
关键词:AI Inference、Energy Efficiency、Large Language Models、Token Throughput、Hardware Optimization、Test-Time Scaling
随着 AI 推理规模扩大至数十亿次查询,且新兴的推理型和智能体工作流大幅增加 token 需求,每查询能耗的可靠估算对于容量规划、排放核算和能效优先级排序而言愈发重要。
-
投机解码(speculative decoding)已实现 2-3 倍的 TPS 提升 -
解耦服务(disaggregated serving)可将推理的预填充与解码阶段分离,并为每个阶段分配不同资源、缓存或加速器进行优化,从而实现 1.4-2.3 倍的 TPS 提升
然而,许多公开估算往往存在不一致性,且会系统性高估能耗——这是因为这些估算从有限基准中推断,未能反映大规模部署所能实现的能效提升。

-
Energy Use of AI Inference: Efficiency Pathways and Test-Time Compute -
https://arxiv.org/abs/2509.20241 -
本文 9786 字,阅读需 30 分钟,播客 25 分钟
-
30.9% 能耗节省!亚秒级 GPU 频率实时决策框架 AGFT:实现LLM推理实时功耗与性能的平衡术!低侵入且不降服务质量! -
2.6 倍加速,能耗降 1.4 倍!量化算法与硬件协同设计混合精度 GEMM 加速器 MixPE -
八款神经网络加速器 μNPU 全面评估:从 Arm 到 RISC-V 架构,从超低功耗到高性能 SoC,评估性能、功耗和内存开销
本文提出一种自下而上的方法,基于 token 吞吐量估算来评估大规模 LLM 系统的每查询能耗。
对于在真实工作负载、GPU 利用率和 PUE(电源使用效率)约束下运行于 H100 节点的模型,我们估算前沿规模模型(参数>200 亿)的每查询能耗中位数为 0.34 Wh(四分位距:0.18-0.67)。
这些结果与生产级配置的测量数据一致,且表明非生产环境下的估算和假设会将能耗高估 4-20 倍。将场景扩展至“测试时扩展”(典型查询的 token 数量增加 15 倍),每查询能耗中位数会增长 13 倍,达到 4.32 Wh,这表明针对该场景优化能效有望实现全集群最大幅度的能耗节省。
我们还探究了如何针对性实施能效干预措施以最大化节能效果:通过量化模型、服务平台和硬件层面可实现的能效提升,发现单一干预手段可使每查询能耗中位数降低 1.5-3.5 倍,而组合改进则有望实现 8-20 倍的降幅。
为说明系统级影响,我们估算:
-
每日处理 10 亿次查询的部署,其基准日能耗为 0.8 GWh; -
若其中 10%为长查询,能耗需求可能增至 1.8 GWh; -
而通过针对性能效干预,能耗可降至 0.9 GWh/天——这一水平与同等规模网络搜索的能源相当。
这与数据中心的历史规律相呼应:在互联网和云建设时期,数据中心正是通过能效提升来应对能源增长的。

关键问题
问题 1. 非生产能耗高估的认知影响与优化优先级扭曲问题
论文指出非生产环境的能耗估算会高估 4–20 倍,而政策制定与产业资源配置常依赖这类公开数据,这种高估是否已导致对 AI 推理能耗的“恐慌性认知”?又会如何扭曲效率优化的优先级(比如过度聚焦硬件而非模型/服务优化)?
这种高估确实易引发对 AI 推理能耗的“恐慌性认知”,论文明确指出非生产估算因未考虑批处理、并发等生产级优化,导致 4–20× 的偏差。在优化优先级上,若受高估数据误导,可能过度聚焦硬件升级,却忽视潜力更大的模型与服务优化——论文显示模型层面(蒸馏、量化等)可实现 1.5–10× 能耗降低,服务平台优化达 1.5–5×,均优于硬件的 1.5–2.5×,这种认知扭曲会错失更高效的降碳路径 。
问题 2. 模型/服务/硬件三类优化的技术依赖关系与叠加效应问题
测试时扩展场景(长查询)是能耗控制的核心前沿,但论文提到模型、服务、硬件的组合优化可达 8–20 倍降幅,这三类优化存在明确的技术依赖关系吗?例如,是否必须先完成特定硬件升级,模型蒸馏的能耗收益才能最大化?
