
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
AI/CV重磅干货,第一时间送达
添加微信号:CVer2233,小助手拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料及应用!发论文/搞科研/涨薪,强烈推荐!
添加微信号:CVer2233,小助手拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料及应用!发论文/搞科研/涨薪,强烈推荐!

转载自:HKUST Smart lab
Large-Scale 3D Medical Image Pre-training with Geometric Context Priors
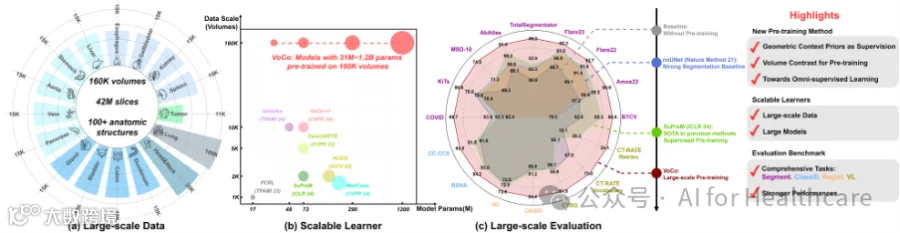
近日,HKUST Smart lab关于3D医学图像预训练的工作被人工智能顶刊IEEE TPAMI(IF=18.6)接收,通讯作者为香港科技大学计算机系陈浩教授。这项工作是我们在CVPR 2024的扩展版本。我们推出了医学3D视觉大模型VoCo。(1) 我们建立了本领域最大规模的预训练数据集PreCT-160K,包括来自人体不同解剖区域的16万3D CT。(2) 我们提出了一种新颖的自监督训练方法:通过对比学习来进行上下文位置预测,有效利用无标注数据学习图像表征。(3) 我们探究不同的预训练方针,从全监督,自监督,半监督到混合监督预训练。(4) 我们开源实现了50多个下游医学任务以供公平计较,包括分割,分类,配准和视觉语言处理。

1
简介
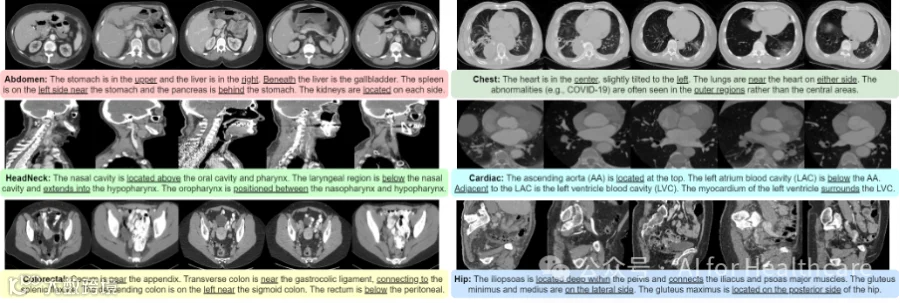
图1. 在医学图像中,不同器官之间的几何关系相对一致。我们从PreCT-160K中提供一些示例,以说明这些解剖关系在不同区域之间的关联。受到这一观察的启发,我们提出利用几何背景先验来学习一致的语义表示,并引入一项新颖的位置预测预训练任务。
2.1
相关工作:
大规模视觉预训练
视觉预训练的主要挑战在于设计有效的预训练方法。尽管监督预训练(supervised pre-training)是一种直接的方法,但注释成本高昂和对大规模未标记数据的忽视仍然阻碍了supervised pre-training的进一步发展。因此,自监督学习(SSL)提出了在没有注释指导的情况下学习稳健特征的方法,最近受到了广泛关注。DINO提出整合先进的SSL方法,学习稳健特征而无需注释,已成为当代研究中预训练主干的普遍选择。
尽管上述方法在自然图像中取得了有前途的结果,但直接将这些预训练模型应用于医学图像会面临由于领域差距而带来的挑战。DINO预训练了一系列强大的2D视觉Transformer,并在2D医学图像(如X射线和病理图像)中展示了显著的可迁移。然而,在需要提取体积信息的具有挑战性的3D医学任务领域中,强大的预训练3D模型仍未得到充分探索。
大多数最先进的SSL方法在3D医学图像中往往难以取得竞争性表现,主要是由于忽视了3D医学图像的独特特征。具体来说:(1) 在自然图像中的对比学习提出在不同图像间建立正负样本对,即,将输入的增强视图分配为正样本,其他图像分配为负样本。然而,对于共享相似解剖结构的3D医学图像,通过这种方式建立负样本对是困难的。(2) MIM提出遮蔽并重建缺失像素。然而,对于具有高维度、大尺寸和显著背景比例的3D医学图像,这些方法通常会遇到问题,因为模型往往会收敛于重建无关背景区域,从而减弱了对语义区域(如器官)的理解。因此,为3D医学图像开发先进的SSL技术需要仔细考虑独特的图像信息,并制定量身定制的策略。
