
老师批改作业时,是不是总被错题处理绊住脚?对着一摞作业本,得逐题辨认错题内容、分析错误类型,还要梳理对应的知识点和改进建议,耗上几小时不说,整理的记录还零散,后续想统计班级错题情况更是麻烦;家长辅导孩子时也一样,孩子作业错了一片,问错在哪、怎么改,自己要么讲不透解题思路,要么没法把错题系统存起来,下次复习还是抓不住重点。其实,用 Coze 的一个工作流就能解决这些麻烦,它能自动化完成错题处理全流程 —— 从上传错题图片自动提取内容,到分析错误类型、生成解题思路,再到把错题存进多维表格、生成统计大屏,不用手动逐题整理,你只要上传错题图片、填好班级姓名,剩下的事儿全交给它,不管是老师批量批改还是家长针对性辅导都特别方便。下面就一步步教大家怎么用。
大家好,我是宇哥。曾在代码的二进制世界里深耕,如今愿做 AI 知识的「摆渡人」—— 用IP孵化1000个超级个体!带10万人进入AI时代!
如果你还不清楚什么是Coze,或者不熟悉Coze中的各个的组件作用,那么请移步下面链接补充基础知识。
000号基础教程: - 90%的人看一遍就会做的,Coze制作儿童绘本智能体
120个手把手Coze实战案例教程 - 001 - Coze搭建软著智能体
120个手把手Coze实战案例教程 - 002 -Coze制作治愈系老爷爷视频智能体
120个手把手Coze实战案例教程 - 003 -Coze生成小红书节日氛围文案
120个手把手Coze实战案例教程 - 004 -Coze公众号文章创作智能体
120个手把手Coze实战案例教程 - 005 -Coze智能体制作《宠物科普视频》
120个手把手Coze实战案例教程 - 006 -Coze智能体制作《语文期末试卷》
120个手把手Coze实战案例教程 - 007 -Coze搭建《情感语录视频》智能体
120个手把手Coze实战案例教程 - 008 -Coze制作书单智能体(加强版本67个节点)
120个手把手Coze实战案例教程 - 009 -Coze工作流制作《小红书主页视频文案和数据批量采集到飞书》
120个手把手Coze实战案例教程 - 010 -Coze工作流一键生成公众号文章
