

在Meta分析中,固定效应模型和随机效应模型是两种最常用的统计方法,它们有着不同的假设和适用场景。今天,我们就来通俗地讲解这两种模型的区别和应用。
什么是固定效应模型?
固定效应模型的核心假设是:所有纳入的研究都在估计同一个“真实”效应量。换句话说,它认为各个研究之间的差异仅仅是由于抽样误差引起的,而所有研究实际上都在测量同一个底层效应。
打个比方,固定效应模型就像是在假设:我们让同一个研究团队在不同的时间、使用不同的样本重复进行同一项研究,虽然每次得到的结果会略有不同(因为抽样误差),但这些研究本质上都是在测量同一个效应。
固定效应模型的应用前提是假定全部研究结果的方向与效应大小基本相同,即各独立研究的结果趋于一致,异质性检验差异无显著性。因此,当各研究间差异较小或无差异时,固定效应模型是较为合适的选择。
什么是随机效应模型?
与固定效应模型不同,随机效应模型认为纳入的研究不仅在估计一个共同的效应,而且每个研究还有其自身的独特效应。它假设真实效应量在不同研究之间是存在变异的,这种变异可能是由于研究间的差异(如人群、干预措施、研究设计等)造成的。
继续用比喻来说,随机效应模型就像是在承认:虽然这些研究都在探讨同一个问题,但由于研究环境、人群特征、实施方式等不同,每个研究测量的“真实”效应可能本身就存在差异。
随机效应模型是经典的线性模型的一种推广,它把原来固定效应模型的回归系数看作是随机变量,一般假设这些随机变量来自正态分布。这种模型通过变量之间的相关性来解释数据中的变异性。
两种模型的主要区别
1️⃣ 基本假设不同
固定效应模型假设所有研究共享一个共同的真实效应,研究间的差异仅由抽样误差导致。而随机效应模型则认为真实效应在不同研究间存在变异,研究间的差异既包括抽样误差,也包括真实效应的差异。
2️⃣ 对效应的看法不同
固定效应认为,效应量是固定的,是一个确定值。随机效应则认为,效应是随机变量的实现,与某些变量无关且满足特定的参数分布。
3️⃣ 适用场景不同
固定效应模型适用于各独立研究间无差异或差异较小的情况,即研究间同质性较高时。而随机效应模型则适用于研究间存在异质性的情况,即当研究间的差异超出了抽样误差所能解释的范围时。
4️⃣ 结果解释不同
使用固定效应模型得到的结果可以解释为“对所有纳入研究的平均效应的估计”,而随机效应模型的结果则可以解释为“效应量分布的平均值的估计”。
如何选择合适的模型?
在实际应用中,选择固定效应模型还是随机效应模型主要取决于以下几点:
异质性检验:首先进行异质性检验(如Q检验、I²统计量)。如果研究间没有显著异质性(I²值较低),可以考虑使用固定效应模型;如果存在显著异质性(I²值较高),则应选择随机效应模型。
研究背景:考虑纳入研究的设计、人群、干预措施等是否相似。如果研究在各方面都非常相似,固定效应模型可能更合适;如果研究间存在明显差异,随机效应模型更为恰当。
研究目的:如果目的是推断特定纳入研究的平均效应,固定效应模型可能更合适;如果目的是推断更广泛人群的效应,随机效应模型更为适用。
一张表格,快速总结
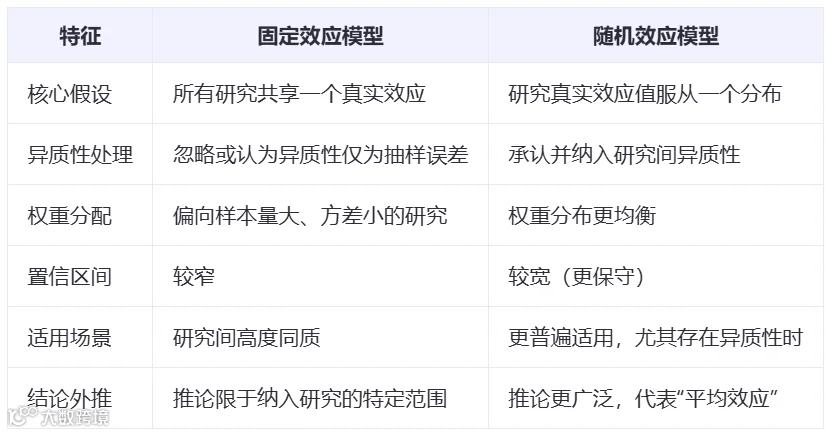
对于效应模型选择的建议
模型选择不能拯救糟糕的研究:如果纳入的研究本身质量很差或差异巨大(临床异质性高),无论用什么模型,结果都可能不可靠。此时应首先考虑是否适合做Meta分析。
异质性是要探索的宝藏:不要仅仅满足于选择随机效应模型。显著的异质性提示我们可能需要通过亚组分析、Meta回归等方法去寻找异质性的来源,这往往是得出更深刻科学结论的关键。
如果你想学习这种通过Meta分析发表SCI的方法,难于找不到一个合适的选题、苦于研究过程中遇到的问题太多无法持续推进,那么可以了解一下统计之光Meta分析一对一教学指导。

本号专注分享Meta分析科研干货与最新研究动态,除了上述内容外,对Meta分析感兴趣的同学,也可点击下方链接进行阅读或者留言你感兴趣的内容!
推荐阅读: