
大语言模型赋能软件编程:现状与挑战
从代码生成历史到AI编程的未来路径

代码生成的历史可追溯至20世纪50年代的FORTRAN等高级编程语言,其本质是用更高抽象表达生成机器指令的过程[k]。随后逻辑编程语言Prolog通过规则推理实现程序合成,UML类图和状态图则通过模板机制转化为代码,发展出模型驱动开发(MDD),并催生低代码(Low-code)和无代码(No-code)理念[k]。然而,这些方法在表达动态特性与定制能力方面存在局限[k]。

2015年起,神经网络开始应用于代码生成,早期研究使用RNN逐字符生成代码[k]。CugLM和基于BERT训练的CodeBERT首次将预训练语言模型用于代码理解与生成[k]。随着GraphCodeBERT探索代码特有结构,Codex凭借超10B参数规模在广泛代码语料上取得突破,确立因果语言模型(CLM)在代码任务中的主导地位[k]。此后ChatGPT、Code Llama、DeepSeek Coder、CodeQwen、StarCoder等模型相继涌现[k]。自2023年初GPT-4扩展放缓,Agent技术推动“AI程序员”“AI软件公司”等方案兴起,进一步提升AI编程能力[k]。

作者卢威在GOSIM 2024欧洲站AI & Agents论坛发表主题演讲《大语言模型赋能软件编程:现状与倡议》,系统分析了LLM在软件工程中的应用方式、技术原理、关键挑战及开源倡议[k]。本文基于演讲内容扩展,涵盖因时间限制未能详述的技术细节[k]。
 代码生成的演进
代码生成的演进
大语言模型的核心优势在于其内置的广泛知识、隐含共识、多类型推理能力以及反向交互提问的能力,成为提升编程抽象层级的新机遇[k]。调查显示,编写代码仍是开发者最耗时的任务,AI辅助中最常用的功能也是编码,但开发者最不愿完全交由AI处理的同样是编码任务[k]。
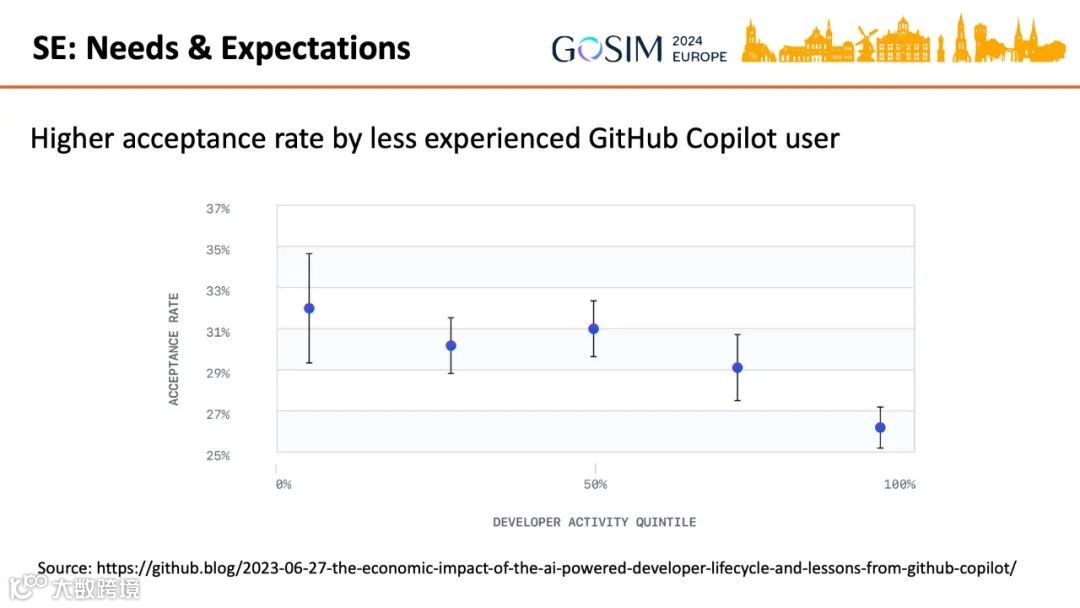
研究发现,初级开发者对AI生成代码的采纳率高于资深开发者[k]。原因可能包括:初级任务更简单、AI生成质量更高;或初级用户使用技巧更优;亦或是资深开发者更能识别AI生成缺陷而选择不采纳[k]。这一现象提示应根据任务复杂度进行分层,使模型能全自动完成低难度任务[k]。
当前主流AI辅助工具在代码补全方面已展现显著效果[k]。整体技术架构依赖数据驱动,模型能力主要源于GitHub开源代码、企业专有代码与文档[k]。随着真实数据趋近枯竭,合成数据正成为关键补充[k]。

