
主题建模技术综述:LSA、pLSA、LDA与lda2vec
本文系统梳理四种主流主题建模方法,涵盖其原理、差异及实现方式,助你深入理解文档主题的隐变量提取机制[k]
作者:Joyce Xu
机器之心编译
参与:乾树、王淑婷
主题建模是自然语言处理中从文档集合中识别和提取潜在主题的技术。本文重点介绍四种主流方法:潜在语义分析(LSA)、概率潜在语义分析(pLSA)、潜在狄利克雷分布(LDA),以及基于深度学习的lda2vec[k]
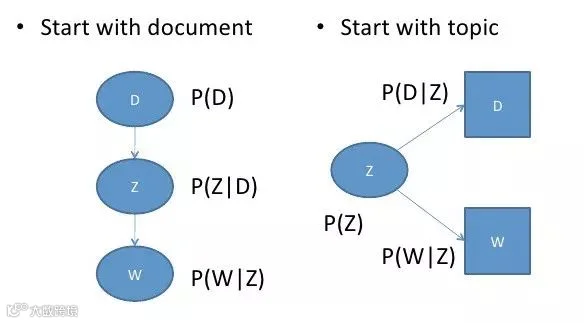
在文档层级,理解文本含义的关键之一是分析其主题构成。主题建模正是通过学习和识别语料库中的潜在主题结构,揭示文本背后的语义组织逻辑[k]
所有主题模型均基于两个基本假设:
1. 每篇文档由多个主题混合而成;
2. 每个主题由一组相关词汇构成[k]
主题建模的核心目标是发现这些控制文档语义的“潜在变量”——即主题。接下来将依次解析LSA、pLSA、LDA和lda2vec的技术原理及其演进关系[k]
LSA:潜在语义分析
LSA通过矩阵分解揭示文档与词汇之间的潜在语义结构。其流程为:
1. 构建文档-术语矩阵A(m×n,m为文档数,n为词汇数);
2. 使用tf-idf加权替代原始词频,提升关键词权重;
3. 应用截断奇异值分解(SVD)进行降维,公式为A ≈ U×S×VT[k]
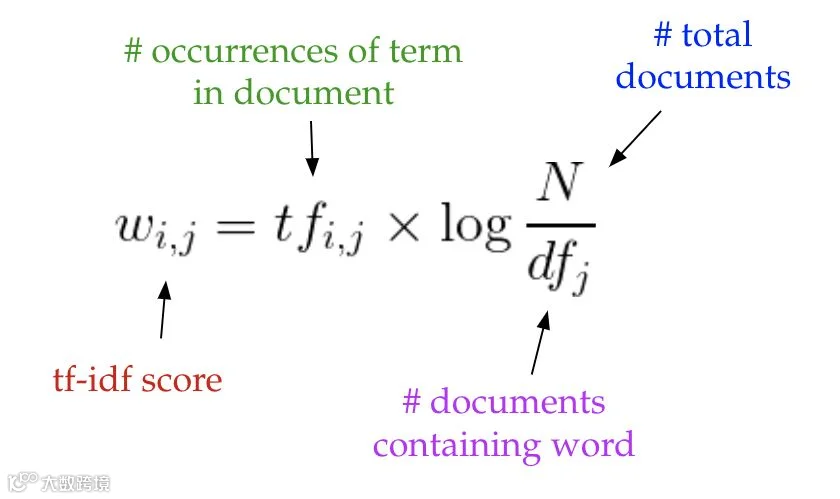
其中U为文档-主题矩阵,V为术语-主题矩阵,S为奇异值对角矩阵。保留前t个最大奇异值对应维度,实现从高维稀疏空间到低维语义空间的映射[k]
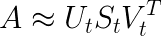

降维后,可通过余弦相似度计算文档间、词汇间及文档与查询间的语义相关性,广泛应用于信息检索场景[k]
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import TruncatedSVD
from sklearn.pipeline import Pipeline
documents = ["doc1.txt", "doc2.txt", "doc3.txt"]
# raw documents to tf-idf matrix:
vectorizer = TfidfVectorizer(stop_words='english',
use_idf=True,
smooth_idf=True)
# SVD to reduce dimensionality:
svd_model = TruncatedSVD(n_components=100,
algorithm='randomized',
n_iter=10)
# pipeline of tf-idf + SVD, fit to and applied to documents:
svd_transformer = Pipeline([('tfidf', vectorizer),
