
Cao, S., Wang, C. C. Y., & Yi, X. in press. When LLMs Go Abroad: Foreign Bias in AI Financial Predictions. Working Paper.
文章主要内容:这篇文章研究了人工智能在预测金融市场中存在的外国偏见。文章发现,ChatGPT (基于美国的模型)比DeepSeek (基于中国的模型)系统性地更加看好中国公司,表现为预测的年末股票价格更高,并产生更多的购买建议,这种AI特有的现象与投资者偏好国内资产的传统本土偏好相矛盾。作者将这种偏见归因于信息获取的差异:当美国媒体对中国企业负面新闻的报道相对于中国媒体稀少时,ChatGPT的乐观性增加。文章的结论表明,大语言模型在不同国家的平行发展可以产生不同的金融预测,这可能会放大而不是减少跨境信息不对称,因为这些工具在全球范围内塑造了投资决策。
文章背景:大语言模型( Large Language Models,LLMs )在财务分析中的迅速采用,标志着投资信息的生产和消费方式发生了根本性的转变。ChatGPT在2022年11月上线的两个月内就达到了1亿用户,彭博调查显示,超过40 %的机构投资者现在使用AI工具进行市场分析。许多文献对于AI工具的金融预测能力进行了检验,然而,越来越多的金融学工作揭示了将LLM应用于金融分析的潜在风险,如外推误差、误校正以及其他可能扭曲预测的异常等。这些偏误既来自训练语料的构成,也来自建模的选择。本文关注的可能偏差,来自于不同国家前沿模型发展的差异,这种模型发展的差异本质上来自于模型环境的不同,且可能影响跨国投资分析、市场效率以及人工智能的全球扩散。
样本:上交所、深交所上市公司,且在Compustat Global有数据。以 2023年12月31日Compustat Global中的中国企业为初始样本,要求企业具备关键财务变量数据,如总资产、资产回报率、杠杆率等。最终收集了4,978个中国企业样本。
模型预测:(1)采用两个前沿模型收集股票价格预测和投资建议:ChatGPT 4 . 1 (OpenAI开发)和Deepseek R1 (DeepSeek开发)。训练样本期截止于2024年6月30日,所有预测均针对2024年12月31日的同一未来日期,形成了6个月的样本外预测期。
(2)使用标准化的提示来确保模型之间的可比性:对于价格预测和买入推荐,对每个模型都进行如下提示:"这里有一个公司叫做' name ' ( ticker:ticker ),在中国A股上市。作为一名专业的财务分析师,请:1 .预测其2024年12月31日的股价(小数点后三位)。2.预测今年6月底至2024年12月31日的价格是否会上涨。不要使用当前的在线数据或随机数,尽最大努力"。
(3)为了保证数据的可复制性,文章将温度(temperature)设置为零。为了保证数据质量,我们在一周后再次对所有样本企业的两个模型进行了一致性检验,发现相关系数都超过了0。95,两种模型的预测效果均较好。
新闻报道数据:为了研究驱动AI预测差异的机制,文章收集了来自美国和中国媒体的综合数据。美国的媒体报道来自RavenPack,且提供了新闻报道的情感得分。中国媒体报道来自中国财经新闻数据库(CFND),也包括新闻情感得分。分别汇总了从2021年6月30日到2024年6月30日的所有新闻条目。
构建了两个企业层面的跨国信息差距测度指标:NEG_NEWS_GAP和NET_NEG_NEWS_GAP,分别根据积极、消极新闻数量计算得来,公式如下:


控制变量:总资产的自然对数、资产负债率、ROA、净利润是否为负、BM、2023年的股票回报、2023年股票收益的标准差、机构投资持股比例。
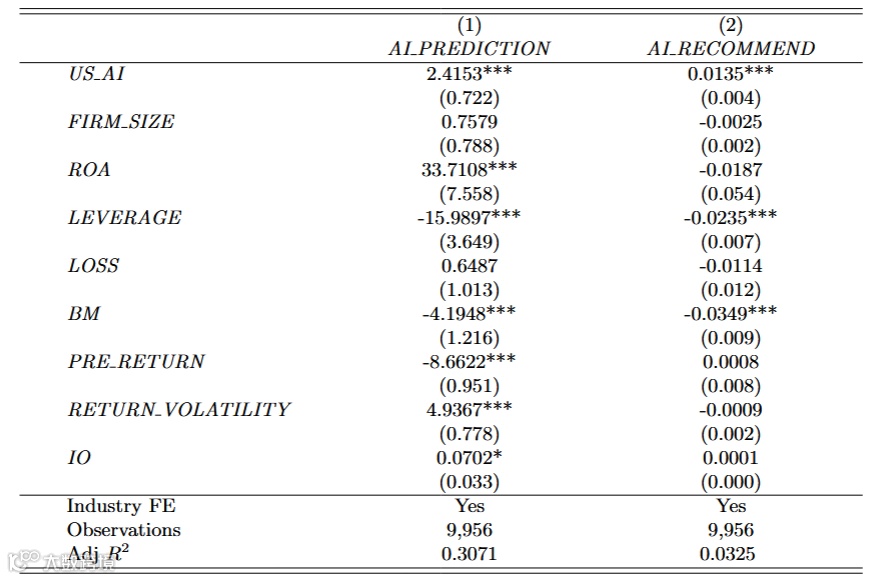
(1)Baseline
Y:AI 股价预测、AI买入建议(1 表示 “买入”,0 表示 “持有 / 卖出”)
X:“美国 AI(US AI)”(1 代表 ChatGPT 预测,0 代表 DeepSeek 预测)。
加入控制变量、基于 Fama-French 12 行业分类的行业固定效应
(2)检验信息不对称:加入报道偏差作为调节变量

交乘项表明当美媒负面报道少于中媒时,ChatGPT 比 DeepSeek 更乐观
(3)排除模型机械差异的影响
为了明确验证 AI “外国偏差” 的产生是否依赖真实的跨境信息不对称,而非模型本身的固有特性(即验证信息的效应),文章做了两项检验:
使用无新闻真实企业样本:聚焦过去 3 年无中美媒体报道的中国企业,发现系数不显著了;






对全球 AI 与金融生态的启示:
- 多极AI发展下的预测分化风险:随着不同国家基于本土语言语料开发各自的 LLMs,全球金融市场可能出现多套系统性有偏的预测视角。这意味着AI并非如预期般成为中立、客观的信息分析工具以消除人类行为偏差,反而可能引入新型偏差,且这类偏差的作用机制与传统人类偏差存在本质差异,可能加剧而非缓解跨境信息不对称。
- AI 金融应用的 “地理不平等” 隐忧:研究暗示AI本应 “democratize(普及)” 复杂金融分析的潜力可能落空——投资者对AI模型的选择受其地理可及性影响,而不同模型的偏差可能导致基于AI的投资决策出现地理分化,进一步扩大全球金融市场的信息差距与投资不平等。
实践层面的警示与解决方案:
- 投资者警示:明确提醒跨境投资者不可单一依赖某一国家开发的AI工具进行投资决策,此类模型的系统性偏差可能超过传统分析师偏差,导致对外国企业的误判;
- 偏差缓解路径:基于信息干预实验结果,提出可操作的解决方案 —— 通过为 AI 补充本土信息源、采用多模型组合(如整合不同国家训练的 LLMs)、或用均衡的多语言数据对模型进行微调,可有效消除 “外国偏差”,提升跨境金融预测的准确性。