2.2
大规模医学视觉预训练
医学视觉预训练已被证明是缓解医学任务中注释稀缺性的有效方式。早期尝试在2D X射线图像上进行了预训练,展示了在胸部病理识别和气胸分割方面的改进。相比之下,3D医学图像,例如CT和磁共振成像(MRI),为临床诊断提供了更丰富的体积信息,因此在医学图像分析中受到越来越多的关注。然而,3D医学图像固有的复杂性给预训练带来了重大挑战,特别是在数据规模、模型容量和预训练方法方面。
2.2.1 大规模数据
与2D X射线相比,收集CT等3D医学图像更加困难,原因包括成像速度较慢、辐射暴露增加以及成本上升。大多数现有方法利用了有限规模的3D数据进行预训练。为了收集用于预训练的大规模3D数据,需要从多个来源汇总数据集,这将导致数据集中具有不同的图像特征和不一致的成像质量,为预训练引入新的挑战。
此外,先前的方法主要从特定身体部位收集数据进行预训练。然而,由于各解剖区域具有不同特征,因此在一个区域上进行预训练的模型向其他区域的迁移可能受到限制。本文构建了一个包含多种解剖结构的大规模数据集PreCT-160K。然而,来自不同解剖区域的数据展现出不同的成像参数,例如不同的尺寸、间距和强度,为在预训练中学习一致表示带来了新的挑战。
2.2.2 大模型
早期的3D医学图像预训练工作在模型容量上存在限制,通常只包含数千万参数。最近的进展展示了缩放规律的惊人有效性,即在大规模数据上训练的大模型表现出卓越的智能。本文收集了一个大规模3D医学图像数据集,其中包含来自各种来源的多样化图像特征。这样广泛的数据的可用性为我们训练大型模型开辟了新的机会。
考虑到各种医学任务的多样性,评估大型模型在全面基准上至关重要。先前的方法主要在少数几个下游任务上评估预训练模型,通常聚焦于分割或分类任务。本文深入探讨了不同医学任务中的缩放规律,提供了针对不同医学任务有效调整不同模型尺寸的指导方针。
2.2.3 先进的预训练技术
3D医学图像的自监督学习。现有方法主要基于信息重构来学习3D医学图像的增广不变表示,首先对图像进行强数据增广,然后重建原始信息。尽管已经展示了有希望的结果,但这些方法中大多数忽视了将高级语义集成到模型表示中的重要性,从而阻碍了在下游任务中的进一步改进。
预训练中的高级语义。对于医学图像,高级语义信息主要源自手动注释,因为它严重依赖于专家知识。先前的工作提出,监督预训练更有效,可以在较少的训练时间和标记数据下实现更高的性能。然而,标记数据稀缺性带来的挑战仍然存在,阻碍了对不同医学任务、不同解剖结构和广泛未知数据集的可迁移性。
混合监督学习(omni-supervised learning)。尽管自我监督学习使我们能够在预训练中涉及大规模未标记数据,但它仍然忽视了现成的标记数据的利用。半监督学习在利用标记和未标记数据方面展示了强大的功效。在本文中,我们进一步提出了一个简单但有效的混合监督预训练框架,将自我监督学习和半监督学习结合起来,释放标记和未标记医学图像的力量。
3
具体方法,公式请参阅论文:
https://ieeexplore.ieee.org/document/11274411
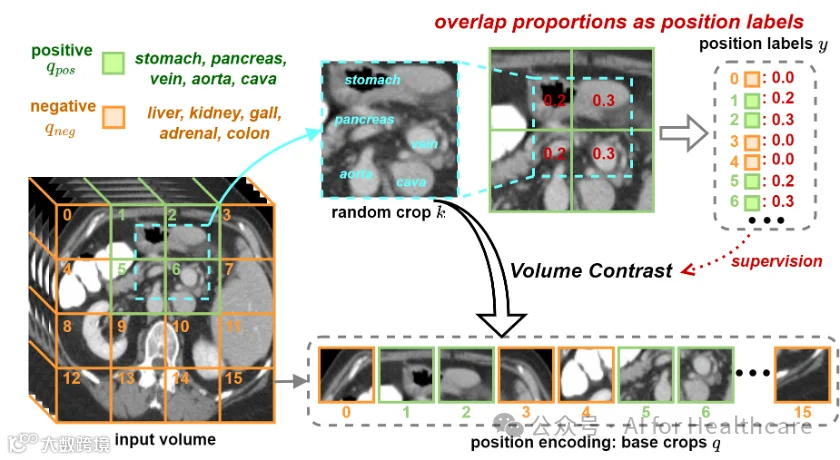
图2. Generate position labels for supervision(为监督生成位置标签)。如果一对随机裁剪k和基准裁剪q共享重叠区域,则将它们分配为positive,否则为negative。我们将重叠比例计算为位置标签y,例如,y1,y2,y5,y6分别被分配为0.2,0.3,0.2,0.3。
