
1. 腾讯开源混元OCR
腾讯刚刚开源最新原生端到端OCR:HunyuanOCR,1B,OmniDocBench得分94.1,超DeepSeek OCR、Gemini 3 Pro.功能覆盖文本检测、复杂文档处理、视频字幕提取、端到端照片翻译等全场景;文本检测,支持街景、手写、艺术字、广告、票据、截屏等等;复杂文档处理,表格/公式直接输出 HTML/LaTeX;端到端照片翻译支持14种语言
HunyuanOCR是一款基于腾讯混元原生多模态架构的端到端OCR专家模型。仅以1B轻量化参数,便已斩获多项业界SOTA成绩。该模型精通复杂多语种文档解析,同时在文字检测识别、开放字段信息抽取、视频字幕识别、拍照翻译等全场景实用技能中表现出色。
✨ 核心特点 💪 轻量化架构:基于混元原生多模态架构与训练策略,打造仅1B参数的OCR专项模型,大幅降低部署成本。
📑 全场景功能:单一模型覆盖文字检测和识别、复杂文档解析、卡证票据字段抽取、字幕提取等OCR经典任务,更支持端到端拍照翻译与文档问答。
🚀 极致易用:深度贯彻大模型"端到端"理念,单一指令、单次推理直达SOTA结果,较业界级联方案更高效便捷。
🌏 多语种支持:支持超过100种语言,在单语种和混合语言场景下均表现出色。

项目地址
https://github.com/Tencent-Hunyuan/HunyuanOCR https://huggingface.co/tencent/HunyuanOCR
2. DeepSeeckOCR客户端
为 DeepSeek-OCR 识别模型开发了一个开箱即用的桌面客户端。只需拖拽上传图片,即可快速识别其中文字内容,还能点击指定区域直接复制文字。 同时,还支持导出为 ZIP 文件,包含 Markdown 和图片,以及支持 GPU 加速,大幅提升处理速度。 目前工具主要支持 Windows 系统,在发布页面下载文件解压后即可使用,首次运行会自动安装依赖。
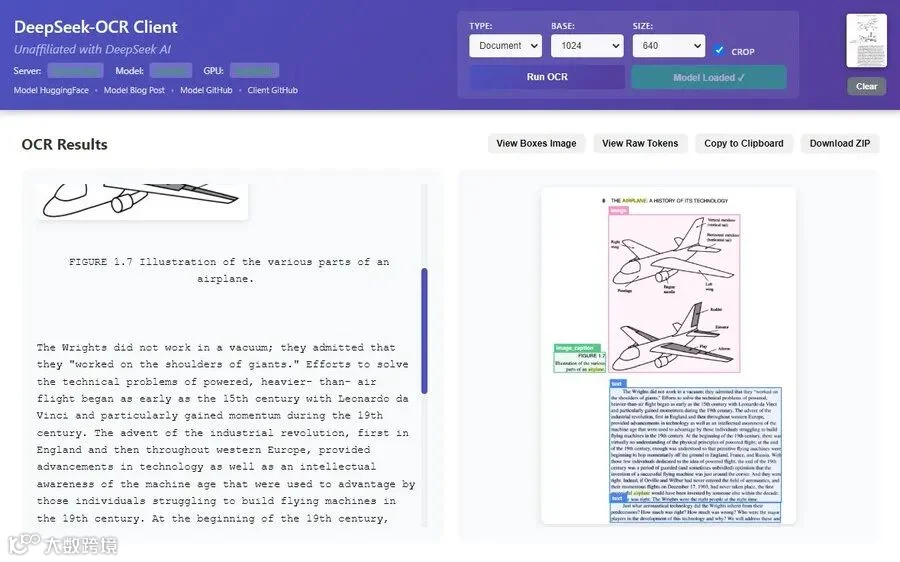
项目地址
GitHub:http://github.com/ihatecsv/deepseek-ocr-client
扫码加入技术交流群,备注「开发语言-城市-昵称」
合作请注明
如果你觉得这篇文章不错,别忘了点赞、在看、转发给更多需要的小伙伴哦!我们下期再见!