('svd', svd_model)])
svd_matrix = svd_transformer.fit_transform(documents)
# svd_matrix can later be used to compare documents, compare words, or compare queries with documentsLSA的优势在于计算高效,但存在三大局限:
• 主题成分缺乏可解释性
• 需大量文档和词汇支撑效果
• 表征效率较低[k]
pLSA:概率潜在语义分析
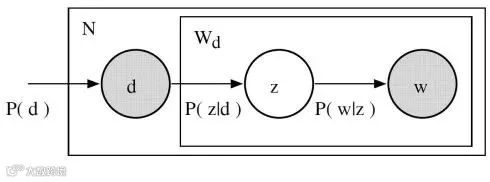
pLSA引入概率生成模型改进LSA,其核心思想是建立文档与词汇的联合概率P(d,w)。该模型基于以下条件概率:
• P(z|d):文档d中生成主题z的概率
• P(w|z):主题z中生成词汇w的概率[k]
联合概率表达式为:
P(d,w) = P(d) ∑z P(z|d)P(w|z)[k]
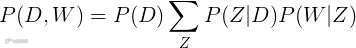
模型参数通过期望最大化(EM)算法训练,能够更灵活地拟合数据。值得注意的是,pLSA在数学形式上与LSA存在对应关系:
• P(Z) ↔ 奇异值对角矩阵
• P(D|Z) ↔ 文档-主题矩阵U
• P(W|Z) ↔ 术语-主题矩阵V[k]
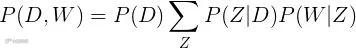
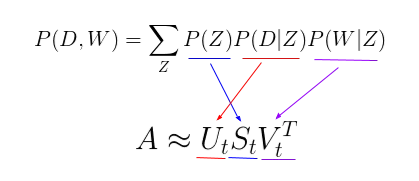
尽管pLSA提升了建模灵活性,但仍存在明显缺陷:
• 无法为新文档分配概率
• 参数数量随文档线性增长,易过拟合[k]
LDA:潜在狄利克雷分布
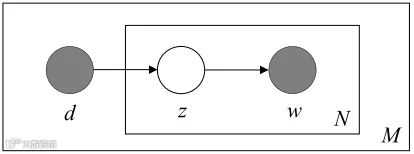
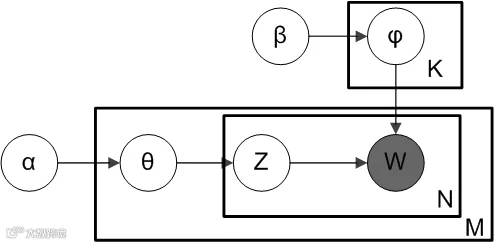
LDA是pLSA的贝叶斯扩展版本,通过引入狄利克雷先验解决泛化问题。它假设文档的主题分布θ和主题的词汇分布φ均服从狄利克雷分布:
• θ ~ Dir(α)
• φ ~ Dir(β)[k]
生成过程如下:
1. 对每篇文档,从Dir(α)抽样得到主题混合分布θ;
2. 对每个词,从θ中抽样确定主题z;
3. 从φz ~ Dir(β)抽样得到词汇分布,并生成具体词汇w[k]

LDA的优势在于能够泛化至新文档:即使未见过某文档,也可从狄利克雷先验中抽样生成其主题分布,从而有效避免过拟合问题[k]
from gensim.corpora.Dictionary import load_from_text, doc2bow
from gensim.corpora import MmCorpus
from gensim.models.ldamodel import LdaModel
