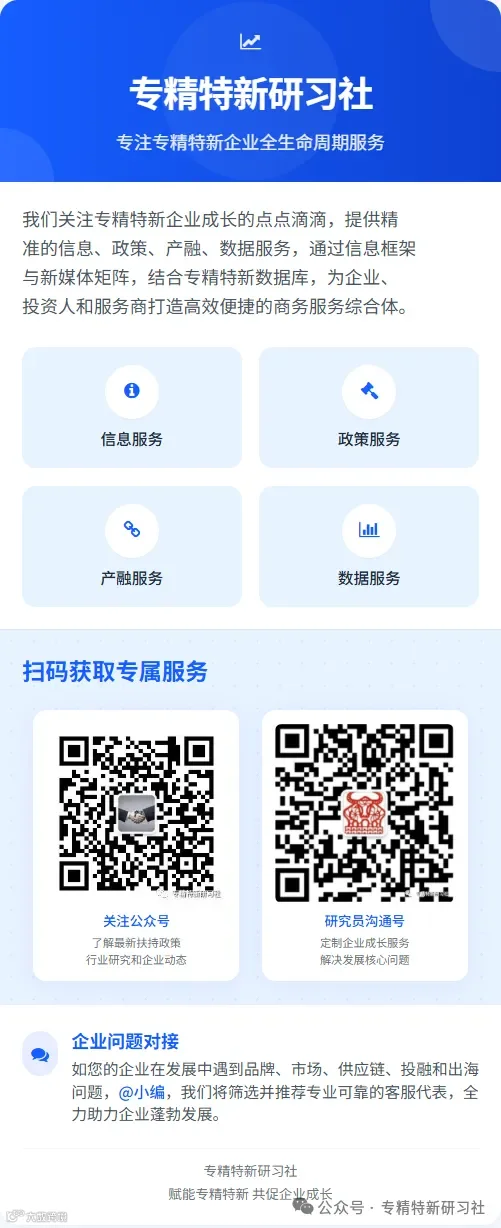
谷歌最新TPU7Ironwood芯片
 TPU工作原理示意图。为了执行矩阵运算,TPU 将 HBM 内存中的参数加载到矩阵乘法单元 MXU 中。
TPU工作原理示意图。为了执行矩阵运算,TPU 将 HBM 内存中的参数加载到矩阵乘法单元 MXU 中。

