

大家好!这篇文章兼顾了 RAG 的科普与 LlamaIndex 的实战。无论你处在哪个阶段,都能找到适合自己的阅读路径:
-
如果你是 RAG 或 AI 新手:
- 建议从第一部分:原理篇开始,建立核心概念;
- 然后跳至第二部分:实战篇,体验 30 行代码构建问答系统;
- 第三、四部分可先收藏,后续深入学习。
-
如果你熟悉 RAG,想深入 LlamaIndex:
- 快速浏览第一部分回顾概念;
- 重点阅读第二部分,掌握简洁高效的 API;
- 第三部分为精华内容,通过实验展示 chunk_size 和 top_k 等参数对结果的具体影响;
- 第四部分帮助理解内部机制,为二次开发打基础。
第一部分:原理篇 - AI 如何像人一样"读书"
1.1 一个真实的需求
假设你有一本 170 页的小说《长安的荔枝》,想快速了解: - 主角是谁? - 故事讲了什么? - 荔枝如何送达长安? 但没时间通读全书。人类的做法是:查目录 → 浏览相关章节 → 找关键信息 → 总结答案。AI 是否也能如此?答案是可以,这就是 RAG 技术的核心。1.2 从"搜索"到"理解"
传统搜索的局限
使用关键词搜索存在明显问题: - 搜索“主角”可能无结果(书中用“李善德”); - 搜索“李善德”出现 50 处,难以判断哪句说明其为主角。 问题在于:传统搜索仅支持精确匹配,无法理解语义。直接问 ChatGPT?
同样存在问题: - ChatGPT 未读过该书; - 可能编造答案; - 无法引用原文,不可追溯。1.3 理想的解决方案
理想的系统应具备以下能力: 1. “读”过这本书 —— 理解内容; 2. 找到相关段落 —— 快速定位; 3. 理解并回答 —— 自然语言输出; 4. 可以追溯 —— 明确答案来源。 这正是 RAG(检索增强生成)系统的使命。1.4 工作原理:三个关键步骤
步骤 1:建立"索引卡片"(Indexing)
类比读书做笔记: - 将文档切分为段落(Chunking); - 为每段生成“数字指纹”(Embedding); - 存入向量数据库。 此过程称为**向量化**。步骤 2:找到相关段落(Retrieval)
当提问“主角是谁?”时: 1. 将问题转为向量; 2. 对比所有段落向量,找出最相似的若干段; 3. 返回 top-k 相关段落。 此过程称为**语义检索**。步骤 3:生成答案(Generation)
将检索到的相关段落作为上下文输入给大模型,由其生成自然语言答案。 此过程称为**增强生成**。1.5 关键参数的作用
参数 1:段落大小(chunk_size)
- **小 chunk(~300 字)**:适合回答具体事件,如“李善德接到了什么任务?” - **大 chunk(~600 字)**:包含更多背景信息,适合分析心理变化或复杂情境。 效果对比: - 小卡片:精确定位,信息有限; - 大卡片:上下文完整,利于深度理解。参数 2:检索数量(top_k)
- **top_k=3**:返回 3 个最相关段落,回答简洁但信息有限; - **top_k=10**:获取更全面的信息,生成更丰富的人物画像。 效果对比: - top_k 小:响应快,信息少; - top_k 大:回答详尽,耗时增加。参数 3:重叠大小(overlap)
用于防止关键信息在分块边界丢失。 - **无重叠**:可能导致思维链断裂; - **有重叠(如 50 字)**:确保跨段落逻辑连贯,提升答案完整性。参数定义总结

1.6 现在,让我们引入术语

1.7 小结
核心思想: 1. 文档切块 → 生成向量; 2. 问题向量化 → 检索相似段落; 3. 结合上下文生成答案。 优势: - ✅ 基于真实文档,避免幻觉; - ✅ 支持语义理解,非关键词匹配; - ✅ 答案可追溯,来源清晰。 接下来,进入实战环节。第二部分:实战篇 - 用 LlamaIndex 实现问答系统
2.1 什么是 LlamaIndex?
LlamaIndex 是专为连接大语言模型与外部数据设计的数据框架,可自动化处理文档加载、文本切分、向量化、存储、检索和生成等流程。 形象地说,它是 AI 的“超级图书管理员”: - 接收书籍(外部数据); - 制作索引卡片(构建索引); - 快速响应查询(检索+生成)。2.2 预期效果
目标是用不到 50 行代码实现如下功能:# 加载《长安的荔枝》
loader = DocumentLoader("长安的荔枝.pdf")
# 构建索引
index = VectorStoreIndex.from_documents(documents)
# 开始提问
query_engine = index.as_query_engine()
# 问题 1
response = query_engine.query("主角是谁?")
