科研分享 | 基于主动隐私聚类和知识融合的可迁移联邦学习风电功率预测方法

针对上述挑战,本文提出了一种名为D-M APCFed的新型联邦学习方法。核心创新包括:
-
多空间尺度的预测框架:该方法可应用于单个风机或整个风电场的预测,具有多空间尺度的适应性。 -
主动隐私聚类算法(APC):通过在数据隐私保护边界内执行风场/风机客户端的聚类,有效缓解了不同风电场间的数据异质性对预测模型性能的负面影响。 -
D-M FedAvg知识融合策略:APC方法实现了按客户端的数据分布进行分组。经典的联邦学习模型参数聚合算法FedAvg对所有客户端建立单一模型,不再适用,本文提出了 DM-FedAvg知识融合策略,实现聚类间和聚类内的客户端知识融合。
D-M APCFed方法的流程为:
Step 1: 执行APC算法
在联邦学习开始之前,服务器将公共数据分发给所有客户端。每个客户端在本地计算私有数据与公共数据的分布距离(EMD),并将结果上传到服务器。服务器对接收到的所有EMD进行聚类分析,并将相应的聚类标签分发给各个客户端。
Step 2: 初始化全局模型
服务器根据聚类标签初始化k个全局模型,每个模型对应一个类别,从而为不同的数据分布提供针对性的建模能力。
Step 3: 本地模型训练和参数上传
服务器从客户端中随机抽样并分配相应的全局模型。客户端利用自身的私有数据在本地训练模型,并在训练期间定期验证模型的性能。最终,客户端将本地验证集上表现最优的模型参数上传至服务器。
Step 4: 使用D-M FedAvg进行参数聚合与更新
服务器根据客户端的聚类类别对接收到的模型参数进行分组,并在每个聚类内执行完全参数聚合,从而得到k个候选更新的全局模型。随后,服务器对这k个模型的部分参数进行进一步聚合,最终更新服务器上的全局模型。
Step 5: 迭代
服务器在测试集上验证更新后的全局模型的性能。如果模型精度达到预期要求,则联邦学习过程结束;否则,返回步骤3和步骤4继续迭代。
通过以上五个步骤,D-M APCFed方法在实现数据隐私保护的同时,有效解决了数据异质性问题,并显著提升了风电预测模型的多空间尺度适应性与预测精度。

图1 方法概述图

本文使用风机级和风场级两个不同空间尺度的真实风力发电数据进行实验。风场数据集是龙源电力公司公开的20个不同风场近1年的发电数据和气象数据。风机数据集是中国宁夏省某风电场25台风机约2年的SCADA系统数据和气象数据。本文设计了常规实验测试D-M APCFed在参与FL的风机/风场的测试集上的预测精度,设计了迁移实验以测试D-M APCFed训练好的模型在未参与FL的风机/风场的测试集上的预测精度,迁移实验中使用不同大小的数据量来微调训练好的模型。

在风机和风场两个空间尺度上,所提出的方法都优于对比的方法(集中式深度学习方法和普通联邦学习方法),表现出卓越的跨空间尺度适应性能,在隐私边界内实现了精准的风功率预测。

在小样本和零样本场景下,D-M APCFed方法也能通过少量数据的fine-tune实现接近常规实验精度的风功率预测,即使在数据稀缺甚至完全无数据的新建风场中,该方法也能够凭借预训练获得的知识实现可靠的预测。


主动隐私聚类(APC)方法通过对数据分布相似的客户端进行聚类,有效减轻了数据异质性对模型的负面影响。然而,这种方法可能导致“聚类孤岛”的风险,即聚类之间无法共享有价值的知识。D-M APCFed通过D-M FedAvg方法实现了不仅限于聚类内的知识融合,还在聚类间选择性地共享知识,从而平衡了隐私保护与预测精度。该方法捕捉到了聚类内的局部模式和跨聚类的共享模式。在常规实验中,该方法在20个风机上的平均预测准确率为81.69%,在12个风电场上的准确率达到87.11%,表明D-M APCFed有效克服了数据异质性限制,实现了隐私保护和高精度预测的双重目标。
D-M APCFed在处理数据稀缺场景时表现出卓越的迁移能力,这在实际中尤为重要,例如新建风电场可能缺乏历史数据的情况。通过微调仅16%的新风场数据,该模型即可实现与全量训练模型相当的预测精度,展现出强大的小样本学习能力。即便在零样本场景下(未使用新客户端的额外数据),D-M APCFed依然能够保持高预测准确率。迁移实验表明,少样本的预测准确率接近常规训练结果,验证了该方法在数据可用性不均环境中的可靠性与适应性。
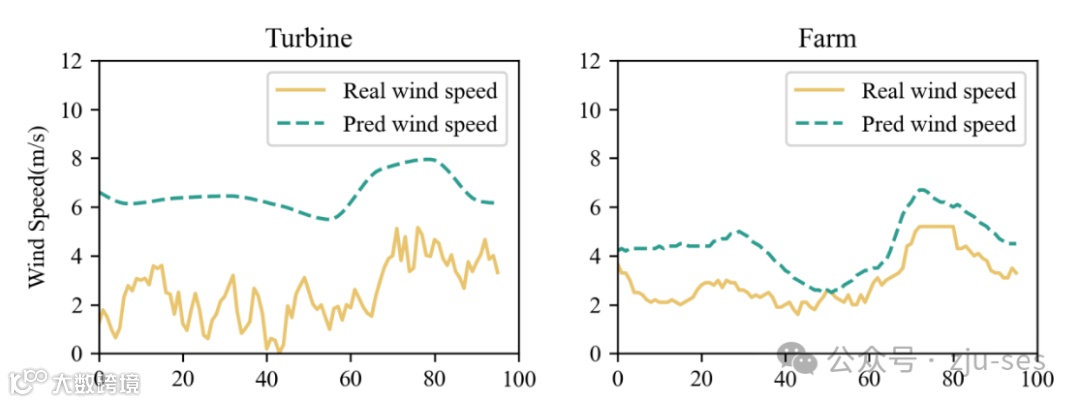
模型在风场尺度的预测性能显著优于风机尺度,主要原因包括以下两点:
-
风场数据集通常包含更丰富的气象变量,为风电建模提供了更全面的上下文信息。
-
风场尺度的风速预测更接近实际值,而风机尺度的风速数据受空间尺度更小的影响,波动更大且准确率更低。