然后,TPU 从内存加载数据。每次执行乘法运算时,系统都会将结果传递给下一个乘法累加器。输出是数据和参数之间所有乘法结果的总和。在矩阵乘法过程中,不需要访问内存。因此,TPU 可以在神经网络计算中实现高计算吞吐量。
TPU的工作原理可以类比为一台高效的矩阵计算机器。每个深度学习神经网络模型的训练和推理过程都包含大量的矩阵运算,TPU的设计就是为此量身定做的。在训练过程中,TPU以高效的方式执行神经网络中的加法和乘法操作,确保能够在最短的时间内处理大量数据。 通过优化计算单元的布局、减少控制逻辑的复杂性,TPU能够在处理这些矩阵计算时获得更高的性能。例如,在处理一批大小固定的矩阵时,TPU能够在确定的时间内完成任务,从而保证高吞吐量和低延迟。以TPU v4 为例,单个 Tray 包含 4 个 TPU 芯片或 8 个 TensorCore。 每个 Tray 通过 PCIe 与 CPU host 连接,芯片与芯片之间则采用 Inter Chip Interconnect(ICI)技术连接,后者具有更高带宽。
谷歌TPU4实例和逻辑图
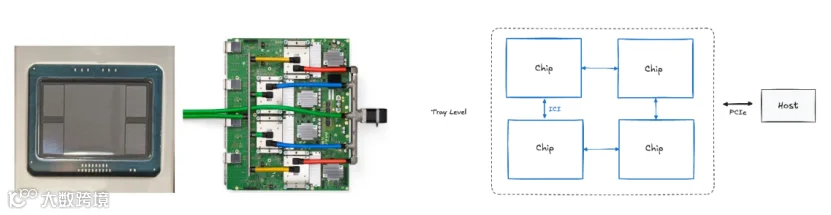
TPU 包含数千个乘法累加器,这些累加器彼此直接连接以形成大型物理矩阵。这称为脉动阵列架构。TPU 主机将数据流式传输到馈入队列中。TPU 从馈入队列加载数据,并将其存储在 HBM 内存中。计算完成后,TPU 会将结果加载到馈出队列中。然后,TPU 主机从馈出队列读取结果并将其存储在主机的内存中。
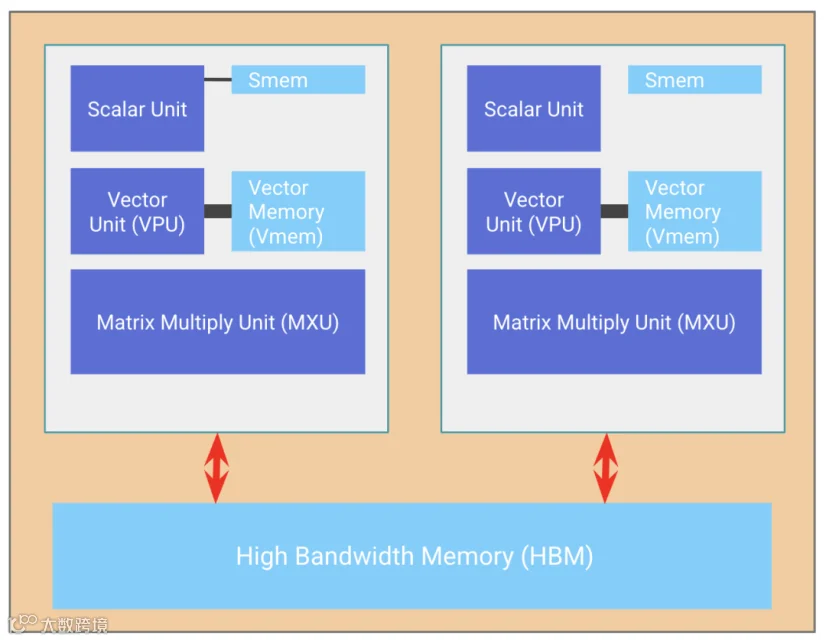
TPU 是一种以矩阵乘法为核心任务的计算单元 TensorCore,其架构中集成了高速堆叠内存 HBM,以支持大规模张量运算。
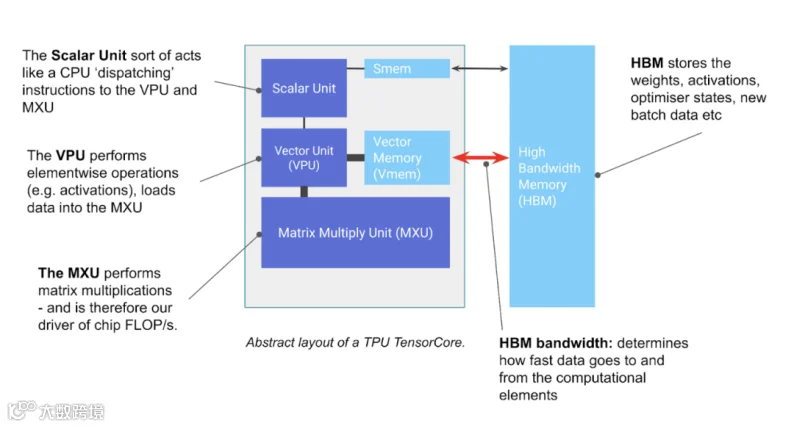
【图片】TPU 芯片的基本组成部分 - TensorCore 是左侧灰色的模块,内部包含矩阵乘法单元 MXU、向量处理单元 VPU 和向量内存 VMEM。
矩阵乘法单元 MXU是 TensorCore 的重要组件。在大多数 TPU 代际中,它每 8 个周期使用脉动阵列 systolic array 执行一次bfloat16[8,128] @ bf16[128,128],输出为f32[8,128]。在TPU v5e上,单个 MXU 在 1.5GHz 下的计算能力约为 5e13 次 bfloat16 FLOPs/s。
大多数 TensorCore 包含 2 或 4 个 MXU,因此例如 TPU v5e 的总 bfloat16 浮点运算能力约为 2e14 FLOPs/s。TPU 还支持更低精度的矩阵乘法运算,以获得更高的吞吐量。例如,每个 TPU v5e 芯片可执行约 4e14 次 int8 OPs/s。
向量处理单元 VPU负责执行一般的数学操作 - ReLU 激活函数、向量之间的逐点加法或乘法运算。向量归约操作也在此单元中完成。
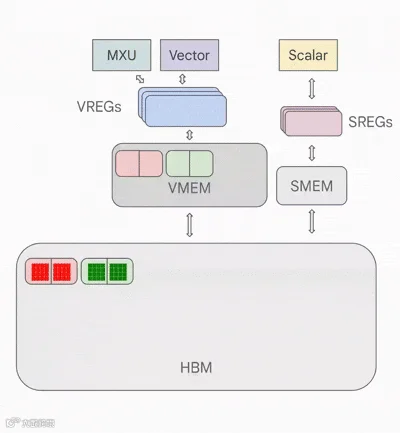
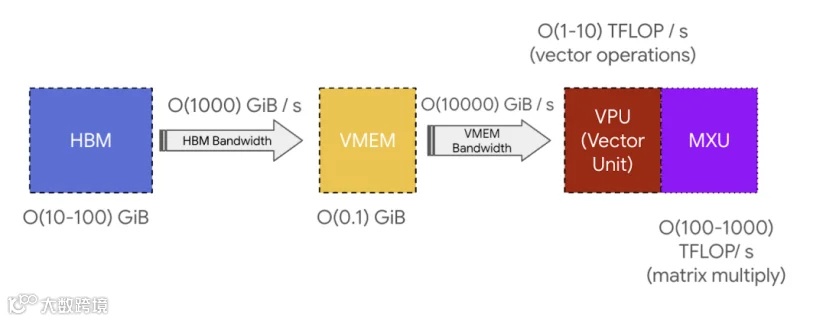
向量内存 VMEM是位于 TensorCore 内部的片上高速缓存区,靠近计算单元。它的容量远小于 HBM,但与 MXU 之间具有更高的带宽。VMEM 的运作方式类似于 CPU 中的 L1/L2 缓存,但容量更大且由程序员控制。在 TensorCore 执行任何计算之前,HBM 中的数据必须先被复制到 VMEM 中。 高带宽内存 HBM是一块高速大容量内存,用于存储供 TensorCore 使用的张量数据。HBM 的容量通常在几十 GiB 的量级 - TPU v5e 配备了 16GiB 的 HBM。在需要进行计算时,张量会从 HBM 通过 VMEM 流入 MXU,计算结果再从 VMEM 写回 HBM。
HBM 与 TensorCore 之间的带宽称为 HBM 带宽,通常约为 1–2TB/s。该带宽决定了在内存受限任务中计算的速度上限。
VMEM 与算术强度:VMEM 的容量远小于 HBM,但它与 MXU(矩阵乘单元)之间的带宽却高得多。正如第 1 节所述,如果一个算法的输入/输出数据能够完全放入 VMEM,就不太可能遇到通信瓶颈。
对于算术强度较低的计算任务,这一点尤其重要:VMEM 的带宽大约是 HBM 的 22 倍,这意味着 MXU 在从 VMEM 读取或写入数据时,只需要 10–20 的算术强度就能达到峰值 FLOPs 利用率。
这意味着如果我们能将权重放入 VMEM 而不是 HBM,矩阵乘法在更小的 batch size 下就能达到计算瓶颈(FLOPs bound)。同时也意味着那些本质上算术强度较低的算法仍然可以高效运行。唯一的挑战是 VMEM 的容量非常小。
一个 TPU 芯片通常包含两个 TPU 核心,这两个核心共享内存,可被视为一个具有双倍 FLOPs 的大型加速器,这种配置被称为超级核心 megacore。这种架构从 TPU v4 开始成为常态。更早的 TPU 芯片 - TPU v3 及更早版本,则采用独立内存,被视为两个独立的加速器。而针对推理优化的芯片 TPU v5e 则每个芯片仅包含一个 TPU 核心。
芯片通常以每组4个的形式排列在一个托盘上,并通过 PCIe 网络连接到一个 CPU 主机。这是大多数读者所熟悉的配置形式:4个芯片 - 共8个核心,但通常被视为4个逻辑上的超级核心,可通过 Colab 或单个 TPU-VM 进行访问。对于推理优化型芯片 - TPU v5e,每个主机连接的是两个托盘而不是一个,但每个芯片仅包含一个核心,因此总共是8个芯片 / 8个核心。
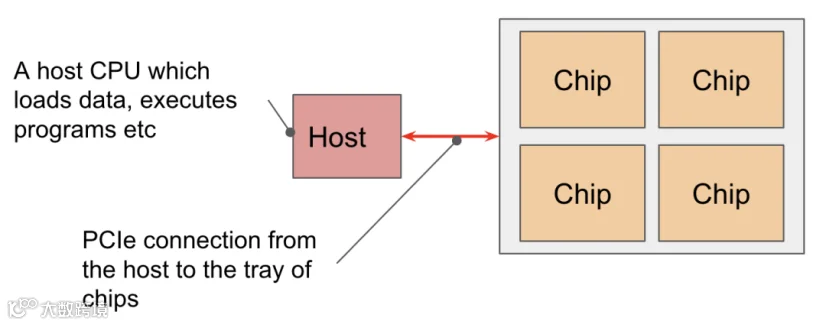
PCIe 带宽是有限的:就像 HBM 和 VMEM 的连接一样,CPU 和 HBM 的 PCIe 接口也有特定的带宽限制,这会限制从主机内存加载到 HBM 或从 HBM 回传的速度。以 TPU v4 为例,其 PCIe 带宽为每个方向 16GB/秒,约比 HBM 慢了近 100 倍。用户可以将数据加载或卸载到主机 CPU 内存中,但速度并不快。
Google Cloud 可通过 TPU VM 虚拟机将 TPU 用作计算资源。您可以直接将 TPU VM 用于工作负载,也可以通过 Google Kubernetes Engine 或 Vertex AI 使用 TPU VM。以下部分介绍了 TPU 云架构的关键组成部分。