三类优化不存在明确的技术依赖关系,可独立实施且收益可叠加。
-
【模型层面】蒸馏技术已能让小模型实现与大模型相当的推理性能,无需依赖硬件升级;FP8 量化在现有 H100 GPU 上已实现 1.5–2× 吞吐量提升,不依赖新型硬件 。 -
【服务层面】自适应部署、KV 缓存管理等技术可直接在现有硬件与模型架构上落地,例如分离预填充与解码阶段的解耦服务,能在分布式环境中实现 1.4–4×TPS 提升 。 -
【硬件升级】(如 Blackwell GPU)可独立提升能效,但模型与服务优化的收益并不以硬件更新为前提,组合优化时反而能实现 8–20× 的叠加降幅 。
问题 3. 单节点估算假设的偏差性及对核心结论的影响问题
论文的能耗估算基于单节点高利用率假设,且未充分纳入分布式系统的网络开销、动态负载波动等现实因素,那么用该方法估算的“10 亿查询日能耗”(如基线 0.8 GWh)在真实大规模部署中可能存在多大偏差?这种偏差是否会让“AI 推理能耗接近网页搜索”的结论失去参考意义?
真实部署中的偏差可控,不会使“AI 推理能耗接近网页搜索”的结论失去参考意义。论文通过引入 scaling factor b=1.33,已部分修正非均匀需求、节点冗余与网络开销的影响 。
虽未完全纳入分布式系统的网络延迟等细节,但局限性分析指出,此类因素对能耗的影响远小于查询长度、模型优化等核心变量——测试时扩展场景下,仅输出token增加就导致 13 倍能耗增长,而分布式开销的影响远低于此 。
此外,历史数据显示数字基建能耗常被高估,而 AI 推理的效率提升速度(8–20× 潜力)足以覆盖潜在偏差,优化后 0.9 GWh/10 亿查询的估算仍与网页搜索的 0.3 GWh 处于可比较的量级 。
本文目录
- 关键问题
- 问题 1. 非生产能耗高估的认知影响与优化优先级扭曲问题
- 问题 2. 模型/服务/硬件三类优化的技术依赖关系与叠加效应问题
- 问题 3. 单节点估算假设的偏差性及对核心结论的影响问题
- 本文目录
- 一、引言
- 二、大规模部署中每查询能耗的估算
- 三、可实现的能耗降低路径
- 3.1 模型层面( )
- 3.2 服务平台与工作负载管理层面( )
- 3.3 硬件与数据中心层面( )
- 3.4 不同措施的效果总结
- 四、每日 10 亿次查询的能耗情况
- 五、结论
- 参考文献
 交流加群请在 NeuralTalk 公众号后台回复:加群
交流加群请在 NeuralTalk 公众号后台回复:加群
一、引言
大型语言模型(LLM)推理是增长最快的计算需求来源之一,其能耗已接近网络搜索及其他成熟数字服务的能耗水平[1]、[2]、[3]。因此,许多相关方都在寻求推理过程中细粒度能耗数据(例如,文本查询的能耗)的可靠数值,以便为能源预测提供坚实基础、比较不同服务方法,并将能效考量与工程及产品权衡相关联。尽管存在这一需求,公开报告中“每查询能耗”的数值差异却超过一个数量级[2]、[4]。
造成这种差异的原因有两点。
-
首先,测量范围存在差异:部分估算仅计入 GPU 功耗,而其他估算则包含 CPU 或应用开销。 -
其次,许多基准测试未能捕捉真实的生产环境条件,例如批处理、并发和稳态服务[5]、[6]、[7]。 -
此外,基于模型的估算对硬件规格、参数数量和 token 长度等假设高度敏感[8]、[9]、[10]。尽管直接测量的精度更高,但这类测量往往局限于非生产模型或小批量测试[6]——相较于处理大部分 AI 推理工作负载的大型高并发部署,这些场景会高估能耗。
评估推理能耗还面临一个额外挑战:每查询能耗数值无法孤立解读。推理能耗还取决于以下两个因素:处理数十亿次查询时能源需求的增长方式,以及在模型、服务软件和硬件层面实施的干预措施如何减缓这种增长。