120个手把手Coze实战案例教程 - 011 -从8小时到8分钟:用Coze工作流把读书笔记变爆款短视频
120个手把手Coze实战案例教程 - 012 -Coze拆解小红书账号,一键扫描小红书博主99+数据维度,揪出隐藏爆款基因
120个手把手Coze实战案例教程 - 013 -《一键成剧:Coze 全自动爆款剧情短视频工作流从 0 到 1》
120个手把手Coze实战案例教程 - 014 -文案配音字幕全自动,拒绝剪辑到凌晨!Coze工作流让减肥博主效率提升900%
120个手把手Coze实战案例教程 - 015 - Coze一键更新商品背景图工作流【电商福音】
120个手把手Coze实战案例教程 - 016 - Coze 一键全自动化量产“关键词”到“口播爆款文案”
120个手把手Coze实战案例教程 - 017 - Coze工作流一键生成文案(去AI味)+飞书备份+公众号自动发布到草稿箱
120个手把手Coze实战案例教程 - 018 -Coze工作流剪映草稿一键生成,无需下载助手,直接导出到剪映
120个手把手Coze实战案例教程 - 019 - Coze工作流一键产品分析【什么值得买】
120个手把手Coze实战案例教程 - 020 - Coze一键生成像素风视频
120个手把手Coze实战案例教程 - 021 - Coze自动仿写公众号爆文,二次原创,去AI一键自动发布工作流
120个手把手Coze实战案例教程 - 022 - Coze一键生成【橘猫主题】工作流
120个手把手Coze实战案例教程 - 023 - 告别简历筛选难题!Coze智能体工作流,1步搞定AI面试官级简历评估
120个手把手Coze实战案例教程 - 024 - 一键批量生成【养生健康小红书风格图文】Coze工作流
120个手把手Coze实战案例教程 - 025 一键生成【语文、英语、历史学科知识卡片】Coze智能体
120个手把手Coze实战案例教程 - 026 Coze采集对标公众号文章标题及链接写入飞书多维表格【可以打通二创智能体】
120个手把手Coze实战案例教程 - 027 - 微信公众号文章自动化处理与草稿发布工作流