TPU VM 虚拟机架构允许用户通过 SSH 直接连接到与 TPU 芯片物理连接的虚拟机。这些虚拟机运行 Linux 系统,具备对底层 TPU 的访问权限,并赋予用户完整的根权限,能够执行任意代码。用户可以直接查看编译器输出、运行时日志以及调试信息,从而更灵活地控制和优化 AI 工作负载。
TPU 主机是部署在连接 TPU 硬件的物理计算节点上的虚拟机。工作负载可以根据规模和需求选择不同的主机配置:单主机配置仅使用一个 TPU 虚拟机;多主机配置则将训练任务分布在多个虚拟机之间;子主机配置则只使用虚拟机上的部分 TPU 芯片资源,适用于轻量级或分片式任务。
TPU的价值已超越硬件本身——它成为衡量AI渗透速度的标尺。从医疗影像到消费终端,这场关于算力部署范围的争论,将决定下一个十年的技术竞赛走向。
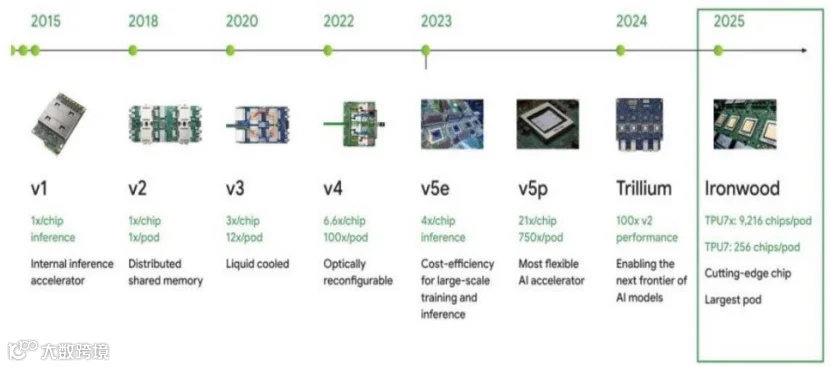
2015年谷歌发布第一代TPU起,每一代TPU系统均在性能、可扩展性与系统效率上不断提升,Google逐步将光互连技术融入TPU系统, 2025年发布的TPU v7实现了能构建9216颗大规模集群的跨越。
2018年TPU v2:每个superpod包含256颗TPU芯片,采用2D环面(2D Torus)拓扑,单芯片芯片间互连(ICI)带宽为800GB/s,尚未引入 光模块;
2020年TPU v3:超级集群芯片数提升至1024颗,仍保持2D环面拓扑,单芯片ICI带宽维持800GB/s,首次引入光互连技术,采用400Gbps 有源光缆(AOC),光通道波特率为50G;
2022年TPU v4:芯片数跃升至4096颗,拓扑升级为3D环面(3D Torus),单芯片ICI带宽调整为600GB/s,光模块升级为400G OSFP,同 时引入OCS,光通道波特率仍为50G;
2023年TPU v5p:集群芯片数增至8960颗,延续3D Torus 拓扑,单芯片ICI带宽翻倍至1200GB/s,光模块更新为800G OSFP,光通道波特 率提升至100G,OCS技术继续沿用;
2025年TPU v7(Ironwood):集群芯片数达到9216颗,保持3D Torus与1200GB/s的单芯片ICI带宽,采用800G OSFP光模块,光通道波特 率提升至200G。
谷歌的搜索、广告、翻译等核心业务在深度学习普及后,面临巨量用户请求带来的算力压力。谷歌内部AI应用需求全面爆发,如AI搜索功能AI Overview、AI Mode覆盖率大幅提升,视频-Veo3、图像-Nano Banana、世界模型-Genie3取得全面进展。这些应用对算力的需求呈指数级增长,直接驱动了TPU的发展。
模型规模持续扩大:谷歌的AI模型规模不断扩大,如Gemini系列模型,其月活跃用户已超过6.5亿,查询量环比增长3倍。大模型的训练和推理需要巨大的算力支持,TPU作为专为机器学习工作负载设计的定制化芯片,能够满足这一需求。到最近出现的Gemini3。大模型的持续的升级迭代也造就TPU芯片的升级。
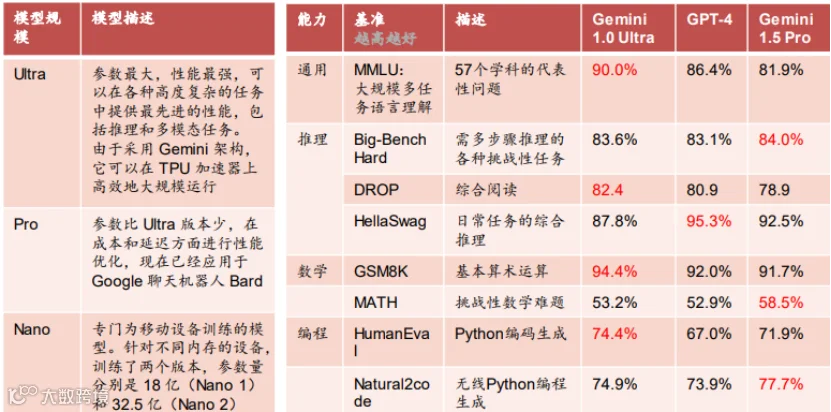
大模型的快速迭代

TPU采用极简的“脉动阵列”架构,剥离了与矩阵运算无关的硬件,从而保证了在最小单位追求深度学习的最大效率。这种架构优化使得TPU在处理AI任务时具有更高的能效比。
随着2021年,谷歌推出了 TPU 系列的最新升级 TPU v4,从 16 纳米缩减至 7 纳米,芯片数量是 TPU v3 的四倍,可以说是谷歌在 TPU 制程工艺上最大的一次更新。这一代 TPU 在内存方面也实现了显著的提升,其内存容量从 9MB 增长到 44MB,而 HBM 2 内存则保持了 32GB 的配置。
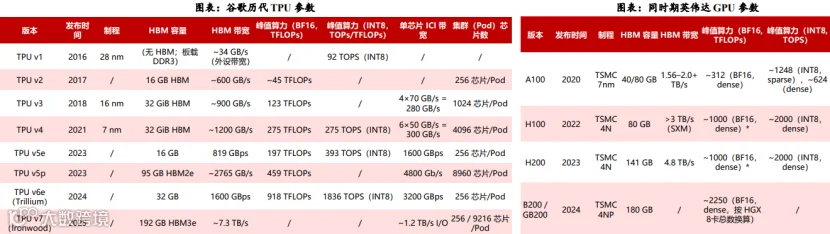
在内存带宽上,TPU v4 带来了 33%的提升,达到了 1.2TB/s。就像 v3 之于 v2,TPU v4 首次应用了 3D torus 的互联方式,提供了比 2D torus 更高的带宽和更优的性能,能够支持多达 4,096 个 TPU v4 核心,在 TPU v4 POD 中总共提供了 1.1260 exaflops 的 BF16 峰值算力。