近期模型提供商通过测量大规模系统,披露了更贴近实际的基准数据[2]、[11],但这些数据受限于保密性。通常,这类报告仅包含单一的“代表性”或“平均”查询数据,掩盖了能耗随查询长度分布、模型及服务配置变化的规律。这一局限性不容忽视:
-
测试时扩展(推理模型)和智能体工作流正日益普及,其超长输出会在总能耗中占据过高比例。若缺乏这一系统背景,平均能耗数据会对推理能耗产生误导性认知; -
此外,这类指标也无法为未来能效工作的重点方向提供指导。
鉴于上述局限性,我们提出一种自下而上的估算方法以填补空白。我们的框架与生产级披露数据保持一致,同时增加了两项贡献:
-
分解每查询能耗的相互作用决定因素——模型、服务平台和硬件,为实际能效干预措施提供洞见; -
对 token 长度分布进行显式建模,揭示长推理过程如何增加每查询能耗。
二、大规模部署中每查询能耗的估算
为估算文本查询的能耗,我们聚焦于通过批处理、高并发和优化服务实现节点饱和运行的大规模部署场景。大型语言模型(LLM)推理包含两个阶段:预填充阶段(prefill)——输入序列通过并行方式一次性处理;以及解码阶段(decoding)——输出 token 逐一生成。由于解码阶段无法跨 token 实现并行化,其在多数实际工作负载中主导能耗消耗,而这一趋势在推理型任务和智能体工作流(agentic workflows)中会进一步加剧[12]。
我们的估算框架正是基于上述场景设计的。我们提出一种自下而上的蒙特卡洛模拟方法,以捕捉各类开源模型的上述交互因素。对于固定的 GPU 节点,每查询能耗 (单位:Wh,瓦时)的估算公式如下:
在此公式中,各参数定义如下:
-
:推理过程中单个 GPU 节点的稳态功耗。在本分析中,我们假设模型部署于采用 FP8 精度的 8 卡 H100 GPU(符合 NVIDIA DGX H100 架构[13]),或 10 卡 H100 GPU(DeepSeek-R1 模型的部署场景),其最大功耗 分别为 11.3 千瓦(kW)和 14.1 千瓦(按线性比例换算)。已有研究表明,在高利用率节点中,推理过程的平均功耗利用率约为 70%[12,4]。因此,我们将 建模为以 为中心的对数正态分布,其 P5-95 分位数范围为 至 。闲置节点与额外开销的综合影响将在后续部分探讨。 -
PUE(能源使用效率):AI 数据中心的能源使用效率,建模为对数正态分布,其 P5-95 分位数范围为 1.05-1.40,这与超大规模数据中心(hyperscaler)的公开报告一致。 -
常数 3.6:用于将千瓦(kW)换算为瓦时(Wh)。 -
与 :分别表示单个查询的输入 token 数与输出 token 数。我们通过对 选取离散值、对 采用指数分布抽样的方式,建模多种工作负载,并分析两类场景: -
传统场景:常见于无密集型测试时扩展的对话式查询[14],输出 token 数中位数 (四分位距 IQR:129-618); -
测试时扩展场景:包含推理型模型(如 OpenAI o3[15]、DeepSeek-R1[16])或长智能体工作流中的长查询,输出 token 数中位数 (四分位距 IQR:2040-9717)[17]。 -
:有效 token 长度,其值随查询中的 token 总数缩放能耗。由于输出 token 主导能耗消耗,我们近似认为 ,并在主要分析中固定 。在补充材料 S.III 中,我们还探讨了其他 与 的配置方案。 -
TPS(每秒 token 吞吐量):每秒处理的 token 数量。TPS 会随模型架构、部署配置、并发量和延迟约束而变化。