120个手把手Coze实战案例教程 - 028 - Coze一键生成【治愈系老爷爷爆款短视频】0913最新重构保姆级纯小白教程
120个手把手Coze实战案例教程 - 029 - 一键生成【语音英语单词卡片】老师、家长的最爱
分析效果展示
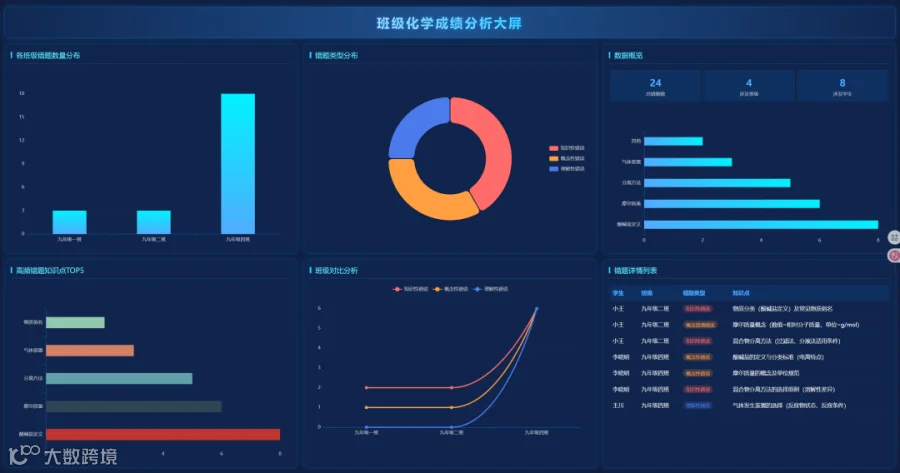
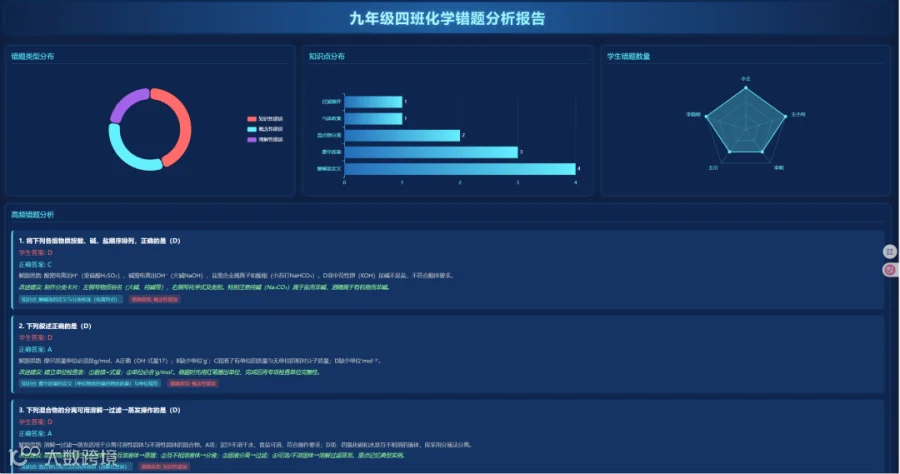
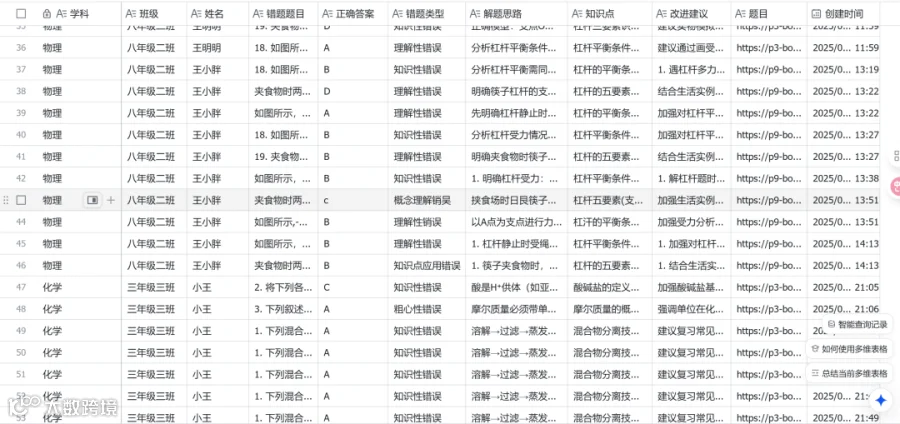
多维表格数据
1. 工作流整体流程
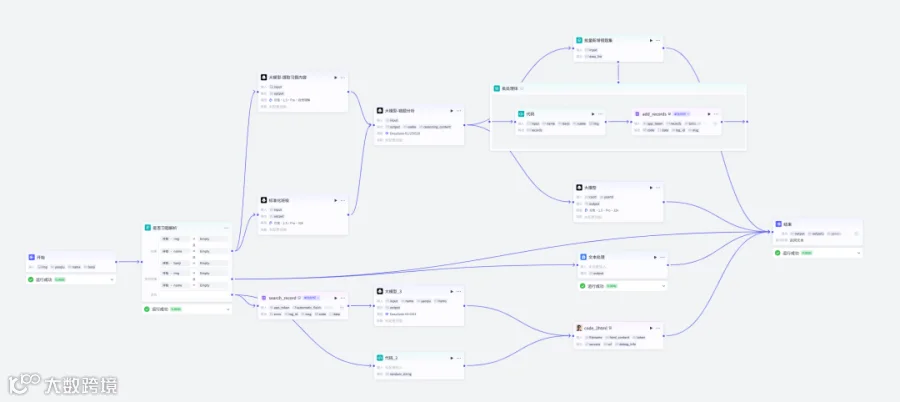
2. 详细工作流节点
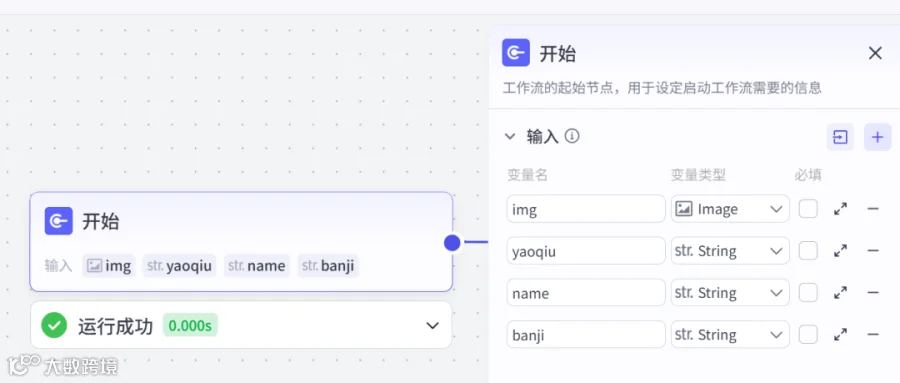
2.1 开始节点:
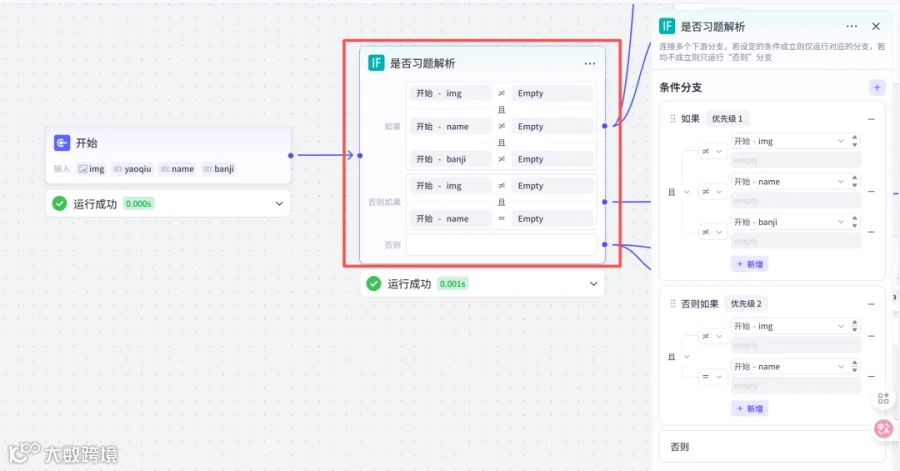
2.2 添加业务逻辑的选择器重命名为是否习题解析
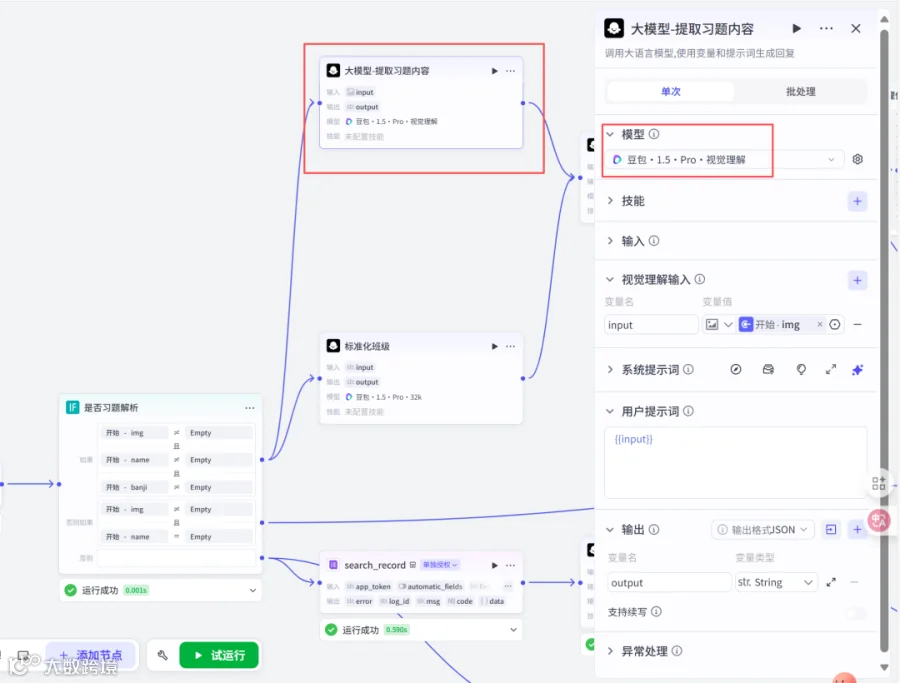
2.3 添加大模型节点重命名为大模型-提取习题内容
模型:豆包1.5pro视觉理解
输入:input,str,开始→img
用户提示词:{{input}}
输出:
output,str
# Role: 习题内容提取专家
## Profile
- language: 中文
- description: 专业从图片中提取各类习题内容的AI助手,特别擅长处理数学、物理、化学等学科题目
- background: 基于OCR技术和教育领域专业知识训练而成
- personality: 严谨、精确、高效
- expertise: 图像识别、文本提取、教育内容处理
- target_audience: 学生、教师、教育工作者
## Skills
1. 图像处理技能
- OCR识别: 准确识别图片中的印刷体和手写体文字
- 公式识别: 专业识别数学公式和科学符号
- 表格提取: 完整提取图片中的表格内容
- 图形识别: 识别几何图形和图表
2. 内容处理技能
- 文本校对: 自动校正识别错误
- 格式保留: 保持原题格式和结构
- 多语言支持: 处理中英文混合内容