谷歌不断推出新一代TPU,如第七代TPU“Ironwood”,其性能较上代提升10倍,单Pod算力达42.5ExaFLOPS。这种性能的提升使得TPU在处理大规模矩阵运算时更加高效,满足了AI应用对算力的极致需求。
谷歌为TPU提供了全栈AI生态支持,包括自研的JAX XLA生态工具服务。这些工具能够优化TPU的性能,提高开发效率,进一步推动了TPU的普及和应用。
通过自研TPU,谷歌减少了对英伟达等外部供应商的依赖,增强了自身在AI算力领域的自主可控能力。这种控制权的提升有助于谷歌在AI领域保持领先地位。
面对巨大的AI基础设施投入,谷歌通过自研TPU来降低算力成本。与GPU相比,TPU在特定场景下具有更高的性价比和功耗优势,能够显著降低AI应用的运营成本。
从谷歌内部视角看,TPUv7服务器的TCO比英伟达GB200服务器低约44%。即便加上谷歌和博通的利润,Anthropic通过GCP使用TPU的TCO,仍比购买GB200低约30%。
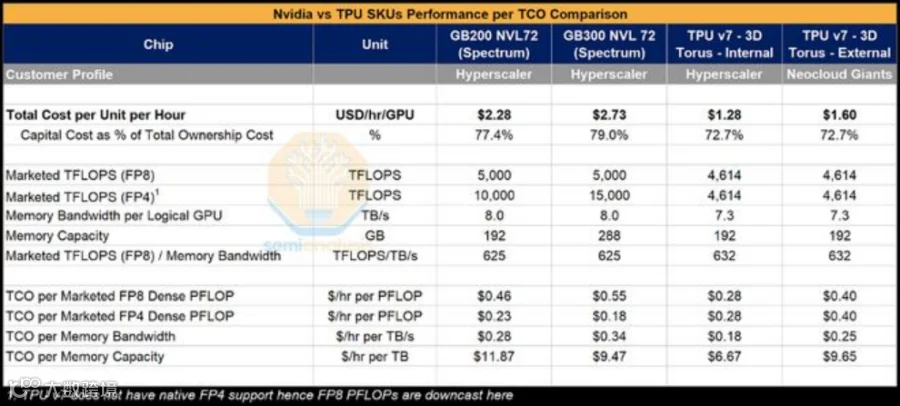
作为能在前沿模型上媲美OpenAI抗衡的大模型公司,Anthropic已确认将部署超过100万颗TPU。这笔交易的结构极具破坏力,它揭示了谷歌“混合销售”的新模式:
在这100万颗芯片中,首批约40万颗最新的TPUv7 "Ironwood"将不再通过云租赁,而是由博通直接出售给Anthropic,价值约100亿美元。博通作为TPU的长期联合设计方,在此次交易中从幕后走向台前,成为了这场算力转移的隐形赢家。
而剩余的60万颗TPUv7,则通过谷歌云进行租赁。据估算,这部分交易涉及高达420亿美元的剩余履约义务(RPO),直接支撑了谷歌云近期积压订单的暴涨。
各地政府的算力规划为TPU的发展创造了明确的需求。例如,上海30E、广东38E、贵州200E等算力规划项目为TPU提供了广阔的市场空间。Meta的“投怀送抱”,标志着谷歌TPU已从“内部工具”转变为“生态可选项”。随着越来越多企业意识到推理成本的重要性,谷歌的成本优势将不断被放大,TPU的市场份额也将在推理时代获得更快增长。
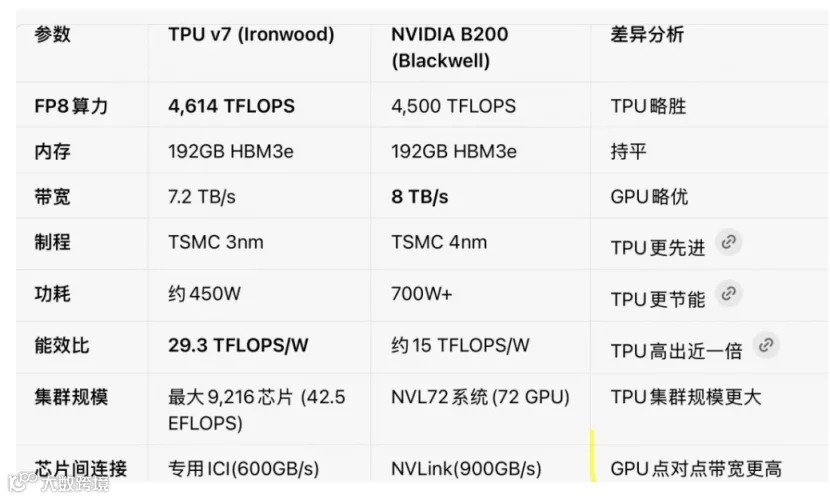
谷歌TPU在能效比上展现出压倒性优势。TPU v7(Ironwood)的每瓦性能比前代Trillium提升2倍,与TPU v4相比提升近6倍。在相同1 GW功耗下,采用3nm制程的TPU v7提供的运算能力约为采用4nm制程的NVIDIA GB200的两倍。具体到功耗表现,TPU v5e的功耗仅为英伟达H100的1/3至1/5,而Ironwood超级节点(9,216芯片)整体功耗为10 MW,通过全栈电源管理技术平滑波动。
TPU采用第三代液冷技术,拥有8年以上生产经验,部署规模超1 GW,可将PUE控制在1.1-1.25;而英伟达GPU需应对60-130 kW/机柜的高功率密度,液冷系统占资本支出15-20%,虽能降低PUE但成本更高。
GPU的成熟度碾压英伟达CUDA生态经过近20年发展,支持PyTorch、TensorFlow等主流框架,全球**超过95%**的AI工作负载运行其上。新功能(如FlashAttention)通常优先在CUDA实现,工具链完善且社区资源丰富。
相比之下,TPU生态高度封闭:仅优化TensorFlow/JAX框架,对PyTorch支持较弱,且完全绑定Google Cloud平台。开发者需适应GCP专用工具链,第三方社区支持有限,存在明显的厂商锁定风险。
硬件采购:英伟达H100单价2.5–4万美元,B200约3.5–4万美元(NVL72机柜达300万美元),而TPU仅通过云服务租用(v5e每小时1.20–1.38美元)
运营成本:TPU的高能效直接降低电力开支。若将PUE从1.5降至1.25,1 GW设施年省电费约1.6亿美元
总拥有成本:文档指出即便完全替换NVIDIA芯片,最多节省总成本20–25%,因电力和冷却仍是主要瓶颈
TPU通过光电路交换机实现9,216芯片间1.77 PB共享内存,创下共享内存规模纪录,结合RAS特性和故障自愈能力,适合超大规模部署。英伟达则依靠NVLink 5.0(带宽1.8 TB/s)实现多GPU协同,在灵活性和兼容性上更胜一筹。
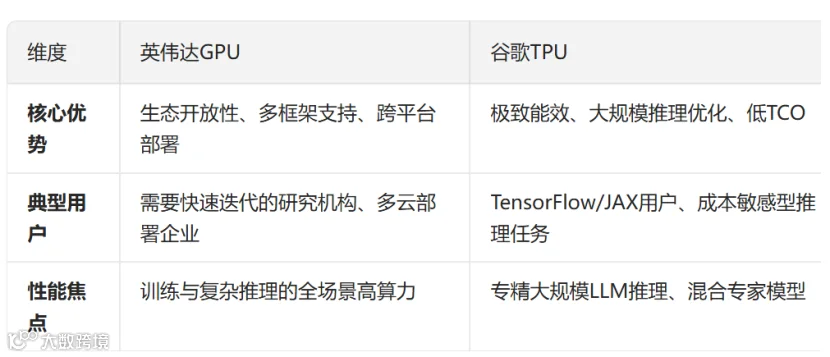
TPU是AI领域的"专精狙击手":在Google生态的深度学习矩阵运算中,以惊人的能效和性能领先,是训练超大规模模型的首选。
GPU是AI领域的"全能冠军":凭借通用性和生态优势,成为研究机构和企业的首选,在灵活性要求高的场景中无可替代。
未来趋势:TPU向推理优化倾斜(Ironwood专为推理设计),GPU强化AI专用能力(B200增强Tensor Core),两者边界逐渐模糊但仍保持核心差异—TPU追求极致效率,GPU提供无限可能。
谷歌TPU的成功并非单点突破,而是其背后一个庞大、精密且价值数百亿美元的全球供应链生态系统协同作用的结果。从上游的芯片设计与制造,到中游的核心元器件,再到下游的系统集成与配套设施,每个环节都汇集了全球顶级的供应商。
上游:设计与制造
芯片设计 (ASIC Design):谷歌负责TPU的核心架构设计,而博通(Broadcom)作为其长期独家合作伙伴,负责将谷歌的架构转化为可制造的ASIC,并提供高速SerDes等关键IP。值得注意的是,谷歌正寻求供应链多元化,已宣布与联发科(MediaTek)合作开发下一代TPU,联发科将主要负责IO模组等部分,以其成本优势和与台积电的紧密关系成为新的重要伙伴[27, 28]。
晶圆代工 (Foundry):台积电(TSMC)是TPU芯片的独家制造商。从TPU v4的7nm工艺,到v7 "Ironwood"及未来产品所依赖的更先进制程(如3nm)和CoWoS先进封装技术,台积电是支撑TPU性能飞跃的基石。据估计,谷歌每年向台积电采购的CoWoS晶圆数以万计。
封装测试 (Packaging & Testing):先进封装是AI芯片性能的关键。台湾的日月光(ASE)及其子公司矽品(SPIL)承担了TPU CoWoS-S封装任务约40-50%的份额,是台积电生态中最重要的OSAT(委外封测代工)伙伴。安靠(Amkor)则作为备选供应商,保障产能稳定。
中游:核心元器件
HBM高带宽内存:AI芯片的性能发挥高度依赖HBM。SK海力士凭借其在HBM3E及下一代HBM4上的技术领先,已成为TPU v7及后续型号的“高概率”主力供应商,其24GB堆栈产品完全匹配谷歌需求。三星(Samsung)作为追赶者,目前可能是备选供应商。美光(Micron)则暂时被排除在主力名单外。
PCB与ABF载板:高端AI服务器对PCB(印制电路板)和ABF载板提出了极高要求。TPU v7主板为36-44层的高多层板,由大陆厂商沪电股份、深南电路和胜宏科技等核心供应商提供。而作为封装基石的ABF载板,供应极度紧张,其供应商包括日本的揖斐电(Ibiden)、新光电气(Shinko)和台湾的欣兴(Unimicron)、景硕(Kinsus)等顶级玩家。
光模块与光交换机:大规模TPU集群的互联离不开光通信。谷歌采用自研的“阿波罗”光电路交换(OCS)网络,其核心部件MEMS-OCS交换机由光库科技(子公司武汉捷普)独家代工,赛微电子提供MEMS振镜。而用于机架间通信的1.6T等高速光模块,则由中际旭创.新易盛等龙头企业供应。
下游:系统集成与配套设施
服务器组装:加拿大的Celestica负责TPU服务器的板级和机架级组装,包括主板焊接、内部布线、冷却管路集成和最终测试,是TPU从芯片走向数据中心的关键执行者。
电源系统:TPU v7单机架功耗超100kW,对供电系统要求严苛。谷歌采用400V直流供电架构,其中垂直母线由泰科电子(TE Connectivity)主导,机架级电源架由台达电(Delta)、Advanced Energy提供,而板载的二次、三次电源模块则有新雷能等A股公司切入供应链。
散热系统:Ironwood全线采用液冷散热。德国Rittal和美国Vertiv提供符合OCP ORv3标准的液冷机柜,而实现热插拔的盲插快换接口(BMQC)则由Safeway、派克汉尼汾(Parker Hannifin)等四巨头供应。

