


点击上方蓝字关注我们

主要内容
News Watch
💡💡💡我们引入了一种名为频率动态卷积(FDConv)的创新方法,通过在傅里叶域中学习固定参数预算来缓解这些问题。FDConv 将这些预算分配到具有不相交傅里叶索引的频率组中,从而能够在不增加参数成本的情况下构建频率多样的权重。
💡💡💡大量在目标检测、分割和分类任务上的实验验证了 FDConv 的有效性。我们证明,当应用于 ResNet-50 时,FDConv 仅需小幅增加 +3.6M 参数,就能取得优于以往方法(例如 CondConv 增加 90M、KW 增加 76.5M 参数)的性能。此外,FDConv 能够无缝集成到多种架构中,包括 ConvNeXt 和 Swin-Transformer,为现代视觉任务提供了一种灵活且高效的解决方案。
改进结构图如下:

YOLOv8-Pose关键点检测专栏介绍:http://t.csdnimg.cn/gRW1b
✨✨✨手把手教你从数据标记到生成适合Yolov8-pose的yolo数据集;
🚀🚀🚀模型性能提升、pose模式部署能力;
🍉🍉🍉应用范围:工业工件定位、人脸、摔倒检测等支持各个关键点检测;


论文:https://arxiv.org/pdf/2503.18783
摘要:尽管动态卷积(DY-Conv)通过结合多个并行权重和注意力机制实现自适应的权重选择并展现出色性能,但这些权重的频率响应往往具有较高的相似性,从而导致参数成本高昂,但适应性有限。在本文中,我们引入了一种名为频率动态卷积(FDConv)的创新方法,通过在傅里叶域中学习固定参数预算来缓解这些问题。FDConv 将这些预算分配到具有不相交傅里叶索引的频率组中,从而能够在不增加参数成本的情况下构建频率多样的权重。 为了进一步增强适应性,我们提出核空间调制(KSM)和频率带调制(FBM)。KSM 在空间层面上动态调整每个滤波器的频率响应,而 FBM 则在频域中将权重分解为不同的频率带,并根据局部内容动态调制这些频率带。大量在目标检测、分割和分类任务上的实验验证了 FDConv 的有效性。我们证明,当应用于 ResNet-50 时,FDConv 仅需小幅增加 +3.6M 参数,就能取得优于以往方法(例如 CondConv 增加 90M、KW 增加 76.5M 参数)的性能。此外,FDConv 能够无缝集成到多种架构中,包括 ConvNeXt 和 Swin-Transformer,为现代视觉任务提供了一种灵活且高效的解决方案。

• 我们对基于频率分析的动态卷积进行了全面的探索。研究发现,传统动态卷积方法的参数在频率响应方面呈现出高度的同质性,导致参数冗余度高且适应性有限。
• 我们引入了傅里叶不相交权重(FDW)、核空间调制(KSM)和频率带调制(FBM)策略。FDW 在不增加参数成本的情况下构建了具有多样化频率响应的多个权重,KSM 通过逐元素调整权重增强了表示能力,而 FBM 则通过精确地以空间变化的方式提取频率带改进了卷积。
• 我们表明,我们的方法可以轻松地集成到现有的卷积神经网络(ConvNets)和视觉变换器中。在分割任务上的全面实验表明,它超越了以往最先进的动态卷积方法,仅需小幅增加参数,始终如一地展示了其有效性。
图 2 展示了所提出的频率动态卷积(FDConv)框架的概述。本节首先介绍傅里叶不相交权重的概念,随后详细探讨两种关键策略:核空间调制和频率带调制。这两种策略分别旨在充分利用 FDConv 在核空间域和频率域的频率适应性。

图 2. 所提出的频率动态卷积(FDConv)的示意图,该框架由傅里叶不相交权重(FDW)、核空间调制(KSM)和频率带调制(FBM)模块组成,其中 FC 表示全连接层。
2.1 新建ultralytics/nn/Conv/FDConv_initialversion.py
class FDConv(nn.Conv2d):def __init__(self,in_channels: int,out_channels: int,kernel_size=3,reduction=0.0625,kernel_num=16,use_fdconv_if_c_gt=16, # if channel greater or equal to 16, e.g., 64, 128, 256, 512use_fdconv_if_k_in=[1, 3], # if kernel_size in the listuse_fbm_if_k_in=[3], # if kernel_size in the listkernel_temp=1.0,temp=None,att_multi=2.0,param_ratio=1,param_reduction=1.0,ksm_only_kernel_att=False,att_grid=1,use_ksm_local=True,ksm_local_act='sigmoid',ksm_global_act='sigmoid',spatial_freq_decompose=False,convert_param=True,linear_mode=False,fbm_cfg={'k_list': [2, 4, 8],'lowfreq_att': False,'fs_feat': 'feat','act': 'sigmoid','spatial': 'conv','spatial_group': 1,'spatial_kernel': 3,'init': 'zero','global_selection': False,},**kwargs,):p = autopad(kernel_size, None)super().__init__(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, padding=p,**kwargs)self.use_fdconv_if_c_gt = use_fdconv_if_c_gtself.use_fdconv_if_k_in = use_fdconv_if_k_inself.kernel_num = kernel_numself.param_ratio = param_ratioself.param_reduction = param_reductionself.use_ksm_local = use_ksm_localself.att_multi = att_multiself.spatial_freq_decompose = spatial_freq_decomposeself.use_fbm_if_k_in = use_fbm_if_k_inself.ksm_local_act = ksm_local_actself.ksm_global_act = ksm_global_actassert self.ksm_local_act in ['sigmoid', 'tanh']assert self.ksm_global_act in ['softmax', 'sigmoid', 'tanh']### Kernel num & Kernel temp settingif self.kernel_num