在本研究中,由于我们关注稳态部署下的能耗建模,因此基于 H100 GPU 的现有基准数据(采用 NVIDIA TensorRT-LLM[18,19],并行度设为 8,DeepSeek-R1 模型设为 10,并启用连续批处理)进行估算。
我们已针对部署于 8 卡 H100 GPU 的目标模型,在多种 与 配置下测量了 TPS 值。这些基准中报告的 TPS 近似反映了高并发下完全饱和节点的吞吐量。在模拟中, 是基于上述整理后数据训练的分段对数线性回归模型。
-
该对数线性模型的训练数据覆盖输出 token 数 up to 4000 的场景; -
对于更长的输出,我们将 TPS 固定在平台期(plateau)水平,而非建模因 KV(键值)和注意力开销增加导致的吞吐量逐渐下降。
这种简化虽可能低估极长生成任务的能耗,但提供了一个保守的基准值。尽管 TPS 与 存在相关性,但为简化分析,我们在主要分析中将二者视为相互独立,并探讨了线性相关性场景,结果与主要分析基本一致。
为估算 ,我们对 、 和 PUE 的 10,000 种随机配置进行抽样,并计算特定模型对应的 TPS 值。

图 1 汇总了 5 个稠密模型与混合专家(MoE)模型的结果:DeepSeek-R1 671B、Llama 3.1 405B、Llama 3.1 Nemotron Ultra 235B、Mixtral 8x22B 和 Llama 3.1 70B。在传统场景(图 1a)中,我们的蒙特卡洛估算结果与生产级优化部署的实测能耗一致。
-
Llama 3.1 405B 的每查询能耗中位数为 0.43 Wh,与 ML.ENERGY 排行榜[4]中 8 卡 H100 节点的中位数(0.548 Wh)一致(该排行榜中 BF16 量化下能耗为 0.931 Wh,采用 FP8 量化后约为 0.931/1.7=0.548 Wh) -
Mixtral 8x22B 的估算每查询能耗中位数为 0.07 Wh,接近 ML.ENERGY 排行榜的 0.092 Wh。
若不考虑生产级部署优化,每查询能耗估算值会显著偏高:
-
AI Energy Score[6]报告 Llama 3.1 70B 的每查询能耗约为 0.86 Wh(基于 1000 次 FP16 量化查询的平均值 1.72 Wh,FP8 量化下约为 1.72/2=0.86 Wh); -
在类似假设下,国际能源署(IEA)[20]估算 Mixtral 8x22B 的每查询能耗约为 1.25 Wh,DeepSeek-R1 约为 2.25 Wh。
这些后者估算未考虑批处理、推理加速等基础生产级优化技术,导致每查询能耗被高估 4-20 倍。以这些数值作为基准或外推至大规模推理场景,无法反映广泛使用的 AI 产品的实际能耗。

我们的方法还估算了测试时扩展查询的能耗(图 1b)。正如预期,每查询能耗随总输出 token 数近似线性增长。极长查询的能耗成本可能很高,但像 Mixtral 8x22B 这类在长查询中仍能保持高吞吐量的模型,在相同参数规模下似乎具备缩放优势。
三、可实现的能耗降低路径
为分析能耗影响与能效优化机会,我们定义了“基准(Baseline)”能耗场景:通过抽样上述 3 个参数超 2000 亿的模型(图 1a:DeepSeek-R1 671B、Llama 3.1 405B、Llama 3.1 Nemotron Ultra 253B)的估算能耗得到。该参数阈值的设定基于主流前沿规模模型的尺寸,包括 DeepSeek-R1[16]、Llama 3.1 405B[21]、Qwen 3[22]等开源权重模型,同时也适用于 GPT-4o、Claude 3.5 Sonnet[23]等专有模型的合理参数范围。