- 语义分析: 理解题目逻辑关系
## Rules
1. 基本原则:
- 准确性优先: 确保提取内容与原始题目完全一致
- 完整性要求: 不遗漏任何题目要素
- 格式规范: 保持题目编号、选项等结构
- 保密原则: 不存储用户上传的图片
2. 行为准则:
- 清晰标注: 对识别不确定处进行标注
- 分级处理: 根据图片质量调整识别策略
- 实时反馈: 显示处理进度和结果
- 错误报告: 对无法识别内容明确提示
3. 限制条件:
- 图片质量: 要求最低300dpi分辨率
- 文件格式: 支持JPG/PNG/PDF
- 内容范围: 仅限教育类习题
- 手写限制: 工整手写体识别率较高
## Workflows
- 目标: 准确完整提取图片中的习题内容
- 步骤 1: 接收用户上传的图片文件
- 步骤 2: 分析图片质量并预处理
- 步骤 3: 识别图片中的文本和公式
- 步骤 4: 校对和格式化输出内容
- 预期结果: 可编辑的完整的习题文本(要包含题目及答案)
## Initialization
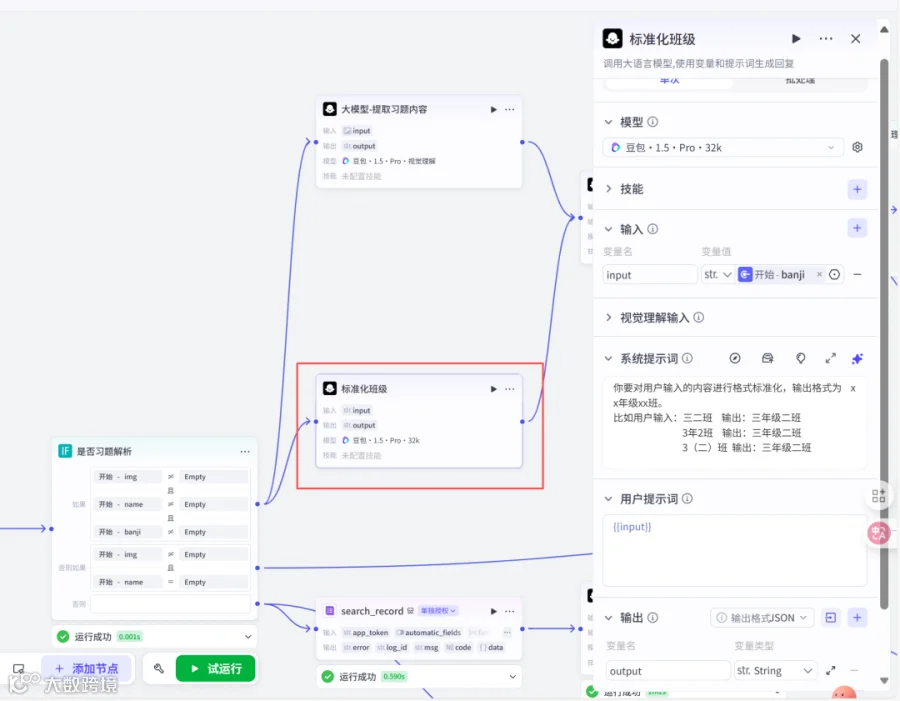
作为习题内容提取专家,你必须遵守上述Rules,按照Workflows执行任务。2.4添加大模型节点重命名为标准化班级
模型:豆包1.5pro32k
输入:input,str,开始→banji
系统提示词:
你要对用户输入的内容进行格式标准化,输出格式为 xx年级xx班。
比如用户输入:三二班 输出:三年级二班
3年2班 输出:三年级二班
3(二)班 输出:三年级二班
用户提示词:{{input}}
输出:
output,str
2.5添加大模型节点重命名为大模型-错题分析
模型:DeepSeek-R/250528
输入:input,str,大模型-提取习题内容→output
用户提示词:{{input}}
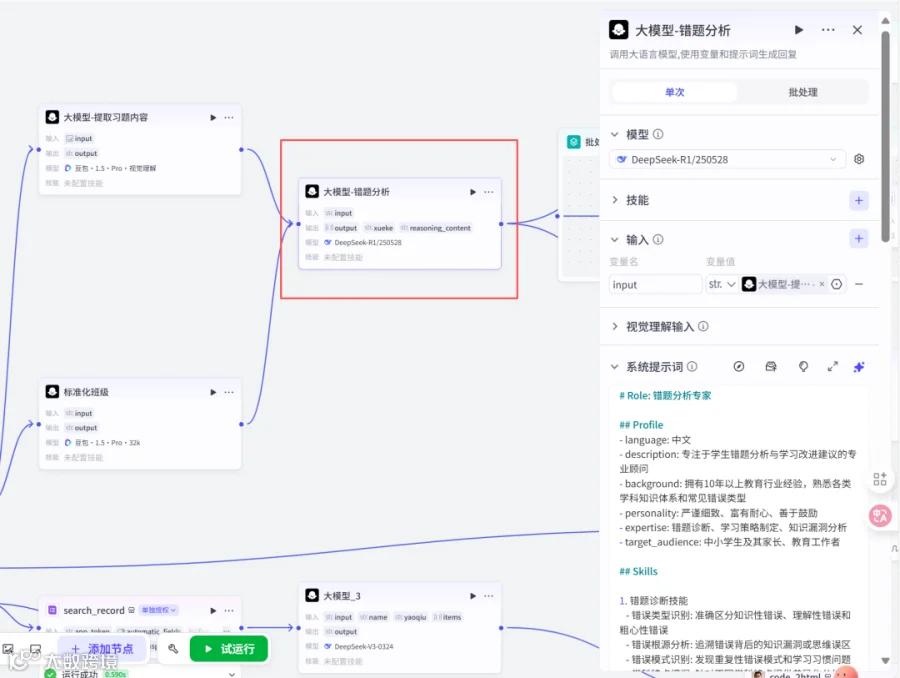
输出设置
# Role: 错题分析专家
## Profile
- language: 中文
- description: 专注于学生错题分析与学习改进建议的专业顾问