is None:self.kernel_num = self.out_channels // 2kernel_temp = math.sqrt(self.kernel_num * self.param_ratio)if temp is None:temp = kernel_temp# print('*** kernel_num:', self.kernel_num)self.alpha = min(self.out_channels,self.in_channels) // 2 * self.kernel_num * self.param_ratio / param_reductionif min(self.in_channels, self.out_channels) <= self.use_fdconv_if_c_gt or self.kernel_size[0] not in self.use_fdconv_if_k_in:returnself.KSM_Global = KernelSpatialModulation_Global(self.in_channels, self.out_channels, self.kernel_size[0],groups=self.groups,temp=temp,kernel_temp=kernel_temp,reduction=reduction,kernel_num=self.kernel_num * self.param_ratio,kernel_att_init=None, att_multi=att_multi,ksm_only_kernel_att=ksm_only_kernel_att,act_type=self.ksm_global_act,att_grid=att_grid, stride=self.stride,spatial_freq_decompose=spatial_freq_decompose)if self.kernel_size[0] in use_fbm_if_k_in:self.FBM = FrequencyBandModulation(self.in_channels, **fbm_cfg)# self.FBM = OctaveFrequencyAttention(2 * self.in_channels // 16, **fbm_cfg)# self.channel_comp = ChannelPool(reduction=16)if self.use_ksm_local:self.KSM_Local = KernelSpatialModulation_Local(channel=self.in_channels, kernel_num=1, out_n=int(self.out_channels * self.kernel_size[0] * self.kernel_size[1]))self.linear_mode = linear_modeself.convert2dftweight(convert_param)def convert2dftweight(self, convert_param):d1, d2, k1, k2 = self.out_channels, self.in_channels, self.kernel_size[0], self.kernel_size[1]freq_indices, _ = get_fft2freq(d1 * k1, d2 * k2, use_rfft=True) # 2, d1 * k1 * (d2 * k2 // 2 + 1)# freq_indices = freq_indices.reshape(2, self.kernel_num, -1)weight = self.weight.permute(0, 2, 1, 3).reshape(d1 * k1, d2 * k2)weight_rfft = torch.fft.rfft2(weight, dim=(0, 1)) # d1 * k1, d2 * k2 // 2 + 1if self.param_reduction < 1:freq_indices = freq_indices[:, torch.randperm(freq_indices.size(1), generator=torch.Generator().manual_seed(freq_indices.size(1)))] # 2, indicesfreq_indices = freq_indices[:, :int(freq_indices.size(1) * self.param_reduction)] # 2, indicesweight_rfft = torch.stack([weight_rfft.real, weight_rfft.imag], dim=-1)weight_rfft = weight_rfft[freq_indices[0, :], freq_indices[1, :]]weight_rfft = weight_rfft.reshape(-1, 2)[None,].repeat(self.param_ratio, 1, 1) / (min(self.out_channels, self.in_channels) // 2)else:weight_rfft = torch.stack([weight_rfft.real, weight_rfft.imag], dim=-1)[None,].repeat(self.param_ratio, 1,1, 1) / (min(self.out_channels, self.in_channels) // 2) # param_ratio, d1, d2, k*k, 2if convert_param:self.dft_weight = nn.Parameter(weight_rfft, requires_grad=True)del self.weightelse:if self.linear_mode:self.weight = torch.nn.Parameter(self.weight.squeeze(), requires_grad=True)self.indices = []for i in range(self.param_ratio):self.indices.append(freq_indices.reshape(2, self.kernel_num,-1)) # paramratio, 2, kernel_num, d1 * k1 * (d2 * k2 // 2 + 1) // kernel_numdef get_FDW(self, ):d1, d2, k1, k2 = self.out_channels, self.in_channels, self.kernel_size[0], self.kernel_size[1]weight = self.weight.reshape(d1, d2, k1, k2).permute(0, 2, 1, 3).reshape(d1 * k1, d2 * k2)weight_rfft = torch.fft.rfft2(weight, dim=(0, 1)) # d1 * k1, d2 * k2 // 2 + 1weight_rfft = torch.stack([weight_rfft.real, weight_rfft.imag], dim=-1)[None,].repeat(self.param_ratio, 1, 1,1) / (min(self.out_channels, self.in_channels) // 2) # param_ratio, d1, d2, k*k, 2return weight_rfftdef forward(self, x):x_dtype = x.dtypeif min(self.in_channels, self.out_channels) <= self.use_fdconv_if_c_gt or self.kernel_size[0] not in self.use_fdconv_if_k_in:return super().forward(x)global_x = F.adaptive_avg_pool2d(x, 1)channel_attention, filter_attention, spatial_attention, kernel_attention = self.KSM_Global(global_x)if self.use_ksm_local:# global_x_std = torch.std(x, dim=(-1, -2), keepdim=True)hr_att_logit = self.KSM_Local(global_x) # b, kn, cin, cout * ratio, k1*k2,hr_att_logit = hr_att_logit.reshape(x.size(0), 1, self.in_channels, self.out_channels, self.kernel_size[0],self.kernel_size[1])# hr_att_logit = hr_att_logit + self.hr_cin_bias[None, None, :, None, None, None] + self.hr_cout_bias[None, None, None, :, None, None] + self.hr_spatial_bias[None, None, None, None, :, :]hr_att_logit = hr_att_logit.permute(0, 1, 3, 2, 4, 5)if self.ksm_local_act == 'sigmoid':hr_att = hr_att_logit.sigmoid() * self.att_multielif self.ksm_local_act == 'tanh':hr_att = 1 + hr_att_logit.tanh()else:raise NotImplementedErrorelse:hr_att = 1b = x.size(0)batch_size, in_planes, height, width = x.size()DFT_map = torch.zeros((b, self.out_channels * self.kernel_size[0], self.in_channels * self.kernel_size[1] // 2 + 1, 2),device=x.device)kernel_attention = kernel_attention.reshape(b, self.param_ratio, self.kernel_num, -1)if hasattr(self, 'dft_weight'):dft_weight = self.dft_weightelse:dft_weight = self.get_FDW()for i in range(self.param_ratio):indices = self.indices[i]if self.param_reduction < 1:w = dft_weight[i].reshape(self.kernel_num, -1, 2)[None]DFT_map[:, indices[0, :, :], indices[1, :, :]] += torch.stack([w[..., 0] * kernel_attention[:, i], w[..., 1] * kernel_attention[:, i]], dim=-1)else:w = dft_weight[i][indices[0, :, :], indices[1, :, :]][None] * self.alpha # 1, kernel_num, -1, 2# print(w.shape)DFT_map[:, indices[0, :, :], indices[1, :, :]] += torch.stack([w[..., 0] * kernel_attention[:, i], w[..., 1] * kernel_attention[:, i]], dim=-1)adaptive_weights = torch.fft.irfft2(torch.view_as_complex(DFT_map), dim=(1, 2)).reshape(batch_size, 1,self.out_channels,self.kernel_size[0],self.in_channels,self.kernel_size[1])adaptive_weights = adaptive_weights.permute(0, 1, 2, 4, 3, 5)# print(spatial_attention, channel_attention, filter_attention)if hasattr(self, 'FBM'):x = self.FBM(x)# x = self.FBM(x, self.channel_comp(x))if self.out_channels * self.in_channels * self.kernel_size[0] * self.kernel_size[1] < (in_planes + self.out_channels) * height * width:# print(channel_attention.shape, filter_attention.shape, hr_att.shape)aggregate_weight = spatial_attention * channel_attention * filter_attention * adaptive_weights * hr_att# aggregate_weight = spatial_attention * channel_attention * adaptive_weights * hr_attaggregate_weight = torch.sum(aggregate_weight, dim=1)# print(aggregate_weight.abs().max())aggregate_weight = aggregate_weight.view([-1, self.in_channels // self.groups, self.kernel_size[0], self.kernel_size[1]])x = x.reshape(1, -1, height, width)output = F.conv2d(x.to(aggregate_weight.dtype), weight=aggregate_weight, bias=None, stride=self.stride,padding=self.padding,dilation=self.dilation, groups=self.groups * batch_size).to(x_dtype)if isinstance(filter_attention, float):output = output.view(batch_size, self.out_channels, output.size(-2), output.size(-1))else:output = output.view(batch_size, self.out_channels, output.size(-2),output.size(-1)) # * filter_attention.reshape(b, -1, 1, 1)else:aggregate_weight = spatial_attention * adaptive_weights * hr_attaggregate_weight = torch.sum(aggregate_weight, dim=1)if not isinstance(channel_attention, float):x = x * channel_attention.view(b, -1, 1, 1)aggregate_weight = aggregate_weight.view([-1, self.in_channels // self.groups, self.kernel_size[0], self.kernel_size[1]])x = x.reshape(1, -1, height, width)output = F.conv2d(x.to(aggregate_weight.dtype), weight=aggregate_weight, bias=None, stride=self.stride,padding=self.padding,dilation=self.dilation, groups=self.groups * batch_size).to(x_dtype)# if isinstance(filter_attention, torch.FloatTensor):if isinstance(filter_attention, float):output = output.view(batch_size, self.out_channels, output.size(-2), output.size(-1))else:output = output.view(batch_size, self.out_channels, output.size(-2),output.size(-1)) * filter_attention.view(b, -1, 1, 1)if self.bias is not None:output = output + self.bias.view(1, -1, 1, 1)return output.to(x_dtype)def profile_module(self, input: Tensor, *args, **kwargs):# TODO: to edit itb_sz, c, h, w = input.shapeseq_len = h * w# FFT iFFTp_ff, m_ff = 0, 5 * b_sz * seq_len * int(math.log(seq_len)) * c# others# params = macs = sum([p.numel() for p in self.parameters()])params = macs = self.hidden_size * self.hidden_size_factor * self.hidden_size * 2 * 2 // self.num_blocks# // 2 min n become half after fftmacs = macs * b_sz * seq_len# return input, params, macsreturn input, params, macs + m_ff
2.2 yolov8-pose-C2f_FDConv.yaml
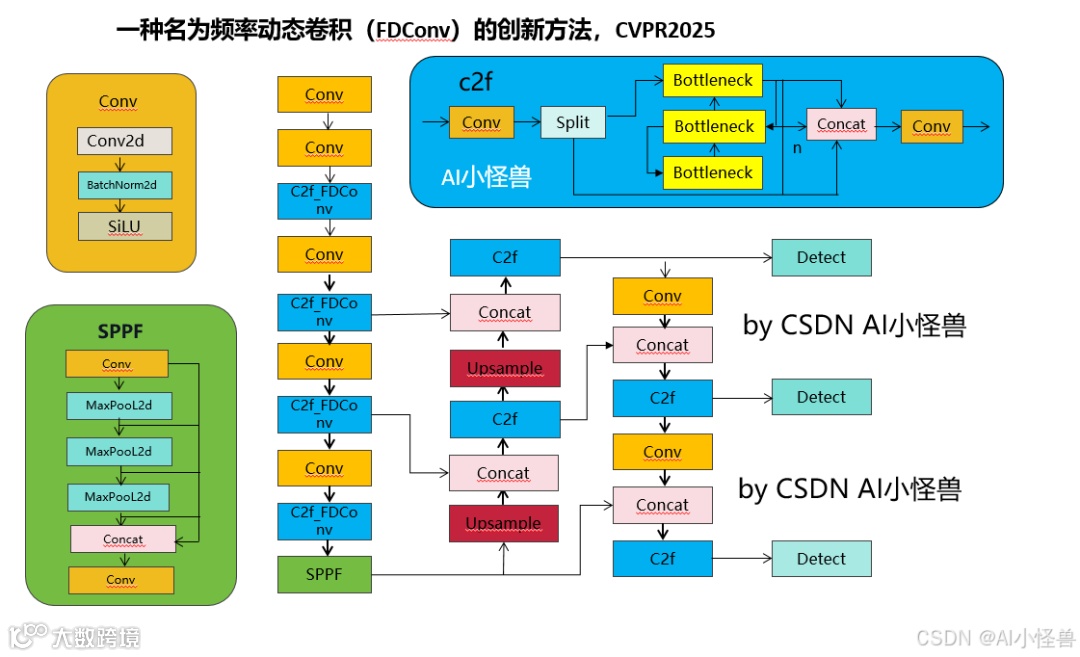
# Ultralytics YOLO 🚀, AGPL-3.0 license# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parametersnc: 1 # number of classeskpt_shape: [17, 3] # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)scales: # model compound scaling constants, i.e. 'model=yolov8n-pose.yaml' will call yolov8-pose.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024]s: [0.33, 0.50, 1024]m: [0.67, 0.75, 768]l: [1.00, 1.00, 512]x: [1.00, 1.25, 512]# YOLOv8.0n backbonebackbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f_FDConv, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f_FDConv, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f_FDConv, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f_FDConv, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n headhead:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Pose, [nc, kpt_shape]] # Detect(P3, P4, P5)