如图 2 所示,参数超 2000 亿的模型在基准场景下的每查询能耗中位数为 0.34 Wh(IQR:0.18-0.67),这与高度优化部署中典型聊天机器人查询的近期估算结果一致:
-
输出 token 数为 500 的典型 GPT-4o 查询:0.3 Wh(基于 2000 亿参数模型的 FLOPs 启发式估算)[10]; -
输出 token 数为 300 的 GPT-4o 查询:0.421 Wh(基于用户端 token 吞吐量)[8]; -
Sam Altman 披露的 ChatGPT“平均每查询能耗”:0.34 Wh[11]; -
Gemini Apps“典型每查询能耗”:0.24 Wh[2]。
尽管由于产品、模型、工作负载和测量方法的多样性,这一对比并非标准化,但该能耗范围仍显著低于以往广泛报道的估算值,且与网页搜索的常用能耗(0.3 Wh[24])相当。与上一代模型相比,能耗改善源于多方面因素:新一代前沿模型尺寸减小(从 Kaplan 缩放律转向 Chinchilla 缩放律,使得模型更小但训练数据更多)[23]、硬件能效提升[25],以及模型与服务优化。
-
基准场景:4.32 Wh(IQR:2.38-7.78)
在测试时扩展场景中,对参数超 2000 亿模型的抽样显示,每查询能耗中位数为 4.32 Wh(IQR:2.38-7.38),且相当一部分查询的能耗超过 10 Wh。鉴于其巨大的能耗占比,即使测试时扩展查询或 token 密集型智能体工作流的占比不高,也可能对 AI 推理的总能耗产生重大影响。在我们看来,这一领域是能效优化的关键前沿方向。
为此,我们定义了若干可实现的能效优化机会,并量化其潜在影响。
-
我们对公式(1)进行修正,引入乘数 以缩放吞吐量(TPS, 倍提升)或每查询能耗( , 倍降低); -
在固定计算节点的前提下, 被建模为对数正态分布,其 P5-95 分位数范围基于文献估算,以反映各优化措施影响的不确定性。
我们将这些优化措施分为下面三类。
3.1 模型层面( )
算法与架构改进是推理工作负载能效提升的最大驱动力。基于近期技术进展,我们估算下一代部署的可实现优化空间为 1.5-10 倍。
-
模型蒸馏(model distillation)技术已实现 5-10 倍的能耗降低[2]。值得注意的是,模型蒸馏不仅能构建 FLOP 高效模型,还能在相同硬件下支持更大批处理量,从而可能减少隐含排放(embodied emissions)。蒸馏技术在推理型模型中已被证实有效:具有更长推理过程的小型模型可优于大型非推理模型,例如,从 DeepSeek-R1 蒸馏得到的 70 亿至 700 亿参数推理模型,其性能可与规模为其 3-5 倍的模型相当[16];经过精心蒸馏的 Qwen 3 推理模型也优于更大规模的模型[22]。在某些领域(如数学、编码或特定智能体工作流),小型语言模型(SLM)相比参数超 1000 亿的模型,可将能耗降低 1-2 个数量级[26,27,28]。 -
模型量化(model quantization)已在生产中产生显著影响:H100 GPU 的 FP8 量化相比 FP16,已实现 1.5-2 倍的 TPS 提升。若模型性能保持稳定,新型硬件支持的低比特量化技术有望将推理 TPS 再提升 1.3-3 倍[29,30]。尽管量化模型可在大规模部署中支持高效并行与请求管理,但仍需解决大规模批处理下运行高量化模型的技术挑战[31]。 -
混合专家模型(MoE)在降低推理计算量方面已展现出优于同等规模稠密模型的性能。目前已出现多种 MoE 推理优化方法,包括优化专家并行(如 DeepSpeed-MoE[32])、动态选通与负载均衡(如 Tutel[33])、专家卸载/缓存(如 MoE-Lightning[34])。这些方法根据基准场景与工作负载的不同,可实现 1.3-8 倍的推理加速。 -