博通 (Broadcom) 【AVGO】全球领先的半导体与基础设施软件解决方案供应商,业务覆盖数据中心、网络、宽带、无线通信等领域。 核心优势与合作:作为谷歌TPU各世代的共同开发者,博通提供核心的ASIC设计服务和高速SerDes IP,是TPU生态的基石。其ASIC业务中,谷歌TPU订单占比高达60%-80%。近期,博通还拿下OpenAI价值超100亿美元的定制AI加速器订单,凭借超过10年的ASIC设计经验,成为定制ASIC芯片领域的龙头。其定制化ASIC产品适配AI推理场景的低成本、高能效需求,已服务谷歌、Meta等超大规模客户。2024年,受益于云厂商的定制AI芯片需求增长,市场预期谷歌和Meta总计贡献85亿美元以上的定制芯片收入。博通CEO预计,到2027财年,ASIC需求规模将达600亿至900亿美元,显示出巨大的市场潜力。

台积电 (TSMC) :全球最大的专业集成电路制造服务(晶圆代工)企业,提供业界最先进的工艺技术和设计生态系统。 核心优势与合作:台积电是谷歌TPU芯片的独家代工厂,提供从7nm到3nm等最先进的制程工艺及CoWoS先进封装服务,是TPU实现高性能和高集成度的物理基础。谷歌第七代Ironwood TPU就采用了台积电的3nm制程工艺,单芯片峰值算力达4614 TFLOPs(FP8精度),支持192GB HBM3E内存和7.2Tbps带宽。谷歌是台积电AI相关业务的重要客户之一。 通过与台积电的合作,谷歌成功推出了多代高性能TPU芯片,如TPU v4、TPU v5、TPU v6和TPU v7等,这些芯片在AI计算任务中展现出了巨大的优势,如算力提升数十倍、能耗降低30%~50%等。

SK海力士 (SK Hynix) :全球领先的半导体存储器(DRAM和NAND闪存)制造商,尤其在HBM(高带宽内存)领域处于技术领先地位。SK海力士本身并不直接制造TPU芯片,但作为全球存储芯片领域的领军企业,其与TPU业务紧密相关,特别是为TPU提供高带宽内存(HBM)等关键存储组件,在TPU产业链中占据重要地位。SK海力士是HBM(高带宽内存)市场的核心供应商,其HBM产品广泛应用于AI服务器、数据中心等领域。TPU作为谷歌等科技巨头推出的AI专用芯片,对HBM等高性能存储芯片有着极高的需求。因此,SK海力士通过为TPU提供HBM等关键存储组件,与TPU业务形成了紧密的关联。作为HBM等高性能存储芯片的主要供应商,SK海力士在TPU产业链中扮演着关键角色。其产品的性能和质量直接影响到TPU的整体性能和稳定性。公司CEO已表示,2025年和2026年的HBM产能已基本售罄。

联发科 (MediaTek) 在TPU业务中主要与谷歌合作开发新一代TPU芯片,负责输入/输出模块设计,并借助与台积电的紧密关系保障芯片生产,同时通过成本优势和多元化合作提升在AI芯片领域的竞争力。联发科作为全球领先的芯片设计公司,在AI领域有着积极进取的态度和一定的技术实力。通过引入联发科作为新的合作伙伴,谷歌可以降低对单一供应商的依赖,提高供应链的稳定性和灵活性。
此外,联发科与台积电有着紧密的合作关系,这有助于保障下一代TPU芯片的生产顺利进行。同时,联发科每颗芯片向谷歌收取的费用低于博通,在成本方面具有一定优势。
PCB与载板

沪电股份【002463】 国内领先的印制电路板(PCB)制造商,产品广泛应用于通信通讯设备、汽车电子、数据中心、人工智能等领域。 核心优势与合作:公司是谷歌TPU PCB的核心供应商,市场份额约30%,主导30-40层高阶板的生产。受益于AI服务器和高速网络交换机需求的强劲增长,公司企业通讯市场板业务增长迅速。沪士泰国生产基地已进入小规模量产,并获得多家AI服务器及交换机客户认证,是公司全球化布局的关键。 沪电股份为谷歌TPU V6、V7及最新的Ironwood芯片提供核心PCB部件,包括TPU芯片主板等。这些产品是谷歌TPU芯片实现封装、信号传输的关键部件,直接支撑TPU芯片性能发挥。同时沪电股份是谷歌TPU电源模块PCB的独家供应商,单台TPU对应450-600元PCB需求。谷歌业务占沪电股份总营收的35%以上。2025年谷歌TPU相关订单约16亿元,占公司总营收的15%以上。随着谷歌AI战略的推进和TPU出货量的增长,沪电股份的订单规模有望进一步扩大。