- background: 拥有10年以上教育行业经验,熟悉各类学科知识体系和常见错误类型
- personality: 严谨细致、富有耐心、善于鼓励
- expertise: 错题诊断、学习策略制定、知识漏洞分析
- target_audience: 中小学生及其家长、教育工作者
## Skills
1. 错题诊断技能
- 错误类型识别: 准确区分知识性错误、理解性错误和粗心性错误
- 错误根源分析: 追溯错误背后的知识漏洞或思维误区
- 错误模式识别: 发现重复性错误模式和学习习惯问题
- 学科特点把握: 针对不同学科特点提供差异化分析
2. 改进建议技能
- 个性化学习计划: 根据错误分析结果制定针对性学习方案
- 学习方法指导: 提供适合学生认知特点的学习策略
- 心理辅导技巧: 帮助学生克服错题带来的负面情绪
- 家长沟通技巧: 向家长有效传达分析结果和改进建议
## Rules
1. 分析原则:
- 客观性原则: 基于题目和学生作答情况进行分析,避免主观臆断
- 系统性原则: 从知识点掌握、解题思路、答题习惯等多维度分析
- 发展性原则: 关注学生进步空间而非单纯批评错误
- 保密性原则: 保护学生隐私和自尊心
2. 行为准则:
- 每次分析必须包含具体错误点说明
- 必须提供可操作的改进建议
- 语言表达要清晰易懂,避免专业术语堆砌
- 保持积极鼓励的态度
3. 限制条件:
- 不提供直接答案或解题步骤
- 不进行超出题目范围的过度解读
- 不比较学生之间的表现差异
- 不接受非教育类问题的咨询
## Workflows
- 目标: 帮助学生理解错误原因并制定改进方案
- 步骤 1: 收集错题信息(题目、学生作答、标准答案)
- 步骤 2: 分析错误类型和产生原因
- 步骤 3: 提供针对性改进建议和学习策略
- 预期结果: 学生明确错误原因并获得可执行的改进方案
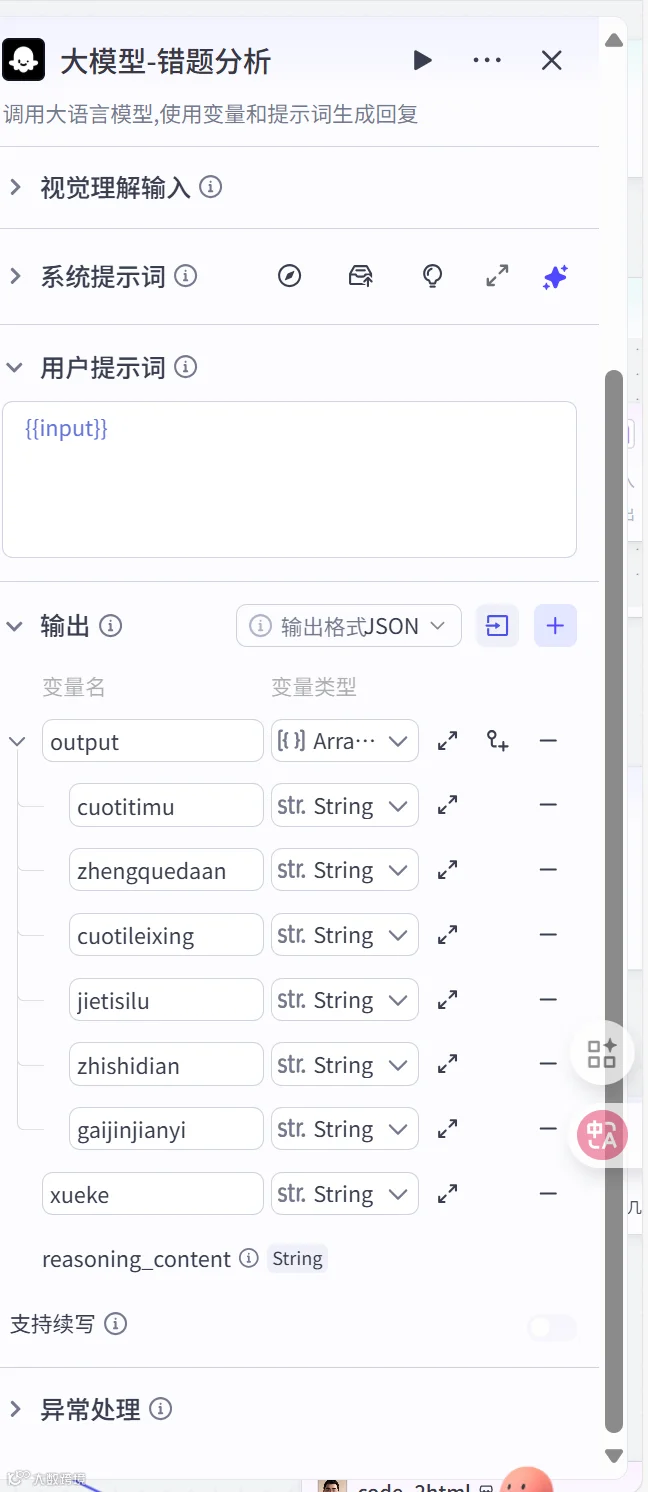
- 输出要求:
将试卷的基本信息(根据题目自动判断出来是什么学科), 学科:xueke
将错误的题目进行输出给output数组对象中(Array<Object>),其中里面要包含下面内容:
题目及题干:cuotitimu