注意力操作与架构的推理优化也在推进,例如 FlashAttention[35]、多头潜在注意力(Multi-Head Latent Attention[16]),以及长序列生成优化。在高效推理型模型方面,Llama-Nemotron[19]通过神经架构搜索、选择性注意力移除和前馈网络优化,实现了相比 DeepSeek-R1 1.9-4 倍的 TPS 提升。采用线性注意力或滑动注意力变体的混合注意力模型,在测试时扩展场景中也实现了性能提升[36,37],例如,MiniMax-M1[37]生成 10 万个 token 的 FLOP 消耗量仅为 DeepSeek-R1 的 1/4。
3.2 服务平台与工作负载管理层面( )
针对服务级别目标(SLO)优化模型部署,对推理的能耗与碳足迹具有显著影响[1,38,39]。此外,大规模 AI 系统可通过工作流管理实现能效提升,例如根据查询复杂度路由至不同模型。我们估算此类干预措施的可实现优化空间为 1.5-5 倍。
-
基于服务级别目标的自适应服务(adaptive serving)已实现超 50%的能耗降低[38]。解耦服务(disaggregated serving)可将推理的预填充与解码阶段分离,并为每个阶段分配不同资源、缓存或加速器进行优化[40,41],从而实现 1.4-2.3 倍的 TPS 提升[38]。得益于解耦设计,解码阶段的资源利用率优化在长生成任务和智能体工作流中尤为有效:在分布式场景下,结合动态 GPU 分配、智能路由和低延迟通信[39],可实现 1.4-4 倍的 TPS 提升[41,42]。 -
KV 缓存管理与量化是服务优化的关键技术:PQCache、KVQuant、LServe 等技术已实现长序列生成场景下超 1.7 倍的推理加速[36,43,44];投机解码(speculative decoding)已实现 2-3 倍的 TPS 提升[45]。 -
自动或用户触发的模型路由(model routing)对 token 吞吐量、内存与 token 利用率具有重大影响,已成为 GPT-5 等下一代模型的主流技术。这一技术在推理型模型中尤为实用:我们估算,支持推理能力显式切换的模型,可通过缩短查询长度将每查询能耗降低 5 倍以上。智能模型路由能在保持响应性能的同时降低每查询能耗与成本,例如,结合持续学习的路由方法可在保持 97%响应质量的前提下,实现约 2-4 倍的成本降低[46,47];DeepConf[48]提出的低质量推理轨迹动态过滤技术,可在实现 99.9%准确率的同时,将查询长度缩短约 5 倍。
3.3 硬件与数据中心层面( )
硬件与数据中心技术进展仍是推理加速的基础。
-
NVIDIA Blackwell 架构相比 H100/H200 GPU,在每瓦 TPS 方面实现了显著提升:在运行 Llama 3.1 405B 的 MLPerf 推理基准 v5.0 中,单张 Blackwell B200 GPU 的 TPS 是 H100 的 2.8-3.4 倍[49]; -
SemiAnalysis 指出,在相同量化水平下,Blackwell 架构的每 GPU 瓦 TFLOPS 相比 H100 提升 47-82%[25]。
除商用 GPU 外,定制 AI 推理芯片(如 ASIC、FPGA)的每瓦 TPS 提升约为 5-20 倍[50],部分原因是其在内存受限的解码阶段表现更优——这是测试时扩展场景的关键能力。此外,超分配(oversubscription)、电压/频率缩放(voltage/frequency scaling)、功率封顶(power capping)等电源管理技术,可在现有集群中多部署 30%的服务器,并降低 20%的峰值功耗[12]。
