

-
论文标题: Glance: Accelerating Diffusion Models with 1 Sample -
作者: Zhuobai Dong, Rui Zhao, Songjie Wu, Junchao Yi, Linjie Li, Zhengyuan Yang, Lijuan Wang, Alex Jinpeng Wang -
机构: 武汉大学、新加坡国立大学、中南大学、电子科技大学、微软 -
论文地址: https://arxiv.org/abs/2512.02899 -
代码仓库: https://github.com/CSU-JPG/Glance
这是一篇相当有意思的论文,关于扩散模型加速。我们都知道,扩散模型虽然效果惊艳,但“慢”这个字一直是它绕不开的痛。为了让它跑得更快,学术界和工业界想尽了办法,比如模型蒸馏(Distillation),但通常需要海量数据和巨大的算力成本,让人望而却步。
而这篇名为《Glance》的论文,就像它的名字一样,仅需“惊鸿一瞥”的数据,就完成了对大模型的加速,一种极为高效的方案。它的核心亮点可以用几个数字来概括:仅需1个训练样本,在单张V100上训练不到1小时,就能让庞大的扩散模型在推理时实现高达5倍的加速——例如,将原本需要50步的推理过程大幅压缩到10步甚至8步,同时画质基本不掉队。这听起来是不是有点不可思议?

上图直观地展示了Glance在数据和算力消耗上的惊人效率。与动辄需要数百万样本和数千GPU小时的传统蒸馏方法相比,Glance的成本几乎可以忽略不计,堪称“四两拨千斤”的典范。
核心思想:智能加速,而非均匀“跳步”
以往的加速方法,大多是均匀地“跳过”一些去噪步骤,就像快进播放视频,但每个阶段都用同样的倍速。这种方式虽然快,但容易丢失关键信息,导致画质下降。
Glance的作者们换了一个思路:去噪过程的每个阶段并非同等重要。他们发现,可以被“跳过”或“大步跨越”的,主要是后半段负责精调细节的步骤。而前半段构建轮廓和核心语义的步骤则需要相对谨慎。
基于这个洞察,他们提出了一种“相位感知(Phase-aware)”的加速策略,称之为“慢-快(Slow-Fast)”策略。论文的图3(Figure 3)给出了一个非常直观的例子:

如上图所示,我们可以将一个50步的去噪过程划分为两个不同速度的阶段:
-
慢速阶段 (Slow Stage): 对应去噪早期、高噪声的步骤(例如前20个时间步)。在这个阶段,模型主要在构建画面的整体结构和语义,至关重要。因此,这里的加速是相对保守的,比如采用“小步快跑”的策略,每隔一步采样一次,保证核心信息不丢失。 -
快速阶段 (Fast Stage): 对应去噪后期、低噪声的步骤(例如后30个时间步)。此时画面轮廓已定,模型主要在雕琢纹理和细节,存在大量冗余。因此,这里可以采用“大步流星”的策略,进行大幅度的跨越。例如,在剩下的30个步骤中,可能只均匀地挑出5个步骤来执行。
通过这种智能的“变速”处理,Glance在保证了核心生成质量的同时,实现了最大化的加速。
实现方式:轻量级的LoRA“双专家”
那么,如何让一个固定的模型在不同阶段采用不同的“速度”呢?重新训练一个庞大的学生模型显然不符合“高效”的初衷。
作者们想到了一个绝妙的办法:利用轻量级的LoRA(Low-Rank Adaptation)技术。这里简单解释一下,LoRA是一种非常高效的模型微调方法。它的核心思想是“冻住”几十上百亿参数的庞大基座模型不动,只在模型的关键部分旁边挂上一些参数量极小的“补丁模块”(也就是适配器)。训练时,只更新这些“补丁”的参数。因为“补丁”很小,所以训练起来又快又省资源。
Glance正是利用了这一点。他们没有动原始的基座模型,而是为其配备了两个小巧的、可插拔的LoRA适配器,分别扮演不同角色的专家:
-
Slow-LoRA: 专门负责“慢速”的语义构建阶段。 -
Fast-LoRA: 专门负责“快速”的细节精雕阶段。
在推理时,模型会先加载Slow-LoRA处理前期的去噪步骤,然后在某个时间点(论文中基于信噪比SNR来划分)切换到Fast-LoRA,完成后续的冲刺。整个过程就像一场接力赛,两位专家各司其职,无缝衔接。

这种方式的好处是巨大的。由于LoRA的参数量极小,训练它所需要的数据和算力自然就非常少。这也就解释了为什么仅用1个样本和1小时的训练,就能达到如此惊艳的效果。它完美地绕过了传统蒸馏方法“费时费力”的缺点,提供了一种即插即用、成本极低的加速方案。
实验效果:又快又好,泛化性强
Glance的性能究竟如何?作者在多个主流的文生图大模型(如FLUX.1和Qwen-Image)和多个权威的Benchmark上进行了全面的评测。
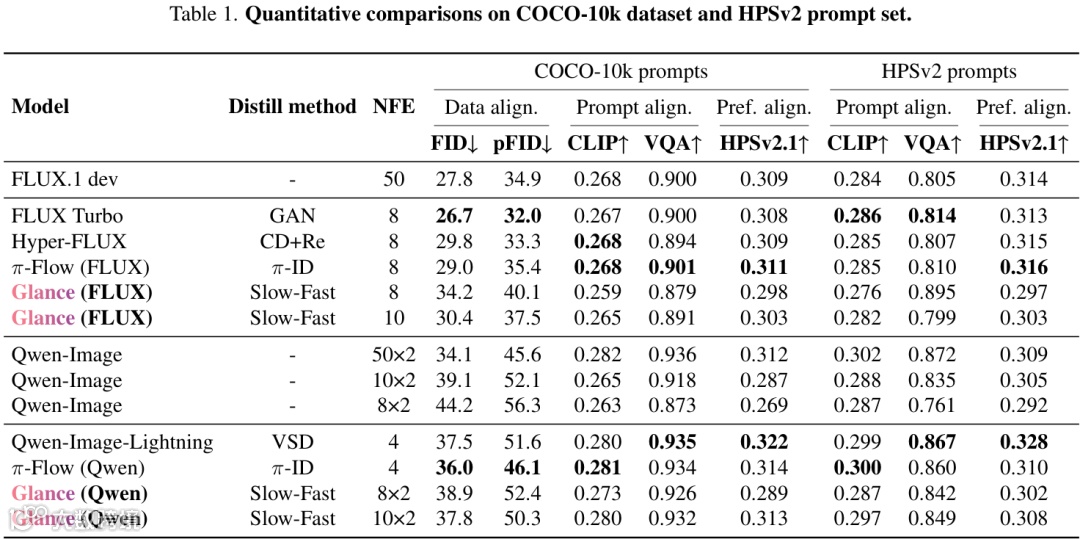

从上面两张表中的数据可以看出,Glance在大幅减少推理步数(NFE)的情况下,各项生成质量指标(如FID、CLIP Score等)与需要几十步推理的原始模型相比,虽有差距但依然保持了很强的竞争力,并且优于一些同样是少步数的模型。

上图的视觉对比更加直观。可以看到,Glance在8步或10步的设置下,生成的图像在语义保真度上非常接近50步的原始模型,只是在一些精细纹理上略有损失。这证明了“慢-快”策略的有效性:保住了核心,牺牲了部分细节,换来了巨大的速度提升。
为什么一个样本就足够了?
看到这里,相信大家最大的疑问是:只用一张图训练,模型难道不会“过拟合”到这张图上,只会画它吗?选择什么样的样本会影响最终效果呢?
这正是这篇论文最反直觉也最有趣的地方,作者们也专门针对“单一训练样本的泛化能力”做了详细的实验。他们尝试了用几种不同内容和来源的单一图片去分别训练模型:
-
“狐狸”图像:一张模型自身生成的(即“分布内”的)卡通狐狸图片。 -
“山谷风景”图像:一张同样是“分布内”的自然风光图片。 -
“书店”图像:一张同样是“分布内”的、富含密集文字信息的图片。 -
“真实世界”图像(分布外OOD):一张完全“分布外”的真实街景照片。 -
“高斯噪声”图像:对照组。
实验结果非常有意思。他们发现:
-
关于数量:将训练样本从1个增加到10个甚至100个,模型的最终性能并没有显著提升。

-
关于样本风格:不同样本(如狐狸、风景、书店、真实世界OOD图)训练出的模型,虽然在风格上略有差异,但定量性能指标却相对接近。这说明 Glance对单个样本的选择并不特别敏感。
-
最值得注意的是,即使是使用“分布外”的真实世界图片进行训练,模型也能达到与“分布内”图片相媲美的性能。这进一步证明了Glance的强大泛化能力。
-
唯一的失败案例是使用纯粹的“高斯噪声”训练时,模型完全无法生成有意义的图像。
这说明,Glance的训练过程并不是在学习样本的具体内容(比如“一只狐狸的样貌”),而是在学习一种普适的“如何快速且有效地去噪”的动态行为。可以这样理解:那唯一的一个样本就像一个“陪练”,它的作用是为模型提供一个符合自然图像统计规律的信号,让Slow-LoRA和Fast-LoRA这两个“专家”能在各自负责的“赛段”(高噪声和低噪声阶段)里,学会如何与基座模型配合,以最有效的方式完成接力跑。它们学到的是一套通用的加速“技巧”,而非某个特定图像的“知识”。因此,一旦学会,这套技巧就可以应用到任何内容的生成任务上,展现出强大的泛化能力,只要你选择的是一张有意义、有结构的“正常图片”,而非纯噪声即可。

即使只用一张“狐狸”的图片进行训练,模型也能很好地泛化到各种完全没见过的场景提示词,比如生成建筑、风景和人物。这说明Glance学到的是普适的“加速去噪”能力,而不是过拟合到某个特定的样本上。
当然,Glance也并非完美无缺。实验同样指出了它的一个短板:在处理非常细小或密集的文字渲染时,效果会打折扣,容易出现模糊或扭曲。

写在最后
总的来说,Glance的出现为扩散模型加速提供了一个全新的、极具吸引力的新视角。它告诉我们,通过对扩散过程的深刻理解,设计巧妙的“变速”策略,再结合轻量级的微调技术,同样能实现卓越的加速效果。