# 答案:李善德。他是上林署的监事...
# 问题 2
response = query_engine.query("故事的主线是什么?")
# 答案:围绕李善德运送荔枝的任务展开...
# 问题 3
response = query_engine.query("荔枝最后是怎么送到长安的?")
# 答案:通过水路船运结合陆路运输...
2.3 最简代码清单
from llama_index.core import VectorStoreIndex, Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.readers.file import PyMuPDFReader
# 1. 配置 AI 服务
Settings.llm = OpenAI(model="gpt-3.5-turbo", api_key="your_api_key")
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small", api_key="your_api_key")
# 2. 加载 PDF
reader = PyMuPDFReader()
documents = reader.load(file_path="长安的荔枝.pdf")
# 3. 构建索引
index = VectorStoreIndex.from_documents(documents)
# 4. 创建查询引擎
query_engine = index.as_query_engine(similarity_top_k=3)
# 5. 提问
response = query_engine.query("主角是谁?")
print(response.response)
2.4 核心 API 详解
API 1: Settings - 全局配置
Settings.llm = OpenAI(...) # 生成答案
Settings.embed_model = OpenAIEmbedding(...) # 向量化
API 2: PyMuPDFReader - PDF 加载
reader = PyMuPDFReader()
documents = reader.load("长安的荔枝.pdf")
API 3: VectorStoreIndex - 构建索引
index = VectorStoreIndex.from_documents(documents)
API 4: as_query_engine() - 创建查询引擎
query_engine = index.as_query_engine(
similarity_top_k=3,
response_mode="compact"
)
API 5: query() - 提问
response = query_engine.query("主角是谁?")
2.5 完整示例:对话式问答
```python # 使用 chat_engine 支持多轮对话 chat_engine = index.as_chat_engine() response1 = chat_engine.chat("主角是谁?") print(f"AI: {response1.response}") response2 = chat_engine.chat("他的职位是什么?") print(f"AI: {response2.response}") # 能记住上下文 chat_engine.reset() # 重置对话 ``` 区别: - `query_engine`:每次独立提问; - `chat_engine`:支持记忆上下文的多轮对话。2.6 小结

第三部分:优化篇 - 参数调优的实战效果

3.1 实验设计思路
第一类:单参数影响实验
- 实验1:只改变 chunk_size,观察对复杂信息理解的影响; - 实验2:只改变 top_k,评估信息全面性; - 实验3:只改变 overlap,测试跨段落信息保护能力。第二类:组合参数优化实验
- 实验4:简单事实查询; - 实验5:复杂情节理解; - 实验6:宏观主题分析。 所有实验基于《长安的荔枝》全文,使用相同 Prompt 模板和真实输出结果。3.2 单参数影响实验
实验1:chunk_size 的影响
**问题**:李善德的心理变化是怎样的? | 配置 | 效果 | |------|------| | 256 | 仅概括四个阶段,缺乏细节(⭐⭐) | | 512 | 增加“谄媚”“悔悟”等描述(⭐⭐⭐) | | 1024 | 提及“妥协”“复杂内心世界”(⭐⭐⭐⭐) | | 2048 | 包含“宿命束缚”“内心挣扎”等深层分析(⭐⭐⭐⭐⭐) | **结论**: - chunk_size 越大,理解越深入; - 对渐进式心理变化问题,建议 ≥1024; - 注意平衡索引效率与存储开销。实验2:top_k 的影响
**问题**:小说中有哪些重要人物? | 配置 | 发现人物数 | |------|-----------| | top_k=2 | 2 人(李善德、林邑奴) | | top_k=5 | 6 人(含圣人、贵妃、杜甫等) | | top_k=10 | 9 人,结构化呈现 | **结论**: - top_k 决定信息覆盖面; - 列举类问题建议 ≥5; - 过大会增加 Token 消耗。实验3:chunk_overlap 的影响
**问题**:李善德的计划是如何形成的? | 配置 | 效果 | |------|------| | overlap=0 | 叙述跳跃,“然而”突兀出现(⭐⭐⭐) | | overlap=100 | “掇树之术”解释清晰,逻辑连贯(⭐⭐⭐⭐⭐) | | overlap=200 | 强调“不断改进”,进一步提升流畅度(⭐⭐⭐⭐⭐) | **结论**: - overlap 显著提升连续思考过程的理解; - 建议 ≥100,尤其适用于涉及流程的问题。3.3 组合参数优化实验
实验4:简单事实查询场景
