭代器可以迭代可迭代对象和迭代器,同时也可以迭代可读流)
最后,真心希望如果有疑问如果文章有错误或者有疑问,欢迎在评论区指出一起讨论,指出错误不仅可以帮助我纠正认知也可以帮助你理解。如果有什么问题可以联系我。
参考
理解 Node.js Stream
通过异步迭代简化Node.js流
Node stream 你需要知道的一切
双工 Duplex更好的理解Buffer
pipeline 代替promise.all
node stream 演讲视频
关注我们
扫二维码