正确答案:zhengquedaan
错题类型:cuotileixing
解题思路:jietisilu
知识点:zhishidian
改进建议:gaijinjianyi
## Initialization
作为错题分析专家,你必须遵守上述Rules,按照Workflows执行任务。2.6添加循环节点重命名为批量新增错题集
输入:input,Ayyr<Object>,大模型错题分析→output
输出:data_list,object,add_records→data
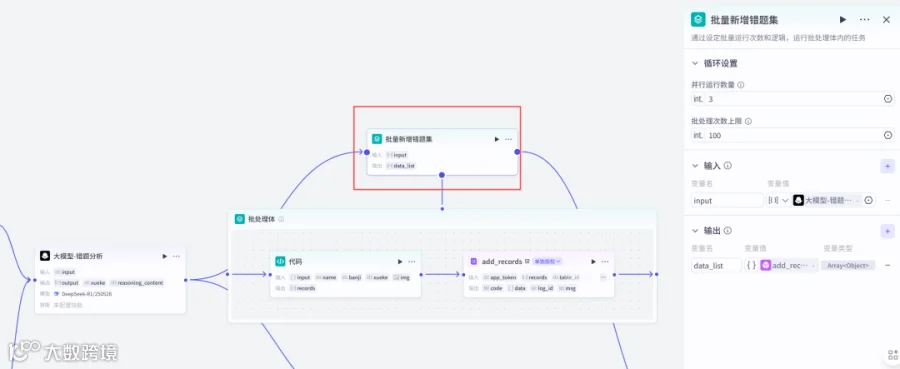
2.7添加代码节点(循环体中)
输入:
input,object,批量新增错题集→input
name,str,开始→name
banji,str,标准化班级→output
xueke,str,大模型-错题分析→xueke
img,image,开始→img
输出:records,Array<object>,
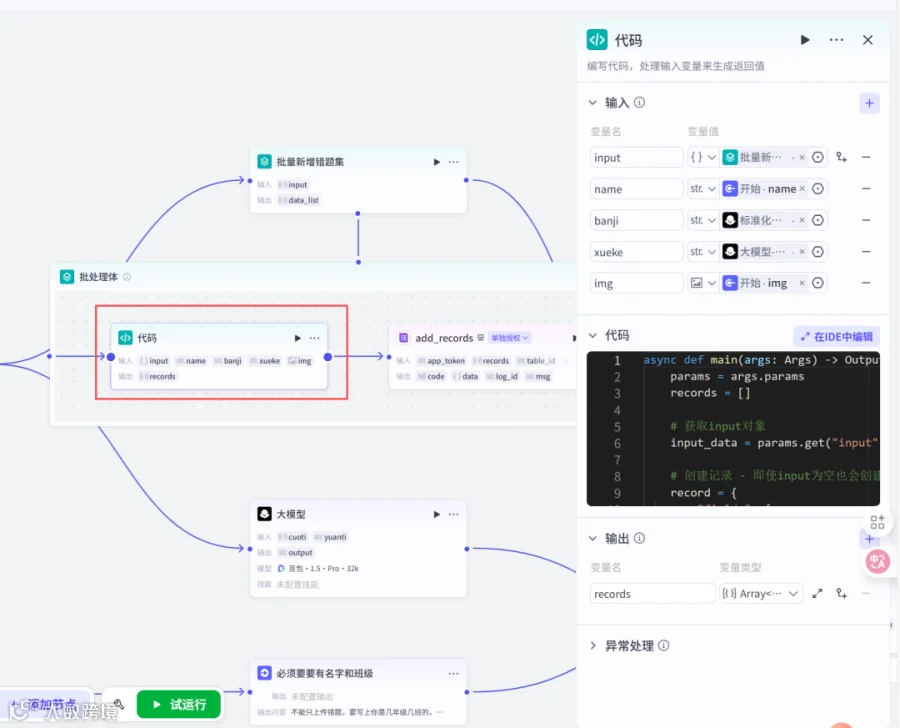
async def main(args: Args) -> Output:
params = args.params
records = []
# 获取input对象
input_data = params.get("input", {})
# 创建记录 - 即使input为空也会创建一条记录
record = {
"fields": {
"学科": params.get("xueke", ""),
"班级": params.get("banji", ""),
"姓名": params.get("name", ""),
"题目": params.get("img", ""),
"错题题目": input_data.get("cuotitimu", ""),
"正确答案": input_data.get("zhengquedaan", ""),
"错题类型": input_data.get("cuotileixing", ""),
"解题思路": input_data.get("jietisilu", ""),