在数据中心层面,冷却优化可进一步提升能效,例如冷板式冷却(cold-plate cooling)和浸没式冷却(immersion cooling)相比风冷,可降低 15-20%的能耗需求[51]。
综合来看,不考虑量化改进或定制硬件的情况下,这些数据表明每 GPU 瓦 TPS 可提升 1.5-2.5 倍。
3.4 不同措施的效果总结

图 2 汇总了这些干预措施的估算影响(假设各类措施效果不叠加)。
-
在传统场景中,硬件改进或服务优化可将典型查询的能耗降低一半; -
模型改进虽可能实现更大幅度的降低(约 4 倍),但需以保持模型性能竞争力为前提。在推理场景中,这些干预措施的能耗降低效果相近,但显著降低了长尾 P95 能耗。 -
模型与服务平台优化的影响尤为显著(约 3-4 倍),为测试时扩展场景的密集使用开辟了路径:经过优化的、输出 token 数中位数为 5000 的推理查询,其能耗可降至约 1 Wh,与未优化的小型查询能耗相当。
综合这些优化措施,我们发现所提出的可实现干预措施有望将每查询能耗降低 8-20 倍甚至更多(例如,硬件改进实现 1.5-2 倍降低,结合模型改进实现 3-4 倍降低,和/或服务与工作流优化实现 2-3 倍降低),这一提升幅度与大规模生产系统中报告的结果一致[2]。
四、每日 10 亿次查询的能耗情况
基于上述场景,我们推算出每日处理 10 亿次查询的能耗规模。10 亿次查询的量级与主流对话式 AI 平台报告的使用模式相符[52][53]——例如,截至 2025 年 7 月,ChatGPT 的日查询量已达 25 亿次[53],这一规模也与主流网页搜索平台每日约 100 亿次的查询量相近[54]。
利用本文提出的框架,我们对基准场景下处理 10 亿次查询的能耗进行了抽样估算,并计算出总能耗。由于我们的估算基于节点级数据,因此需将总能耗估算值乘以系数 ,以涵盖日间非均匀需求分布、节点冗余及 InfiniBand 高速网络的额外能耗[55]。
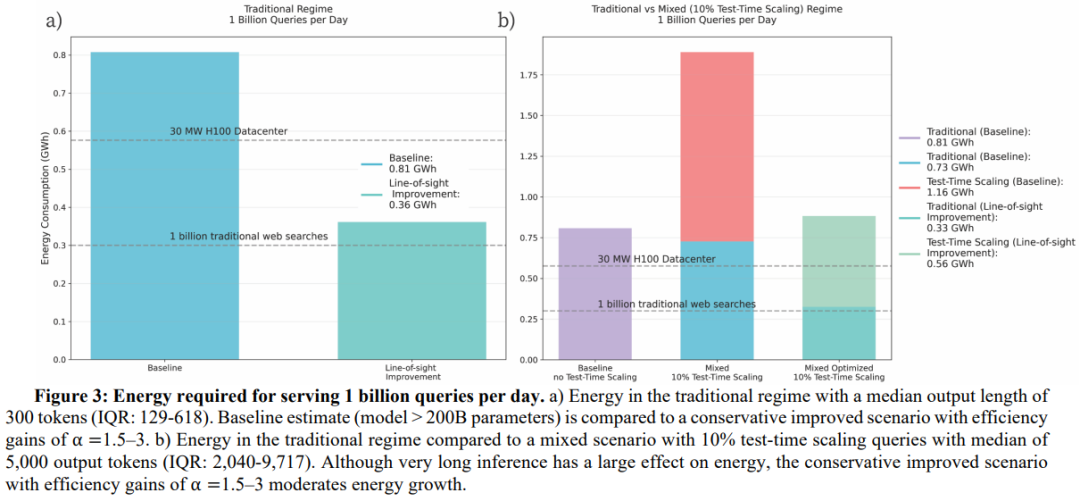
图 3a 展示了每日处理 10 亿次传统查询的总能耗。
-
在“基准”场景(未优化)下,总能耗为 0.81 吉瓦时(GWh); -
而在非常保守的可实现改进场景( )下,能耗可降至基准值的一半以下。
作为参考,一个 30 兆瓦(MW)的 H100 数据中心若以 80%的利用率持续运行,每日能耗将低于 0.6 吉瓦时,与“基准”场景的能耗水平相当。若采用网页搜索的普遍能耗数据计算,10 亿次网页搜索的能耗约为 0.3 吉瓦时。
由此可见,通过对 AI 推理进行保守的可实现改进,传统 AI 推理的能耗足迹可降至与网页搜索相当的范围,同时 AI 的实用性仍远高于网页搜索。
与以往研究结论[2][6][20]不同的是,由于推理任务可在不同地区和电网间分布式部署,其能耗虽规模较大但可控:即使 AI 推理的日查询量增至 100 亿次(与网页搜索规模持平),年均能耗也仅约 1.32 太瓦时(TWh),仅占当前微软、谷歌等超大规模云服务商能耗的 6%左右,或美国数据中心当前总用电量的 1%[20][56]。电网中 AI 新增负载的主要压力并非来自推理能耗,而是来自模型训练能耗、AI普及速率及集中式算力建设——这些因素更难实现分布式部署与优化。
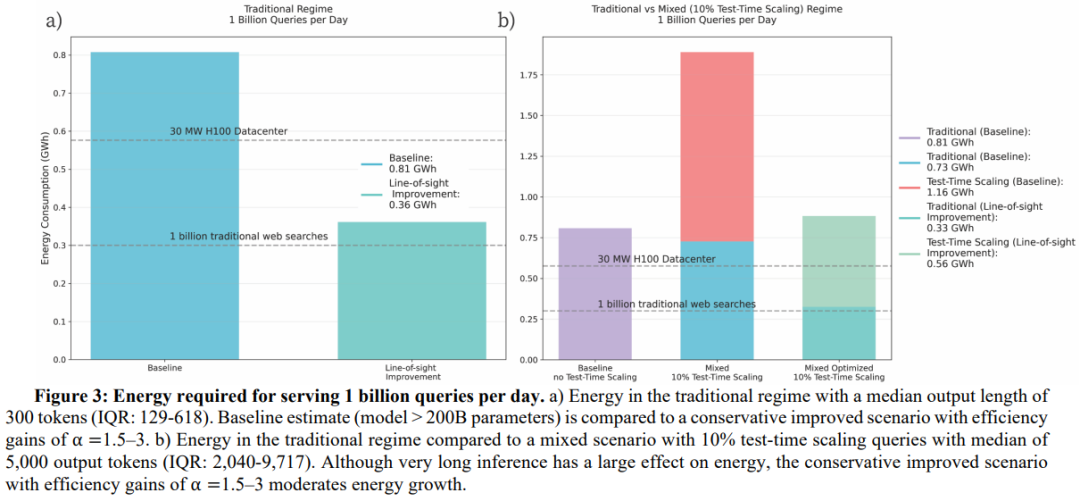