关键的流程是为SSL生成位置标签(position labels)。我们提议利用3D医学图像中固有的几何上下文先验。如图所示,给定输入V,我们首先随机裁剪一个子体积k ,旨在构建与用于对比学习的正负对。具体地,我们使用位置编码来生成n个不重叠的基准裁剪。例如,如图所示生成了n=4*4个基准裁剪,其中每个基准裁剪q代表输入体积的一个不同区域。在人体解剖学中,各种器官位于不同区域,为我们提供了形成正负对的潜在方法。如图所示,随机裁剪k和正基准裁q-pos剪展示出重叠区域,而缺乏这种重叠的负基准裁剪q-neg更有可能包含不同的器官。例如,在图中,k和q-pos均包含胃、胰腺、静脉、主动脉和下腔静脉,而q-neg展示出不同的器官信息。
因此,我们可以利用位置编码构建正负对进行对比学习。先前的对比学习方法主要采用InfoNCE loss来最大化正对之间的互信息(mutual information)。在本文中,我们提议生成具体数值的标签y,用于监督正对之间的相关程度,即,使用标签y反映k与q-pos之间的相似度。可以观察到,k和q-pos之间的相关性与它们的重叠比例有关。显然,如果正基准裁q-pos与k 分享更多重叠区域,那么这个q-pos将更类似于k。因此,如图所示,我们提议将重叠比例分配为位置标签的值,使我们能够衡量k与q-pos之间的相似度。相比之下,q-neg的位置标签y分配为0。通过这种方式,我们利用之重叠比例来监督上下文位置预测结果。
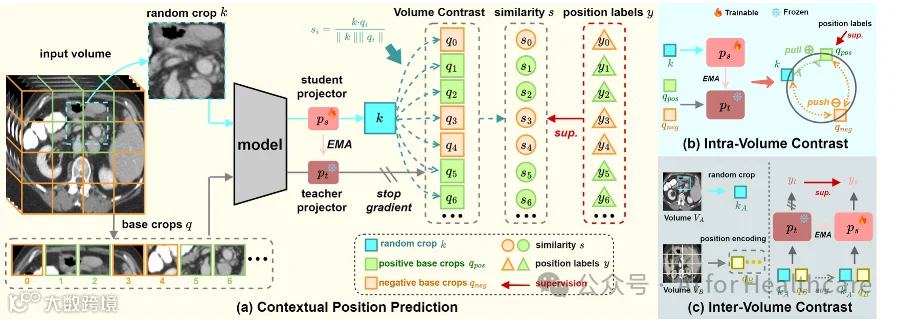
图3. 整体框架。(a) 首先,我们生成具有相应位置标签y的基准裁剪q。然后,我们将随机裁剪k和基准裁剪q输入进行上下文位置预测。具体来说,我们使用一个student-teacher模块分别投影k和q。最后,我们在k和q之间进行体积对比(volume contrast),预测相似度s,其中s由位置标签y进行监督。 (b) 我们使用位置标签y来监督k、q-pos和q-neg之间的体内对比,其中k、q-pos和q-neg来自同一体积。 (c) 我们从不同体积V-A和V-B中提取随机裁剪k和基准裁剪q进行体间对比。(具体公式请见论文)。

图4. 混合监督预训练。如图所示,全监督学习和自监督学习各有优点和缺点。(a) 全监督学习可以在标签的指导下学习有区分性的决策边界,但受限于标记数据的匮乏。(b) 自监督学习可以利用大规模未标记数据。然而,缺乏用于监督的注释,它在学习不同类别之间清晰的决策边界时存在困难。为此,我们提出全方位监督预训练方法,融合全监督学习和自监督学习的优势,有效释放了标记和未标记数据的潜力。
半监督学习是一种可扩展的学习器。为了有效利用标记和未标记数据,我们提出进行半监督学习从标记数据向大规模未标记数据借鉴知识。值得注意的是,在监督训练中,分割技术最为常见,因为许多医学任务需要对像素级别进行细致理解以进行准确诊断。先前的工作仅利用了几百个案例进行半监督分割。然而,复杂的半监督分割设计将显著增加训练负担,这对我们的大规模数据是不可行的。在本文中,我们采用简单的半监督学习基线并将数据扩展到160K个体积。我们发现,与VoCo相结合,最简单的半监督基线已经可以取得竞争性的结果。

4
实验结果
我们构建了迄今最大的医学视觉预训练数据集PreCT-160K和VoComni。我们开源实现了50多个下游任务的实现,包括分割,分类,配准和视觉语言。经过超过10000 GPU hours 的验证,我们建立了这个领域最大规模的benchmark以供公平比较。实验结果证明了我们提出方法的有效性,具体请参阅https://github.com/Luffy03/Large-Scale-Medical.