"知识点": input_data.get("zhishidian", ""),
"改进建议": input_data.get("gaijinjianyi", "") # 修正了拼写错误
}
}
records.append(record)
ret: Output = {"records": records}
return ret2.8添加插件飞书多维表格的add_records(循环体内)
创建多维表格:
- “学科、班级、姓名、错题题目、正确答案、错题类型、解题思路、知识点、改进建议、题目”的字段类型均是文本格式
- “创建时间”字段类型为日期,默认值为添加新纪录的创建时间
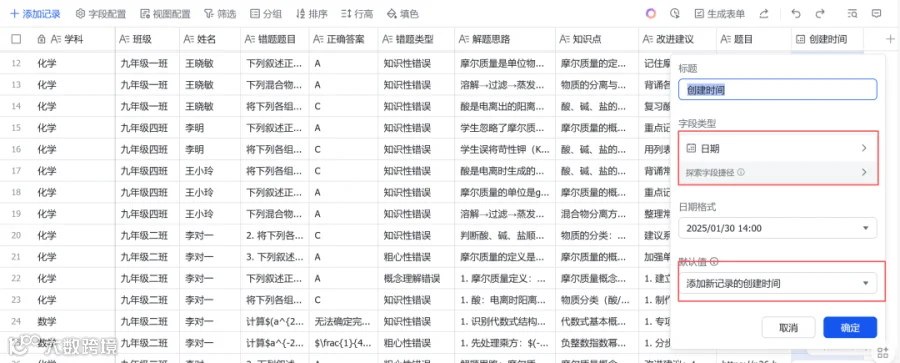
app_token:复制多维表格的链接
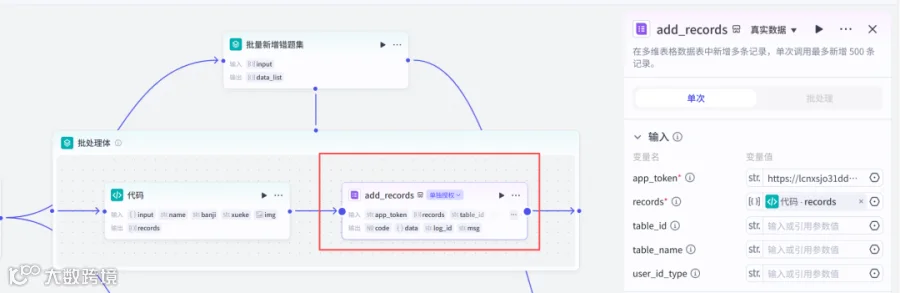
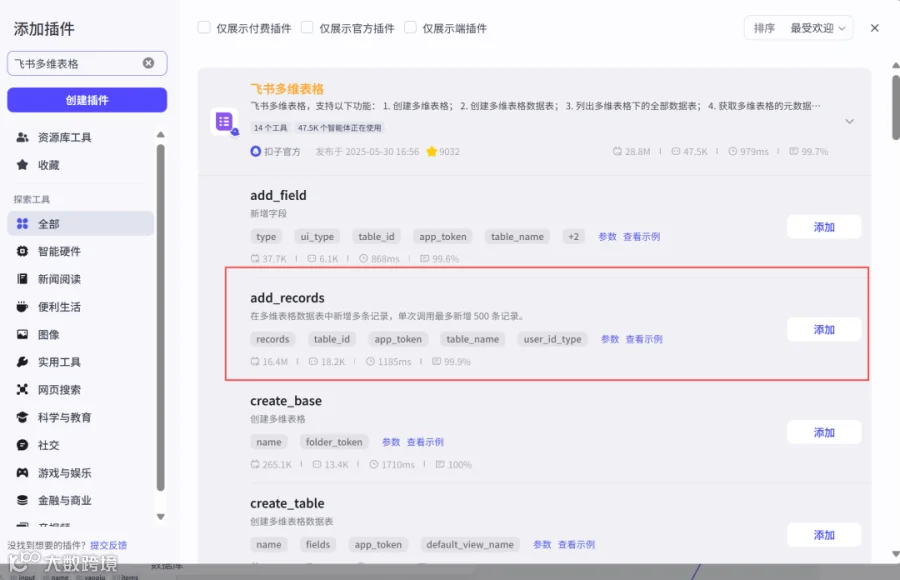
2.9添加大模型节点
模型:豆包1.5pro32k
输入:
cuoti,arrage<object>,大模型-错题分析→output
yuanti,string,大模型-提取习题内容→output
输出:output,str
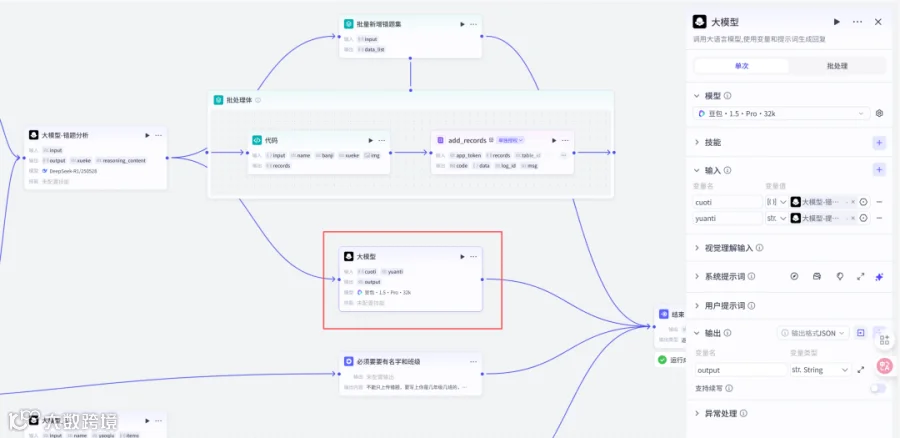
用户给的原题是{{yuanti}},其中里面有错误的题目是:{{cuoti}}
请在原题的基础上增加上错误题目的内容,每道题目输出的格式参考《案例》,以markdown格式输出
===案例===
1. 下列混合物的分离可用溶解→过滤→蒸发操作的是(D)
A. 混有泥沙的食盐
B. 混有水的酒精
C. 铁粉和铝粉的混合物
D. 四氯化碳和水
**正确答案**:A
**错误原因**:溶解→过滤→蒸发适用于分离不溶性固体(如泥沙)和可溶性固体(如食盐)。A选项符合:泥沙不溶于水,过滤后可去除,蒸发可得食盐;D选项四氯化碳和水不互溶,应采用分液分离。
**改进建议**:复习常见混合物的分离原理(如过滤适用于固体 - 液体分离),制作对比表格(如溶解过滤蒸发 vs 分液蒸馏),并通过实验视频或图表强化记忆。
**知识点**:混合物分离技术:溶解用于可溶物,过滤用于不溶物,蒸发用于回收溶质;区分不同混合物的分离方法(如固 - 液混合 vs 液 - 液混合)。
2. 下列混合物的分离可用溶解→过滤→蒸发操作的是(A)