简单任务如代码补全多通过提示词工程(Prompt Engineering)实现[k]。复杂问答则依赖检索增强生成(RAG),通过引入上下文与知识库信息控制生成结果[k]。对于高复杂度任务,需利用LLM自身能力进行任务拆解、多次调用、信息记录与外部工具整合,逐步生成完整解决方案[k]。
 数据挑战与创新
数据挑战与创新
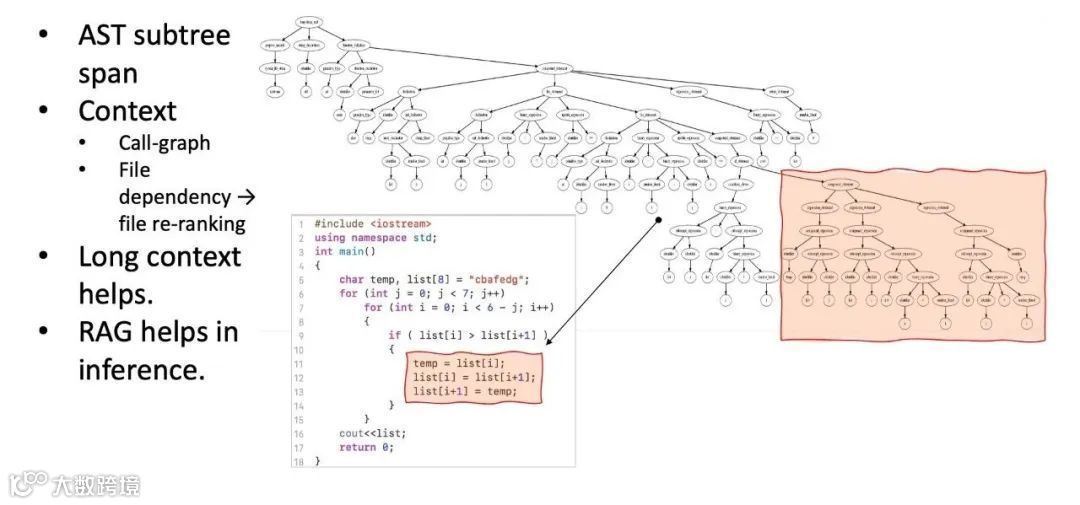
代码具有强结构化特征,语义依赖可能跨越物理文件边界[k]。因此常将代码解析为抽象语法树(AST),以节点或子树为单位处理,并依据语义依赖调整数据顺序[k]。

部分开源模型通过合成指令数据进行监督微调(SFT),实现接近甚至超越GPT-4的编码能力[k]。StarCoder2-Instruct项目表明,15B参数的小模型亦可生成高质量训练数据,提升自身表现,突破对大模型生成数据的依赖[k]。
合成数据的关键要素包括:高质量种子样本、人类知识与标准操作流程(SOP)[k]。当前训练数据多缺失设计文档、commit历史等中间产物,而这些“工程副产物”极具价值[k]。Diff models等研究已开始关注代码变更过程[k]。此外,“智力飞轮”效应——弱模型生成数据训练更强版本——正成为可能[k]。

评估模型性能同样面临数据瓶颈[k]。主流基准如HumanEval聚焦独立函数生成,脱离真实开发场景且易被训练数据污染[k]。新兴SWE-bench以解决真实GitHub Issue为目标,更具现实意义,但当前模型成功率极低[k]。未来评测需更贴近实际工程,涵盖复杂依赖与上下文,提供精准指标[k]。
建议按开发者经验层次划分任务,构建分层评测与训练数据集,推动自动化处理低复杂度任务[k]。LLM本身亦可用于分析不同职级程序员的行为差异,辅助任务分层建模[k]。