document = "This is some document..."
# load id->word mapping (the dictionary)
id2word = load_from_text('wiki_en_wordids.txt')
# load corpus iterator
mm = MmCorpus('wiki_en_tfidf.mm')
# extract 100 LDA topics, updating once every 10,000
lda = LdaModel(corpus=mm, id2word=id2word, num_topics=100, update_every=1, chunksize=10000, passes=1)
# use LDA model: transform new doc to bag-of-words, then apply lda
doc_bow = doc2bow(document.split())
doc_lda = lda[doc_bow]
# doc_lda is vector of length num_topics representing weighted presence of each topic in the docLDA是目前最主流且效果优异的主题建模方法,广泛应用于文本挖掘、信息检索和推荐系统等领域[k]
深度学习中的主题模型:lda2vec原理详解
结合LDA与word2vec,实现单词、文档与主题的联合表征学习
通过LDA(潜在狄利克雷分配),可从文本语料中提取人类可解释的主题,每个主题由最具代表性的词汇构成[k]。例如,主题2可能包含“石油、天然气、钻井、管道”等关键词[k]。对于新文档,模型能输出其主题分布向量(如70%主题2),该表示在下游任务中具有广泛应用价值[k]。
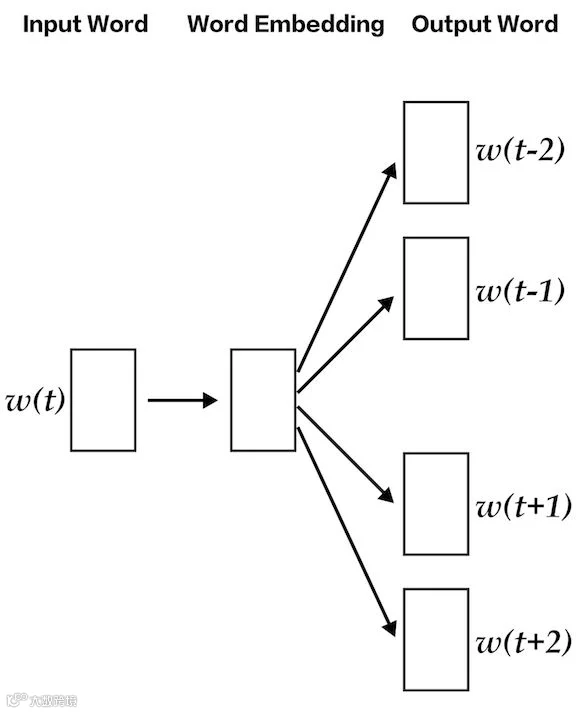
lda2vec是word2vec与LDA的结合体,旨在同时学习单词、文档和主题的向量表示[k]。它基于word2vec的skip-gram架构,通过输入词预测上下文词来学习词嵌入[k]。
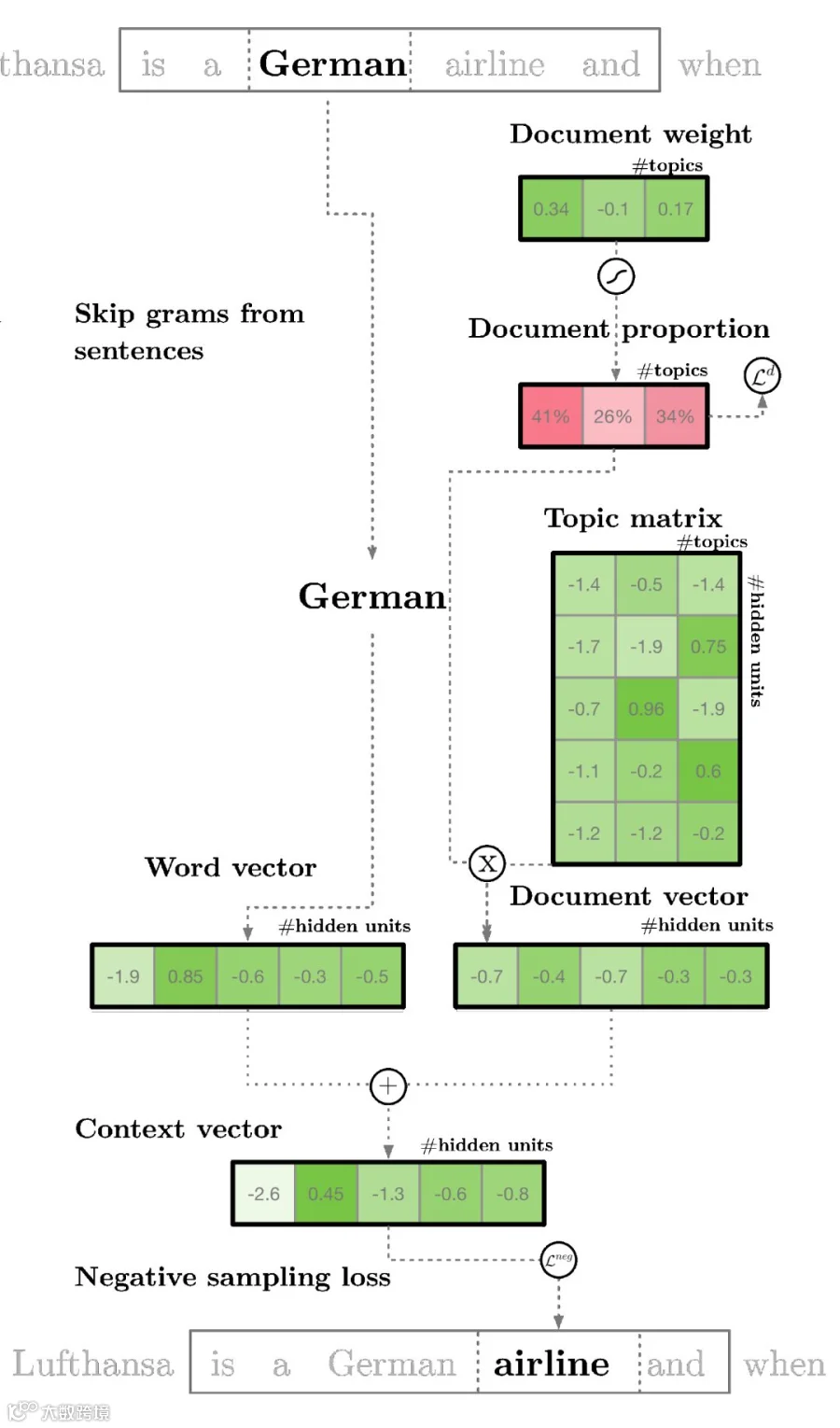
与传统word2vec不同,lda2vec使用“上下文向量”进行预测,该向量由单词向量和文档向量相加而成[k]。其中,单词向量来自skip-gram模型;文档向量则由两部分构成:文档权重向量(表示各主题在文档中的权重)和主题矩阵(存储每个主题的向量嵌入)[k]。
文档向量与单词向量共同生成每个词的上下文向量,使模型能同时学习词嵌入、主题表示和文档表示[k]。这一机制提升了文本多层级语义建模能力[k]。
相较于传统神经网络,主题模型具备良好的可解释性,便于诊断、调整与评估[k]。lda2vec通过融合主题建模与深度学习,为文本语义理解提供了兼具表现力与透明度的解决方案[k]。