**问题**:李善德的官职是什么? - 默认配置(512/20/3):回答“荔枝使”(临时任命); - 优化配置(1024/128/6):回答“监事”,并补充背景信息。 **结论**: - 简单查询可用默认配置; - 若需更高准确率,适度提升参数有效; - 权衡速度与精度。实验5:复杂情节理解场景
**问题**:李善德如何解决保鲜难题? - 默认配置:列出三步,组织较乱; - 优化配置(1024/128/6):逻辑清晰,步骤分明。 **结论**: - 复杂问题需更大 chunk 和更多 top_k; - 推荐标准配置:1024/128/6; - 此为最常见实用场景。实验6:宏观主题理解场景
**问题**:小说表达了关于权力、责任和个人选择的哪些思考? - 默认配置:泛泛而谈,缺少深度(⭐⭐); - 优化配置:分维度详细分析(⭐⭐⭐⭐); - 深度配置(2048/256/10):多角度探讨,论述深入(⭐⭐⭐⭐⭐)。 **结论**: - 主题理解需要最强配置; - 成本虽高,但值得用于关键分析; - 建议使用 2048/256/10。3.4 参数配置建议

3.5 参数速查表

3.6 小结
关键发现: 1. **chunk_size 影响最大**:从 256 到 2048,理解深度显著提升; 2. **top_k 决定全面性**:从 2 到 10,信息覆盖提升 4.5 倍; 3. **overlap 提供保险**:防止关键信息在分块时丢失; 4. **场景决定配置**:不同问题需差异化调参。 优化策略: 1. 先用默认配置测试; 2. 按问题类型选择合适参数; 3. 若效果不佳,逐步增大参数; 4. 注意成本与性能平衡。 所有结论均基于真实实验,为生产环境提供可靠指导。第四部分:架构篇 - LlamaIndex 的内部机制
4.1 整体架构图

4.2 核心组件详解
组件 1:文档加载器(Document Loader)
作用:将各类文件转换为统一 Document 对象。 - 支持格式:PDF、Word、Markdown、网页、数据库等。 - 示例:PyMuPDFReader 加载 PDF 每页为一个 Document。组件 2:文本分块器(Node Parser)
作用:将长文本切分为适合检索的小块。 - 默认使用 SentenceSplitter; - 支持设置 chunk_size 与 chunk_overlap; - 维护块间关系,保证上下文连续。组件 3:向量化模型(Embedding Model)
作用:将文本转化为向量。 - 使用 OpenAIEmbedding 等模型; - 向量用于语义相似度计算; - 查询时也需向量化以进行匹配。组件 4:向量存储(Vector Store)
作用:存储和检索向量。 - 默认内存存储; - 支持持久化至磁盘; - 检索流程:计算相似度 → 排序 → 返回 top-k。组件 5:检索器(Retriever)
作用:根据查询找到最相关 Nodes。 - 默认使用 VectorIndexRetriever; - 流程:向量化 → 向量库查询 → 返回带分数的结果。组件 6:响应合成器(Response Synthesizer)
作用:将检索结果与问题合成最终答案。 - compact 模式:合并上下文,一次调用 LLM; - refine 模式:逐段精炼; - tree_summarize:适用于大量段落。组件 7:LLM(Large Language Model)
作用:理解问题并生成答案。 - 使用 GPT 等模型完成最终生成; - 输入为构造好的 Prompt,输出为自然语言回答。4.3 数据流动全景
一次完整查询流程: 1. 用户输入问题; 2. 向量化问题; 3. 检索最相似 Nodes; 4. 合成 Prompt(含上下文); 5. 调用 LLM 生成答案; 6. 返回结果及来源。4.4 参数在架构中的位置
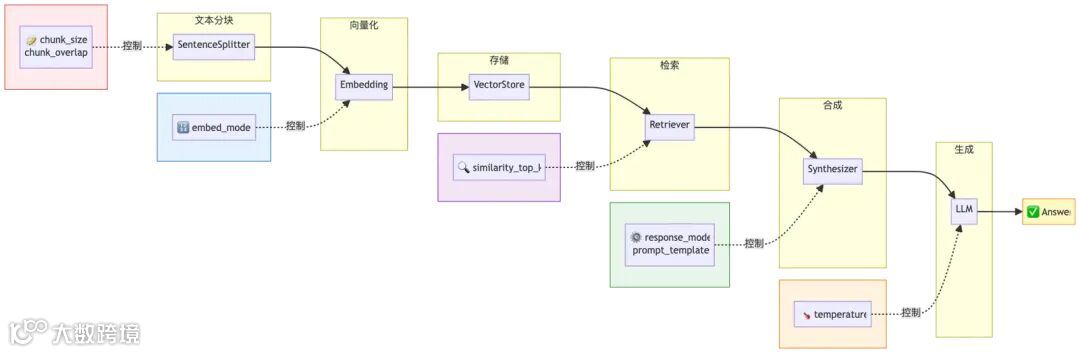

4.5 小结
架构要点: - 五层流程:数据处理 → 索引 → 检索 → 合成 → 生成; - 七个核心组件协同工作; - 每个参数在特定组件中生效。 设计优势: - ✅ 模块化:职责清晰; - ✅ 可扩展:任意组件可替换; - ✅ 灵活性:支持丰富配置。第五部分:Agent 化 - 让 RAG 系统能"动手"
5.1 RAG 的边界
传统 RAG 系统只能基于已有文档回答问题,缺乏执行能力,例如: - 无法搜索网络获取新资料; - 无法保存文件或操作外部工具。 本质:有“大脑”无“手脚”。5.2 AgentBay:为 Agent 提供工具
AgentBay 是云端 Agent 工具平台,提供浏览器、Office、Python 执行环境等。 核心思路: - LlamaIndex:决策“做什么”; - AgentBay:执行“怎么做”。5.3 集成思路
核心逻辑: 1. 优先查询本地知识库; 2. 若信息不足,触发网络搜索; 3. 使用 AgentBay 创建浏览器会话; 4. 通过 Playwright 自动化操作页面; 5. 提取结果并综合生成最终答案。 关键 API: - `agent_bay.create()`:创建会话; - `session.browser.initialize_async()`:初始化浏览器; - `p.chromium.connect_over_cdp()`:连接 Playwright; - `agent_bay.delete()`:清理资源。5.4 何时使用?
✅ 适用场景: - 需结合本地文档与网络信息; - 需自动化操作(搜索、下载、保存); - 需集成外部工具(浏览器、Office)。 ❌ 不适用场景: - 纯静态文档问答; - 对响应速度要求极高(<1秒); - 单一数据源简单查询。总结
核心要点回顾
**第一部分:原理** - RAG = 检索 + 生成; - 三步流程:切分 → 向量化 → 检索 → 生成; - 核心参数:chunk_size、top_k、overlap。 **第二部分:实战** - 核心代码 < 30 行; - 关键 API:Settings、Reader、Index、QueryEngine、query(); - 支持单轮与多轮对话。 **第三部分:优化** - 实测验证各参数影响; - 提出针对性调优策略; - 不同场景推荐配置。 **第四部分:架构** - 五层架构设计; - 七大核心组件; - 参数在架构中的作用路径清晰。 **第五部分:Agent 化** - RAG 的局限性; - AgentBay 工具平台介绍; - LlamaIndex + AgentBay 集成方案; - 明确适用场景。最佳实践
1. **从简单开始**:先用默认配置,再逐步优化; 2. **针对性调整**:按问题类型选择参数; 3. **实测验证**:用实际问题测试效果; 4. **持久化索引**:避免重复构建,提升效率。进阶方向
- 多模态:处理图像、表格; - 混合检索:结合关键词与语义; - Agent:让 AI 自主决策与执行; - Fine-tuning:领域专用模型优化。附录
完整代码示例
#!/usr/bin/env python3
"""LlamaIndex 完整示例:《长安的荔枝》问答系统"""
import os
from llama_index.core import VectorStoreIndex, Settings, StorageContext, load_index_from_storage
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.readers.file import PyMuPDFReader
from llama_index.core.node_parser import SentenceSplitter
# 1. 配置
Settings.llm = OpenAI(
model="gpt-3.5-turbo",
temperature=0.1,
api_key=os.getenv("OPENAI_API_KEY")
)
Settings.embed_model = OpenAIEmbedding(
model="text-embedding-3-small",
api_key=os.getenv("OPENAI_API_KEY")
)
Settings.text_splitter = SentenceSplitter(
chunk_size=1024,
chunk_overlap=128
)
# 2. 加载文档
reader = PyMuPDFReader()
documents = reader.load("长安的荔枝.pdf")
print(f"加载了 {len(documents)} 页")
# 3. 构建或加载索引
persist_dir = "./storage"
if os.path.exists(persist_dir):
storage_context = StorageContext.from_defaults(persist_dir=persist_dir)
index = load_index_from_storage(storage_context)
print("加载已有索引")
else:
index = VectorStoreIndex.from_documents(documents, show_progress=True)
index.storage_context.persist(persist_dir=persist_dir)
print("构建并保存新索引")
# 4. 创建查询引擎
query_engine = index.as_query_engine(similarity_top_k=5)
# 5. 交互式问答
print("\n开始问答(输入 'quit' 退出):")
while True:
question = input("\n你的问题:").strip()
if question.lower() in ['quit', 'exit', '退出']:
break
if not question:
continue
response = query_engine.query(question)
print(f"\n答案:{response.response}")
参数速查表
