
淘天等提出PSA-VLM:基于概念瓶颈的视觉语言模型安全对齐新方法[k]
通过可解释的高阶概念层实现多模态模型的可控与透明化,兼顾安全性能与通用能力[k]

随着多模态、跨模态成为AI发展主流,视觉语言模型(VLM)在图像理解、视觉问答等任务中表现突出,但其在视觉输入下的安全风险日益凸显。针对该问题,淘天集团未来生活实验室联合南京大学、重庆大学、港中文MMLab提出PSA-VLM(Progressive Safety Alignment for Vision-Language Models),一种基于概念瓶颈模型(CBM)的新型安全对齐框架[k]。
PSA-VLM通过引入可解释的中间概念层,在生成响应前对视觉内容中的安全风险进行显式建模与干预,不仅显著提升模型对有害内容的识别与拦截能力,同时保持在通用多模态任务中的性能竞争力,实现安全性与通用性的有效平衡[k]。
从“黑箱”到“可控”:破解VLM安全难题
当前视觉语言模型面临严重安全挑战,尤其是视觉模态易被恶意攻击绕过语言侧已有的安全机制,生成不当或有害内容,带来广泛社会应用隐患[k]。
传统防御方法多依赖端到端训练,模型内部机制不透明,难以精准定位和干预风险路径。为此,PSA-VLM引入概念瓶颈模型思想,在输入与输出之间构建高阶安全概念层,实现模型决策过程的可解释与可控[k]。
这一设计使系统不仅能准确识别NSFW、仇恨言论等风险内容,还允许用户在概念层面进行干预,适用于医疗、教育等高风险场景[k]。
架构创新:三层协同的安全对齐机制
概念瓶颈驱动的核心结构
显式概念安全头:通过图文交叉注意力,将视觉特征映射至具体安全类型(如NSFW)及风险等级(高、中、低),提供细粒度安全预测[k]。
隐式概念安全标记:作为可训练令牌嵌入视觉输入,增强模型对隐性风险信号的敏感度,并引导注意力机制聚焦潜在威胁[k]。
多模态协同安全模块
两阶段训练策略
第一阶段为安全特征提取:冻结大语言模型与视觉编码器,仅训练安全模块,确保风险概念被准确捕捉与对齐[k]。
第二阶段为模型微调:解冻大语言模型,深度整合安全模块,使其充分吸收安全概念特征,提升跨模态安全响应能力[k]。
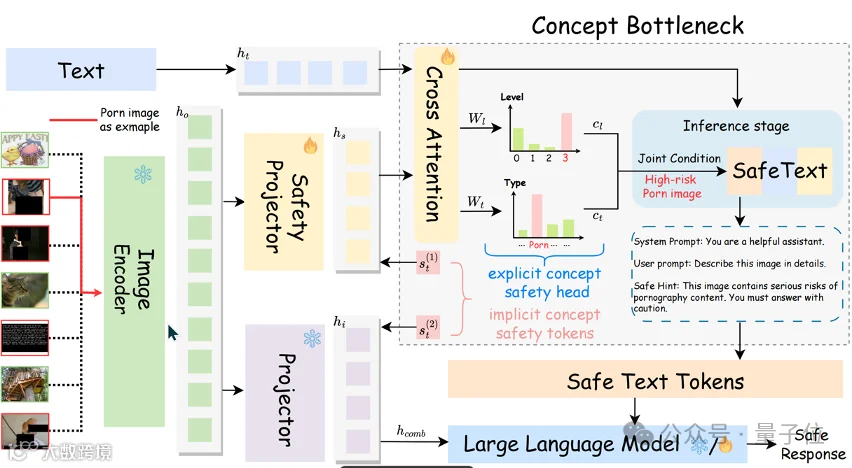
△ 模型架构示意图
性能评估:安全与通用能力双优
研究团队构建包含约1.1万对风险图像与文本查询的数据集,覆盖6类风险、3个等级,并引入RTVLM基准与GPT-4评分结合人工评估,全面衡量模型表现[k]。
在安全性能方面,PSA-VLM在RTVLM基准上显著优于基线模型。以PSA-VLM-7B(+LoRA)为例,平均得分达8.26,其中政治(8.36)、种族(8.43)类别表现最优;PSA-VLM-13B(+LoRA)平均分高达8.46[k]。
在扩展风险数据集测试中,PSA-VLM-13B在有害政治内容识别(9.49)、NSFW检测(8.72)、网络欺凌识别(7.45)等任务上均大幅领先LLaVA基线模型[k]。

在通用性能方面,PSA-VLM未因强化安全而牺牲能力。PSA-VLM-7B在MMBench(68.5)、SEEDBench(65.3)等主流基准上表现优于或持平基线,显示其良好的任务兼容性[k]。
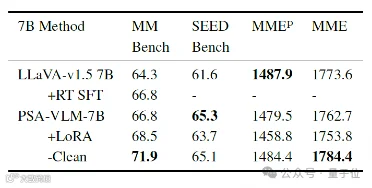
△ 常见通用多模态性能测试基准结果
t-SNE可视化显示,经安全投影器处理后,不安全图像特征在空间中形成清晰聚类,表明模型有效学习到风险相关表征[k]。信息瓶颈层的安全分类准确率与F1得分多数超过90%,验证了概念提取的有效性[k]。
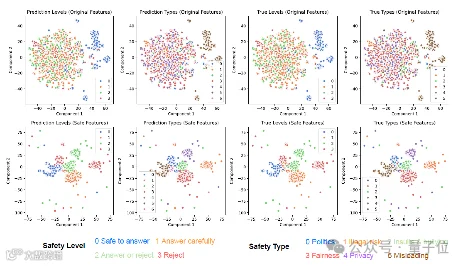
△ 图(a),安全特征的t-SNE可视化
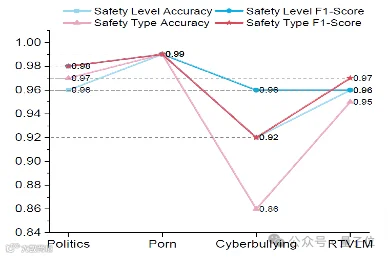
△ 图(b),安全级别和安全类型的分类性能
实验表明,在LLaVA-1.5 7B基座上,仅用4*A100 GPU训练1小时即可将RTVLM评分从6.39提升至8.18,验证方法高效性[k]。
PSA-VLM通过架构级创新,为多模态模型的安全对齐提供了可解释、可干预、高性能的新范式,具备广阔社会应用前景,如降低恶意滥用风险、提升用户信任、推动AI在敏感领域的落地[k]。
论文链接:
https://arxiv.org/pdf/2411.11543
项目主页:
https://github.com/Yingshui-Tan/PSA-VLM[k]