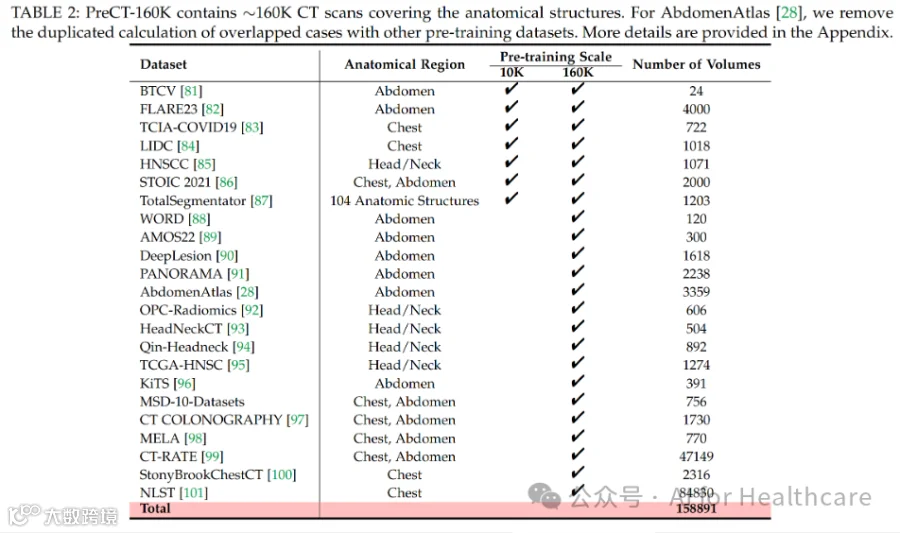
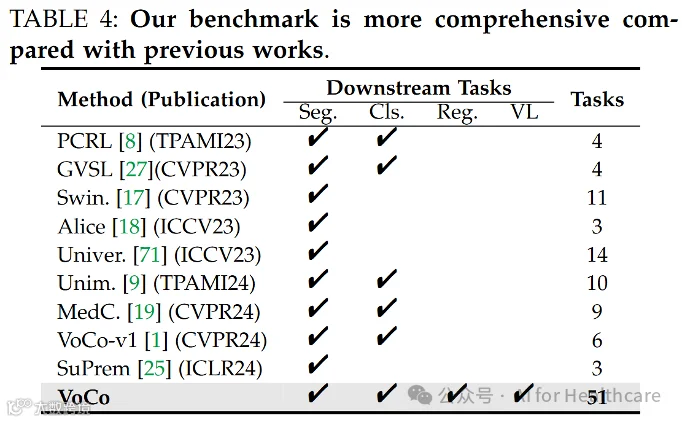
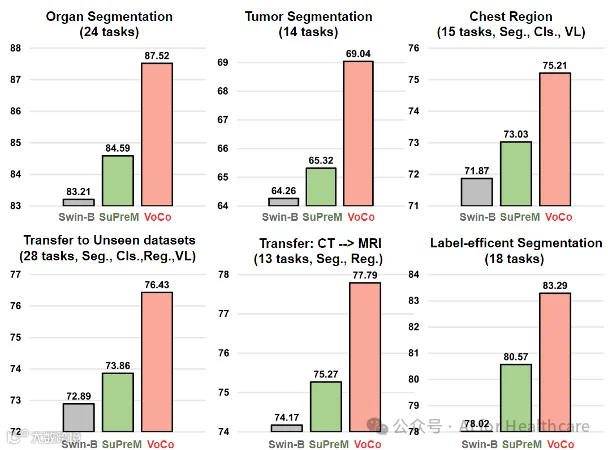
图5. 我们的预训练大模型在多个任务上大幅超越已有工作。
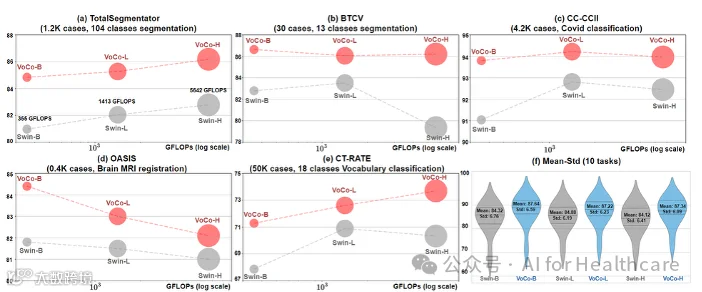
图6. 在医学任务中,更大的模型是否总是更好呢?从图可以看出,对于一些特定任务,规模较小的模型可以取得更好的性能。本文深入探讨了影响模型容量扩展规律的因素,包括:微调案例数量、数据多样性和任务难度。
如图所示,(a) TotalSegmentator是一个具有挑战性的数据集,包含1.2K个案例和104个分割类别。在这种情况下,最大的模型VoCo-H获得了最佳结果。 (b) BTCV只有24个案例进行微调,可能导致更大的模型在有限数据上过拟合,从而影响验证性能。 (c)尽管CC-CCII包含了4.2K个案例用于训练,但这是一个简单的二元分类任务(超过90%的准确率),表明过度庞大的模型可能并非必要。 (d) OASIS是一个只有0.4K个案例用于配准的脑MRI数据集,也缺乏显著的结构多样性。在这种情况下,最小VoCo-B提供了最佳结果。(e) CT-Rate具有50K个案例用于18个类别的词汇分类。在进行大规模数据训练时,更大的模型展现出更高的性能。
为不同的医学任务量身定制不同的模型大小。我们基于经验提出了简单而合理的指导方针,以适应各种医学任务:(1)对于具有大量标记数据进行微调的任务,更大的模型可能会带来好处。 (2) 涵盖多样解剖区域的任务可能会受益于更大的模型。(3) 需要跨更多类别(更具挑战性)进行识别的任务更适合使用更大的模型。尽管这些指导原则已在我们的综合基准测试中进行了评估,但鉴于医学领域内的巨大多样性,它们可能并不适用于所有医学任务。因此,我们发布了各种大小的预训练模型,以帮助研究人员选择最适合其特定需求的模型。
5
结论
6
论文与资源