深南电路 【002916】是谷歌TPU V7芯片的核心PCB供应商,为TPU V7提供44层高端PCB板,且已完成技术验证,成为独家或主要供应商之一。其供应的44层高端PCB板,单价高达2.5万元,显示出其产品的高附加值。随着谷歌TPU芯片出货量的增长和技术的不断升级,深南电路在谷歌供应链中的份额有望持续提升。预计2026年,深南电路将供应超过10万片此类高端板,占据V7高端板市场50%以上的份额。深南电路与谷歌的合作不仅提升了其在高端PCB板领域的技术水平和市场地位,还为其带来了稳定的订单和可观的收入。同时,这种合作也促进了深南电路在AI芯片领域的业务拓展和技术创新。

胜宏科技 【300476】为谷歌TPU芯片提供多种高端PCB产品,包括30层HDI板、正交背板等。这些产品用于谷歌TPU集群,是TPU芯片实现信号传输和功能实现的关键部件。胜宏科技是全球仅有的3家能量产6阶24层HDI板的企业之一,且良率达到85%,领先同业。其生产的正交背板也具有极高的技术壁垒,是下一代AI服务器实现高速互联的关键技术。胜宏科技为谷歌TPU芯片提供的PCB产品价值量显著高于传统PCB。例如,其生产的单板价值量达到英伟达GB300 PCB的300%,主要因TPU采用“低性能芯片靠高规格PCB补足”的设计路线。谷歌在高端产品研发阶段就邀请胜宏科技深度参与,甚至在某些项目中将其作为唯一的PCB研发伙伴。这种基于技术信任的深度绑定,不仅体现了胜宏科技的技术实力,也为其未来持续获得订单提供了坚实保障。胜宏科技还在提前适配谷歌TPU V8的HDI设计升级,持续深化合作绑定。这有助于胜宏科技在谷歌TPU供应链中保持领先地位,并获取更多订单。为保障对谷歌的供货,胜宏科技从2025年第四季度起已启用泰国工厂专线量产相关配套产品。谷歌还提出了提前锁定产能的要求,以确保供应链的稳定性和可靠性。有市场消息称胜宏科技拿到了谷歌相关产品40%的份额(该份额以及谷歌具体订单金额等信息尚未经公司公告确认)。随着谷歌TPU芯片出货量的增长和技术的不断升级,胜宏科技在谷歌供应链中的份额有望持续提升。2025年谷歌订单预计占胜宏科技总收入的15%-20%。随着正交背板等高端产品的放量,这一比例有望进一步提升。ASIC配套PCB毛利率超50%,显著高于公司平均水平(36.22%)。这有助于提升胜宏科技的整体盈利能力和市场竞争力。

中富电路【300814】谷歌TPU(张量处理单元)电源模块PCB的核心供应商。公司为谷歌TPU独家供应电源模块PCB,该产品支持1000A大电流输出,效率超98.5%,技术壁垒较高,能够满足TPU高密度芯片封装的电源需求。中富电路为谷歌TPU定制的电源模块PCB采用PowerSiP叠层工艺(内埋电容、电感元件)和10oz以上厚铜板设计,使信号损耗降低15%、散热效率提升40%,适配AI服务器高功率需求。单个TPU需搭配20-40个对应的电源模块,单模块单价15元,对应单个TPU的PCB价值量达450-600元。
三次电源模组需20-30层HDI+埋入式结构,毛利率达60%-70%,国内仅中富、深南电路等少数企业具备量产能力。中富电路通过台达电子、MPS等电源方案商间接供货谷歌,并与新雷能形成产业链协作:中富供应PCB,ADI提供芯片,铂科新材供应电感,新雷能负责模组总成。2025年谷歌计划出货350万颗TPU,对应约16亿元的PCB市场空间。预计中富电路可从中获得10亿元收入,占谷歌TPU电源模块PCB总量的核心份额。受益于谷歌TPU出货量的迅猛增长,中富电路的收入规模有望持续扩张。
泰国工厂产能爬坡后,预计2026年订单规模可达10亿元。
光通信

中际旭创【300308】是谷歌1.6T DR8光模块的独家供应商,占据谷歌1.6T光模块采购中约70%的份额,同时在全球1.6T光模块市场占据50%以上份额。2025年,中际旭创与谷歌的TPU相关订单金额已超50亿元,且已获得谷歌2025-2027年光模块订单约210万只。中际旭创与谷歌联合研发新一代光互连技术,深度参与TPU架构设计,获得谷歌“Preferred Partner”认证。其1.6T光模块良率达95%,较行业平均水平高出15个百分点,成本优势达30%。中际旭创的硅光集成技术能够满足谷歌数据中心低功耗需求,其1.6T光模块单价较800G产品提升3倍,同时保持高效率、高可靠性等技术特点。中际旭创扩建泰国生产基地,2025年产能提升40%,依托本地化生产规避贸易壁垒,同时将交货周期从45天缩短至15天,匹配谷歌东南亚数据中心建设节奏。中际旭创打造柔性产能体系,20条生产线可在72小时内切换产品型号,成功应对谷歌“45天交付20万只800G模块”的紧急需求并提前完工。

光库科技【300620】主要从事专业从事光纤器件、铌酸锂调制器件及光子集成器件的高新技术企业,产品应用于光纤激光、光通讯等领域。 通过子公司武汉捷普成为谷歌OCS(光电路交换机)的核心代工厂商,单台价值量高达3万美元,在BOM成本中占比最高。公司深度参与谷歌TPU集群的核心网络建设,在谷歌OCS光交换机代工领域占据超过70%的市场份额,是TPU业务中不可或缺的关键供应商。光库科技主要采用MEMS(微机电系统)技术路线,通过微型反射镜阵列改变光束传播方向。该技术相对成熟,光库科技展示的整机已实现64×64端口规模。随着谷歌TPU芯片出货量预期大幅提升,OCS需求爆发。例如,谷歌2025年OCS采购量预计达2.3万台,光库科技凭借产能优势及技术适配性,预计将保持较高代工份额。若按谷歌2026年出货量达到4.7万台的预测,且光库科技保持70%的代工份额,单是这一业务就有望为公司带来数亿元的代工收入。

赛微电子【300456】是谷歌TPU服务器光交换系统中MEMS芯片的全球独家供应商,其TPU业务以高技术壁垒、高毛利率和垄断性市场份额为核心特征,深度绑定谷歌AI算力生态,成为AI算力产业链中的关键“卖铲人”。赛微电子为谷歌TPU服务器提供核心MEMS芯片,该芯片是谷歌OCS(光电路交换机)的关键部件。OCS技术通过纯光路交换替代传统电交换机,实现低延迟、低功耗、高带宽的数据传输,是谷歌TPU集群实现高效互联的核心技术。赛微电子是全球唯一能与博世、STMicro等国际巨头竞争的MEMS代工企业,且是谷歌OCS MEMS芯片的独家供应商。在谷歌TPU所需的MEMS-OCS芯片细分市场,赛微电子占有率接近100%,形成垄断效应。赛微电子的MEMS-OCS芯片单价高达3000美元,毛利率超90%。2024年,该业务为赛微电子贡献了8000万美元的营收;2025年,已锁定超7200万美元的订单。随着谷歌TPU集群的扩容,赛微电子的订单规模有望持续增长。赛微电子掌握高精度传感器制造技术,其MEMS-OCS芯片具备低损耗、高可靠性特性,已通过谷歌7年的工艺验证,性能对标国际龙头Calient。赛微电子在瑞典、泰国、福州等地设有产线,规划总产能对应15亿元营收规模。其中,北京工厂已启动MEMS-OCS晶圆小批量试生产,通过验证后将逐步承接订单,为谷歌TPU集群的扩产提供产能保障。