 提示词工程
提示词工程
IDE中的代码补全需平衡生成质量与响应延迟,通常采用较小规模模型[k]。GitHub Copilot等工具优先使用规则判断与缓存机制减少AI调用[k]。提示词构建依赖光标上下文、打开文件及显式依赖,力求信息丰富且简洁[k]。
为提升质量,可结合监督微调或RAG技术[k]。利用代码语法规律性,推测解码算法(Speculative Decoding)可加速生成过程[k]。用户对生成结果的验证负担较重,可通过UI展示上下文依据、自动合规检查、静态分析或编译执行等方式辅助决策[k]。
首个响应需低延迟,后续可调用更大模型生成备选方案,通过多结果对比提升最终输出质量[k]。IDE工具应持续记录用户编辑行为,形成高质量训练数据,优于传统“挖空”代码的方式[k]。

 检索增强生成(RAG)
检索增强生成(RAG)
RAG在代码问答中需针对代码特性优化[k]。通常以函数或方法为最小单元,结合语言、路径、行号等元数据建立索引,使用FAISS或向量数据库进行检索[k]。

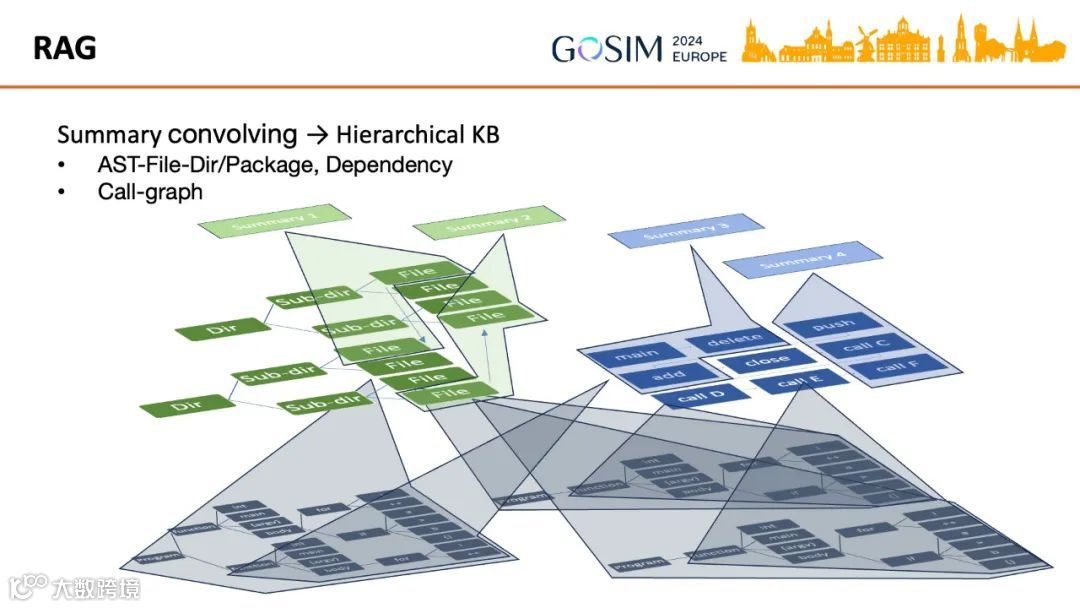
面对大型代码库,需构建分层知识库(Hierarchical KB):对函数/方法进行LLM概括,逐层聚合至文件、包、目录级别;或结合静态分析提取调用图(Call-graph),对节点及其依赖进行多层概括与向量化[k]。知识图谱(如GraphGen4Code)可作为底层结构,增强元数据与概括效果[k]。
实践中常融合向量语义检索与关键词检索,先召回较多结果再通过rerank模型或生成模型筛选最优项,以平衡性能与计算开销[k]。随着上下文窗口扩大(如Gemini支持1M token),可将整个代码库载入上下文,形成“神经网络知识库”(Neural KB),或可超越人工构建的层次化知识库[k]。