论文 | Linshan Wu, Jiaxin Zhuang, and Hao Chen. "Large-Scale 3D Medical Image Pre-training with Geometric Context Priors". TPAMI 2025.
论文链接 | https://ieeexplore.ieee.org/document/11274411
开源代码,数据,预训练模型 | https://github.com/Luffy03/Large-Scale-Medical
本文系学术转载,如有侵权,请联系CVer小助手删文
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
ICCV 2025 论文和代码下载
在CVer公众号后台回复:ICCV2025,即可下载ICCV 2025论文和代码开源的论文合
CVPR 2025 论文和代码下载
在CVer公众号后台回复:CVPR2025,即可下载CVPR 2025论文和代码开源的论文合集
CV垂直方向和论文投稿交流群成立
扫描下方二维码,或者添加微信号:CVer2233,即可添加CVer小助手微信,便可申请加入CVer-垂直方向和论文投稿微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者论文投稿+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)人数破万!如果你想要了解最新最快最好的CV/DL/AI论文、实战项目、行业前沿、从入门到精通学习教程等资料,一定要扫描下方二维码,加入CVer知识星球!最强助力你的科研和工作!
▲扫码加入星球学习
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看
▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)人数破万!如果你想要了解最新最快最好的CV/DL/AI论文、实战项目、行业前沿、从入门到精通学习教程等资料,一定要扫描下方二维码,加入CVer知识星球!最强助力你的科研和工作!
▲扫码加入星球学习
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看