德科立【688205】是国内光通信设备领域的核心代工企业,专注于为谷歌TPU集群提供OCS(光电路交换机)整机方案。作为谷歌OCS光交换机整机代工的核心供应商,德科立承担了TPU集群中高速数据交换环节的关键任务,其产品直接服务于谷歌TPU芯片的算力网络需求。德科立的OCS光交换机具备超低延迟(单跳延迟<1微秒,故障切换时间压缩至微秒级)和高带宽(单设备支持128端口、1.6T带宽)特性,能够满足TPU集群对高速数据交换的严苛要求。通过动态调节光信号透过率,德科立的OCS交换机将设备宕机风险降低50倍,确保TPU集群的稳定运行。德科立持续推进OCS技术的迭代升级,其硅基OCS光交换机已出货样机,并有望在未来实现量产代工,进一步巩固其在TPU供应链中的技术领先地位。德科立占据谷歌OCS光交换机采购份额的20%-25%,是谷歌在该领域的核心代工企业。随着谷歌TPU集群的持续扩张,德科立的相关订单增量显著,预计2025年将带来超11亿美元的营收增长。德科立正积极扩张产能,以应对谷歌TPU集群对OCS交换机的爆发式需求。其产能扩张计划包括提升国内和泰国工厂的产能规模,以满足未来几年的市场需求。随着高端产品占比的提升和毛利率的跃升(预计从30%跃升至40-50%),德科立的盈利能力将显著增强。

太辰光【300570】作为全球光通信器件核心供应商,在谷歌TPU供应链中扮演双重角色,直接向谷歌供应AOC(有源光缆)、MPO连接器等产品,替代传统DAC方案,适配谷歌数据中心光互联需求。其中MPO连接器在800G光模块中价值量占比约15%,直接受益于谷歌AI算力集群扩张。通过与国际巨头康宁的深度战略合作(自2008年起),承接康宁约70%的光纤阵列组件制造订单,按康宁的设计和技术要求完成生产、组装及初步测试后交付康宁,再由康宁整合为OCS设备核心组件供应给谷歌。单台谷歌OCS设备中,太辰光供应的FAU(光纤阵列组件)价值约1000美元,在整机产值中占比约2%。作为谷歌800G硅光模块的核心供应商之一,太辰光的产品功耗优于行业平均,良率超92%。谷歌、Meta等北美云厂商为太辰光贡献超70%收入,其中谷歌相关采购量同比增长超60%,订单稳定性强,客户粘性较高。受益于谷歌TPU集群扩张及OCS设备采购需求爆发,叠加800G/1.6T光模块迭代趋势,太辰光在连接器、光纤阵列组件等领域的订单有望持续增长。2024年来自谷歌相关业务的收入约2-3亿元,同比增长超60%。

腾景科技【688195】是谷歌TPU供应链中的关键企业,专注于为TPU芯片提供光学元件和光芯片。其产品直接服务于谷歌TPU v5e芯片的AI算力需求,是光模块的关键组成部分。腾景科技为谷歌OCS(光电路交换机)提供折射棱镜、准直透镜等核心光学元件,精度达纳米级,适配Coherent的1.6T OCS系统。其FAU光纤阵列精度±1μm,市占率超20%,显示出强大的技术实力。腾景科技的创始团队源自国际光学龙头高意光学(Coherent收购),掌握光学薄膜、衍射光学等六大核心技术平台,支持WSS模块球柱镜双偏心控制等高端工艺。这些技术壁垒使得腾景科技在光学元件领域具有显著优势。随着谷歌TPU芯片的量产,腾景科技作为供应链关键环节,有望实现业绩“从0到1”的突破。腾景科技通过Coherent间接供应谷歌OCS,单台设备光学器件价值量达4000-5000美元。2024年谷歌采购2万台OCS,对应营收约8000万美元。随着谷歌TPU出货量的增长,腾景科技的订单量也有望持续增长。腾景科技正在积极扩张产能,以满足谷歌TPU芯片对光学元件和光芯片的需求。例如,腾景科技正在泰国建设生产基地,并争取在2025年第四季度完成建设并投入使用。此外,腾景科技还在武汉建设光引擎基地,以进一步提升产能。

长芯博创【300548】通过控股子公司长芯盛(持股60.45%),成为谷歌TPU供应链中的关键一环。长芯盛作为谷歌数据中心MPO光纤连接器的核心供应商,其产品深度应用于谷歌TPU集群的高速数据传输场景,为TPU机柜间及机柜内的高密度光互联提供关键支撑。长芯盛为谷歌定制开发的144芯/192芯高密度MPO跳线,已批量用于谷歌Gemini AI算力平台,适配TPU集群对高密度光互联的需求。其独家提供的128芯/256芯MPO跳线(传统方案仅64芯),可减少谷歌数据中心30%的现场安装成本。长芯盛采用与赛微电子联合开发的MEMS芯片,插损<1dB,寿命超10万小时,适配数据中心高频切换需求,为TPU集群的光路切换提供高效解决方案。依托母公司长飞光纤的供应链,长芯盛使多模光纤成本降低15%-20%,进一步提升了其在谷歌供应链中的竞争力。长芯盛占据谷歌全球MPO连接器采购量的25%-30%,是A股中对谷歌供货份额最大的企业。谷歌是长芯盛的最大客户,占其收入的70%以上。2024年谷歌MPO采购额约4亿元,2025年预计增至7.5-8亿元,主要用于TensorFlow AI集群和Gemini大模型基础设施扩建。长芯盛基于Marvell芯片的1.6T AEC产品已在谷歌送样,若2026年通过认证,预计贡献5亿元新增年收入。长芯博创及旗下分子公司全球布局4处生产基地与5个研发中心,营销网络遍布国内外主要城市及国际市场。其中,嘉兴生产基地专注于集成光学无源器件、高速硅光模块等产品的制造,为谷歌TPU业务提供产能保障。
电源系统

新雷能【300593】是谷歌TPU(V7)电源模块的核心供应商,为谷歌TPU提供二次和三次电源模块,已进入量产阶段。作为国内特种电源龙头企业,成功切入谷歌TPU(V7)电源供应链,成为其二次和三次电源模块的核心供应商。谷歌TPU采用"一次电源-二次电源-三次电源"三级架构,单芯片功耗从V1的75W增至V7的400-1000W,AI服务器电源需求从3-5.5kW增长到8-12kW单相和22kW三相,对三次电源模块效率需超98.5%。新雷能是国内少数几家通过谷歌认证的电源供应商,其电源模块具备高效率、高可靠性等技术特点,能够满足谷歌TPU对电源模块的严苛要求。新雷能的单瓦价格比台系竞争对手低20%,这一成本优势使其在谷歌TPU电源供应链中更具竞争力。新雷能与ADI合作的电源模块已进入谷歌TPU服务器量产阶段,整体意向订单超过5亿美元。这些订单预计在2025-2026年为公司贡献可观收入,直接受益于谷歌TPU从自用转向开放供应的行业变革。同时,新雷能此前已进入英伟达供应链,AI电源业务形成"双巨头加持"格局,在算力抢装潮中占据有利位置。
散热