 智能体(Agent)技术
智能体(Agent)技术
当前Agent实践多采用Multi-Agent System,引入多个角色协同完成任务[k]。例如AgentCoder中,LLM实现程序员与测试设计师Agent,Python运行时实现测试执行者Agent[k]。
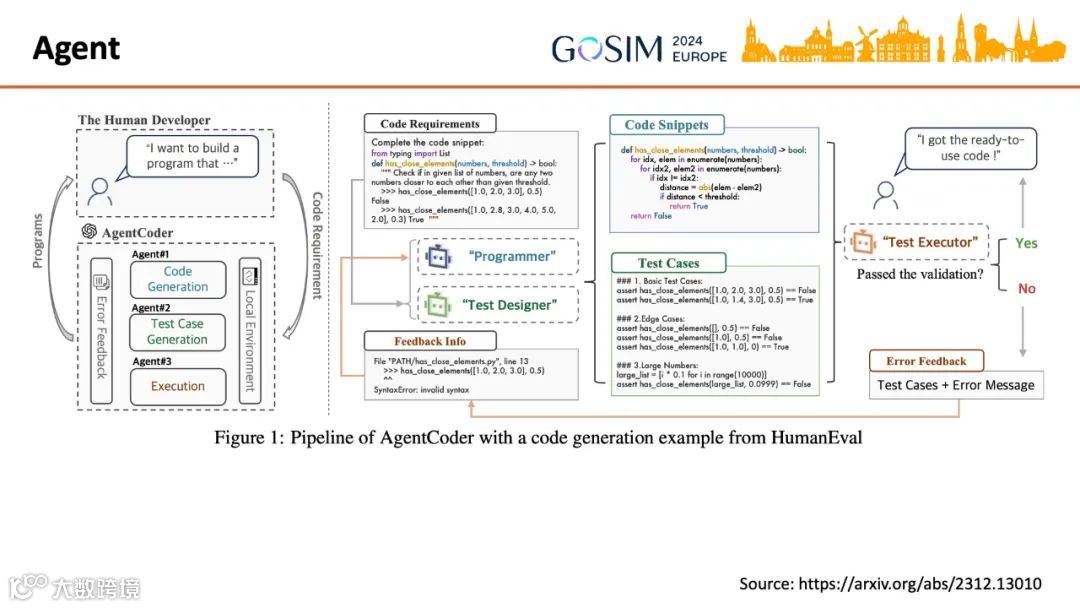
多数Agent的核心逻辑隐藏于提示词中,通过分析代码或配置文件即可理解其工作机制[k]。GPT-Pilot、MetaGPT、ChatDev等项目模拟软件公司运作,设定多种角色与标准流程[k]。值得思考的是,AI的引入应如何重构现有开发角色与流程,以实现更高效的协同[k]。

AI编程代理的演进与开源新范式

2024年引发广泛关注的“Devin——首个AI软件工程师”,其开源实现SWE-Agent标志着AI编程代理的重要进展。该技术与AgentCoder、GPT-Pilot本质趋同,核心差异在于集成了更适配Issue处理的工具链与工作流程[k]。
AI代理在软件开发中的应用,关键在于为大语言模型(LLM)配备专用工具和标准操作流程(SOP)。尽管LLM是否具备真正的逻辑推理能力仍存争议,但大量实证研究表明,借鉴“组织人类工作”的方法可有效引导LLM产出高质量结果。考虑到人类自身亦常表现出非理性与不精确,通过结构化流程提升AI表现具有现实可行性[k]。

开源行动:数据驱动的新范式
 在上述背景下,卢威提出“开源行动”倡议。未来开源运动的核心将不仅限于代码,数据——包括种子案例、各领域SOP、工程中间产物等——将发挥关键作用。即便是小规模数据,亦可通过LLM合成扩展,释放巨大价值[k]。
在上述背景下,卢威提出“开源行动”倡议。未来开源运动的核心将不仅限于代码,数据——包括种子案例、各领域SOP、工程中间产物等——将发挥关键作用。即便是小规模数据,亦可通过LLM合成扩展,释放巨大价值[k]。
为保障数据开放的安全性,亟需发展新型数据脱敏与匿名化技术。差分隐私等方法,结合LLM自身能力,有望构建安全可控的数据共享机制,推动专有数据拥有者参与开源生态[k]。
单一模型通吃所有场景的模式并非终极方向。实现“在正确时机、由合适模型、为特定用户、完成特定任务”的精细化适配,是未来关键目标,而开源模式正是实现这一愿景的重要基石[k]。