然而,测试时扩展(test-time scaling)场景仍需重点关注。在图 3b 中,我们模拟了一种混合推理场景:90%的查询为传统查询,10%为长推理查询。若不考虑任何改进措施,简单估算将导致能耗呈倍增趋势:在“基准”场景下,10%的测试时扩展查询可使每日处理 10 亿次查询的能耗增加一倍以上。但通过可实现的效率改进(包括模型路由与工作流管理),无需依赖算法突破即可有效抑制这种能耗增长。在包含 10%测试时扩展查询的优化场景中,10 亿次查询的每日总能耗降至 0.89 吉瓦时,这一能耗规模大致相当于美国家庭每日电视使用总能耗的 0.4%[57]。因此,尽管测试时扩展会显著增加能耗,但其倍增效应可通过硬件与服务优化得到控制——且由于token成本是 AI 普及的核心驱动因素,长推理场景下的效率提升应成为重点关注与主动推进的方向。
从历史数据来看,数字基础设施能耗的预测往往因忽视“需求倍增过程中效率与系统级优化的快速提升”而高估实际需求[56]。
-
例如,1999 年有预测称,到 2010 年互联网将消耗美国电网 50%的电力,但实际数据中心能耗占比峰值仅约 2%[56]; -
2015 年另一项备受关注的预测称,到 2030 年数据中心年能耗将达 8000 太瓦时(占全球电力的 25%以上),但最新估算显示,届时数据中心年能耗仅为 600-800 太瓦时(约占全球电力的 2%)[56]。
我们认为,当前 AI 推理需求的激增虽看似前所未有,但仍符合这一历史规律:尽管绝对能耗会增长,但硬件、软件及大规模部署策略的效率提升,将能够抑制其长期能耗足迹的扩张。
五、结论
本文提出了一种自下而上的方法,用于估算 AI 推理的能耗。通过结合节点级功率参数、利用率因素、能源使用效率(PUE)分布,以及基于实际服务场景拟合的token吞吐量(TPS)数据,我们的估算结果与优化生产环境中的披露数据一致。该框架能够量化现有优化技术与token长度分布对整体能耗的影响。
本研究存在若干局限性:
-
首先,我们的模拟聚焦于高利用率的单节点推理,未能完全涵盖分布式系统中的节点间编排开销、启动动态过程、token吞吐量与功率利用率的相关性,以及网络延迟; -
其次,我们对传统查询与长推理查询的工作负载分布及token长度范围做了理想化假设,而实际企业与消费级部署中的情况可能存在差异; -
第三,我们对长上下文查询中预填充(prefill)成本的建模不够完善——在极端长输入场景下(如 10 万个token),预填充的能耗占比将显著提升; -
最后,我们假设极长生成过程中的token吞吐量保持固定,而实际系统中吞吐量往往会下降,这可能导致在这类场景下对能耗的估算偏低。
尽管存在上述局限性,我们的分析仍得出两个具有直接技术与政策启示的核心结论:
-
非生产环境下的查询能耗被高估:基于小规模或未优化部署的能耗估算或测量,会将推理能耗高估 4-20 倍。对于政策制定者与相关利益方而言,这意味着应避免基于狭隘基准得出危言耸听的结论;相反,能耗披露与估算应重点呈现能够反映工作负载多样性、服务模式、利用率及部署规模的能耗范围。能耗对比需采用系统层面的方法,结合具体产品场景进行,而非仅对孤立模型进行比较。
-
推理次数增加与推理时长延长会导致能耗上升,但效率提升可抑制这种上升趋势:AI 的快速普及、测试时扩展及智能体工作流(agentic workflows)会显著增加推理能耗,但其影响可通过优化加以控制。最大的效率提升潜力来自算法进步——尤其是小型/蒸馏语言模型(small/distilled LLMs)与推理优化架构——以及智能模型路由(可避免对大型模型的不必要使用)。硬件改进与服务优化也能做出重要贡献。综合这些手段,有望实现 8-20 倍的可实现能耗降低。为抑制 AI 推理规模扩张带来的能耗影响,及时落实这些效率提升措施至关重要。
参考文献