思泉新材【301489】作为谷歌TPU散热解决方案的核心供应商,专注于为TPU芯片提供适配的热管理产品。其核心产品0.25mm超薄VC均热板通过谷歌认证,能够满足TPU高密度芯片封装的散热需求。谷歌自第三代TPU起就采用液冷技术,第七代TPU更是支持10MW级别液冷机柜,思泉新材的产品刚好契合其散热需求。2025年,思泉新材来自谷歌的TPU散热订单已超3亿元,显示出强劲的增长势头。谷歌相关订单对思泉新材的业绩助力明显,其谷歌订单贡献占比超30%,推动公司2025年上半年净利润同比增长达103%~123%。

英维克【002837】是谷歌TPU数据中心液冷解决方案的核心供应商,其液冷技术适配TPU高密度芯片散热需求,市占率国内第一。英维克为谷歌提供的数据中心液冷解决方案支持2.6万台节点部署,2025年上半年订单同比增180%。英维克拥有全链条液冷技术,产品覆盖冷板、CDU(冷却分配单元)、快速接头等液冷关键部件,并深度绑定英伟达、英特尔等头部客户。其液冷方案可将PUE降至1.1以下,满足TPU高密度芯片散热需求。英维克的液冷系统具有高效、节能、可靠等特点,能够支持谷歌TPU集群的高效稳定运行。
封装:

长电科技【600584】谷歌TPU芯片封装的核心供应商,其2.5D/3D封装技术通过谷歌认证,为TPU芯片提供集成服务。长电科技掌握的2.5D/3D封装核心技术,通过硅通孔(TSV)和微凸块技术,成功攻克了高算力芯片散热和信号传输的难题。其XDFOI™系列封装方案可实现TPU芯片与HBM3E的2.5D集成,互联密度达1.2万T/h,较传统CoWoS方案提升30%。长电科技已进入谷歌TPU供应链,承担第七代TPU Ironwood的封装测试任务。随着谷歌TPU出货量的增长,长电科技的订单量也有望持续增长。例如,有券商研究报告指出,长电科技有望成为谷歌下一代TPU芯片封测的主力供应商。2025年,长电科技的先进封装业务占比已提升至35%,毛利率达40%,显示出其在该领域的强劲增长势头。
集成:

工业富联【601138】谷歌TPU芯片封装代工环节的核心合作伙伴,尤其在第七代TPU(代号"Ironwood")项目中获得全部产品线的代工资格。工业富联承接TPU配套AI服务器的整机组装业务,代工份额高达70-80%,是谷歌数据中心服务器的最大代工厂。服务器组装涉及主板集成、光模块安装及液冷系统调试等复杂工序,工业富联凭借富士康体系的制造经验,实现规模化交付。2025年,工业富联拿下了谷歌全球60%的AI服务器订单,这些服务器包含谷歌TPU相关机型。
工业富联通过高精度封装工艺解决芯片集成与散热难题,满足谷歌对算力密度和能效的要求。其独创的“冷板式+浸没式”混合液冷方案通过谷歌认证,能将9216颗TPU芯片集群的温度波动控制在±2℃以内,为TPU服务器的稳定运行提供散热保障。工业富联为谷歌提供算力相关定制化解决方案,如正交背板、高密度互联PCB等关键部件,单服务器价值量较传统产品提升3倍。其多区域工厂布局可匹配谷歌全球化供货需求,泰国工厂自2025年第四季度起专供谷歌订单,预计2026年相关收入贡献超45亿元。
2025年,工业富联来自谷歌的订单呈现爆发式增长。封装测试业务第二季度订单同比增长150%,主要来自TPU V7的批量交付。整机制造业务同步承接TPU配套AI服务器组装,形成“芯片+系统”的协同供应模式。
工业富联在谷歌自研AC芯片服务器中的代工份额占比约30%,在AWS自研AC芯片服务器中的代工份额占比约40%,是谷歌云服务器的重要代工厂商。工业富联在越南新建的TPU封装产线月产能达20万颗,泰国工厂自2025年第四季度起专供谷歌订单。其越南基地专线量产模式确保交付稳定性,为谷歌TPU的稳定供应提供了有力保障。
【文章综合文心一言.雪球.华泰证券.国泰君安.中泰证券.浙商证券,谷歌AI.baihaiIDP.老虎说芯.量子位.新智元综合】
投资有风险,入市须谨慎,本文内容为整合梳理,本平台不主动加人,主动加人均不是本账号主理人,请仔细甄别。
推荐阅读
一文读懂光模块结构.分类.产业链,市场和未来展望
一文看懂九天无人机的特点.产业链和核心企业梳理
一文看懂SST固态变压器市场规模,产业链和核心企业梳理
一文看懂固态电池发展现状 竞争格局 产业链 和核心企业梳理(材料篇)
一文看懂航母结构 产业链和核心企业梳理
一文看懂光芯片结构.产业链.竞争格局.核心企业和未来展望
一文看懂歼“10”战机的特点.产业链和核心企业梳理
一文看懂军工信息化的政策.发展状况 产业链 和未来展望
一文看懂CJ1000航空发动机的特点.产业链和核心企业梳理
一文看懂我国EDA发展驱动因素 竞争格局 产业链 和未来展望
一文看懂可控核聚变特点.发展状况 产业链和未来展望
一文看懂AI玩具产业链.发展状况 竞争格局和未来展望
一文看懂国内核电发展历程 产业链.竞争格局.发展现状和重点企业梳理
一文看懂RISC-V芯片特点.政策.融资市场前景和重点企业产业链梳理
一文读懂鸿蒙系统(HarmonyOS)的特性.架构.发展历程,应用领域和核心生态企业梳理
一文看懂无人车特点、结构、分类 、场景、产业链 、发展和未来展望
一文看懂GPU分类、结构、发展历程、 产业链、市场和核心企业梳理
一文看懂大飞机结构.产业政策.发展历程.产业链和前景展望【附大飞机产业链核心企业结构图】
一文看懂水电工作原理、优缺点、产业链、政策、市场现状和未来展望
一文看懂人形机器人的生产.结构.产业链.政策.市场和未来展望
一文看懂液冷服务器分类 构成 产业链 市场和未来展望
一文看懂服务机器人的应用,结构制造,产业链和市场发展
一文看懂水下机器人的结构.生产流程.产业链、市场格局和行业展望
一文看懂注塑机的分类、结构、特点、 产业链 和市场趋势
一文看懂空心杯电机的分类 结构 产业链 市场 竞争格局和未来展望
一文了解3D打印机原理.结构.产业链.市场和未来展望
一文看懂eVTOL飞行汽车的分类,结构,产业链,市场分析和行业展望
一文看懂直升机结构,生产过程,产业链,市场和行业展望
一文看懂AI手机的特点.产业链.发展现状.核心驱动力和未来展望
一文看懂摩托车的发展史、生产、结构、市场 、产业链和未来展望
一文看懂导弹工作原理.分类 结构 生产流程 产业链和未来展望
一文看懂雷达工作原理、分类、结构、产业链、政策、市场和未来展望
因为公众号平台更改了推送规则。 如果你不想错过内容,记得标记微信为星号,记得点下“赞”和“在看”。这样每次新文章推送,就会第一时间出现在你的订阅号列表里啦