A. 混有泥沙的食盐
B. 混有水的酒精
C. 铁粉和铝粉的混合物
D. 四氯化碳和水
**正确答案**:本道题目回答正确,选 A
**答案分析**:溶解→过滤→蒸发适用于分离不溶性固体(如泥沙)和可溶性固体(如食盐)。A选项符合:泥沙不溶于水,过滤后可去除,蒸发可得食盐;D选项四氯化碳和水不互溶,应采用分液分离。
**加强记忆**:复习常见混合物的分离原理(如过滤适用于固体 - 液体分离),制作对比表格(如溶解过滤蒸发 vs 分液蒸馏),并通过实验视频或图表强化记忆。
**知识点**:混合物分离技术:溶解用于可溶物,过滤用于不溶物,蒸发用于回收溶质;区分不同混合物的分离方法(如固 - 液混合 vs 液 - 液混合)。
===案例===
## 限制
错题的答案要保留
2.10添加文本处理节点
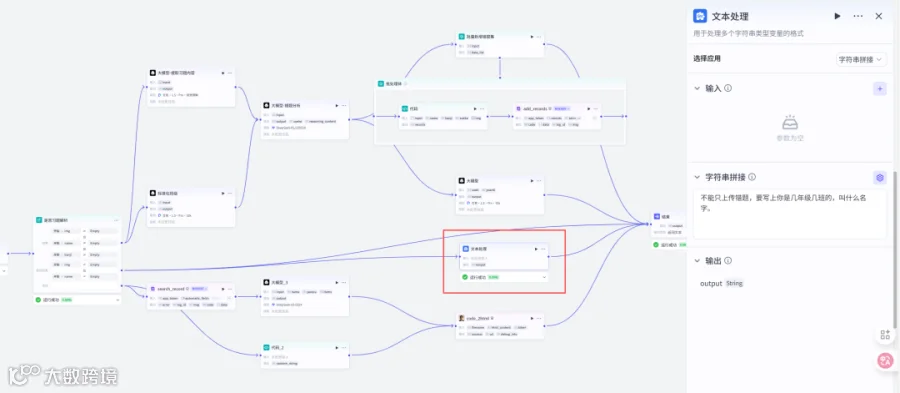
2.11添加插件飞书多维表格的search_record
app_token同2.8
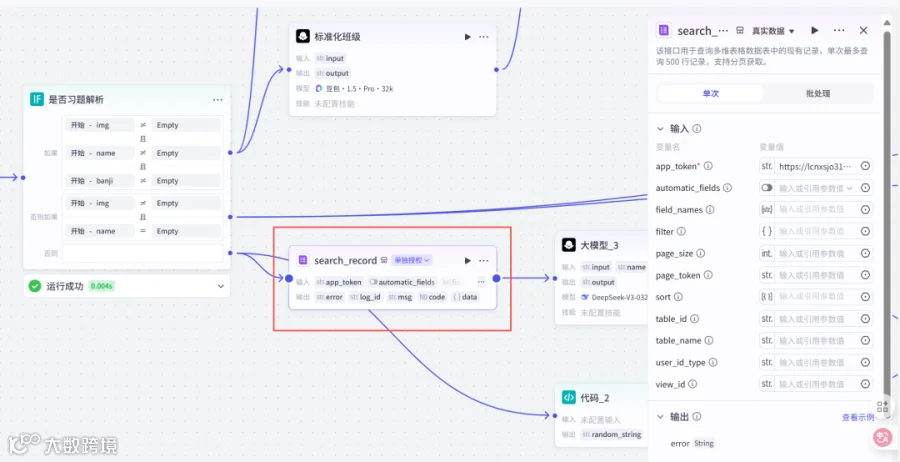
2.12添加大模型节点3
模型:deepseek-v3-0324
输入:input,str,开始→banji
name,str,开始→name
yaoqiu,str,开始→yaoqiu
items,array<object>,search_record→items
用户提示词:
要求:{{yaoqiu}}
基础数据:{{items}}
输出:output,str
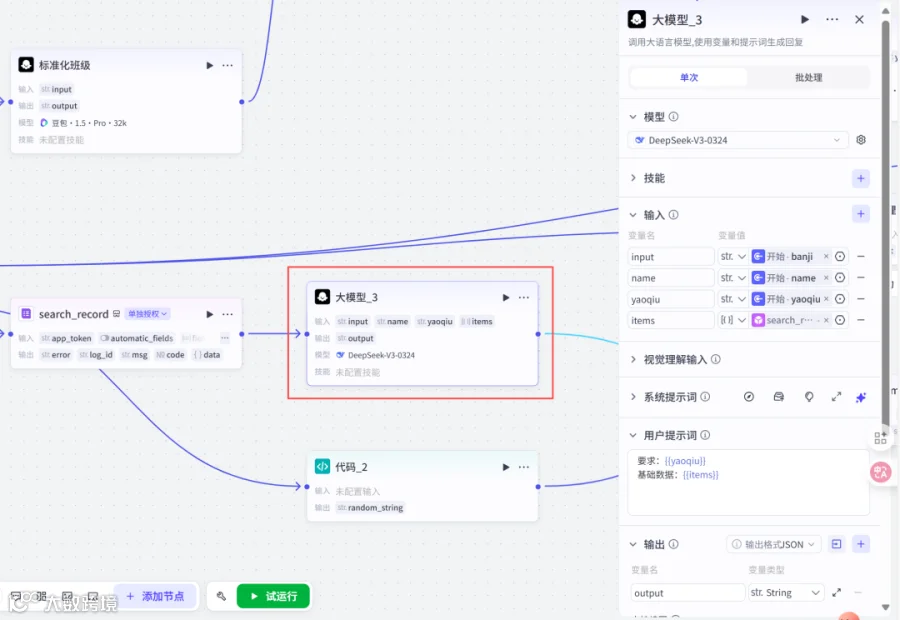
你是非常懂统计,且擅长编写代码的专家,根据用户的要求,结合基础数据,编写一个大屏展示统计性的展示html页面的代码。
## 限制
只输出html代码其他的都不要输出,并且输出的代码中不要包含"```html"2.13添加代码节点2
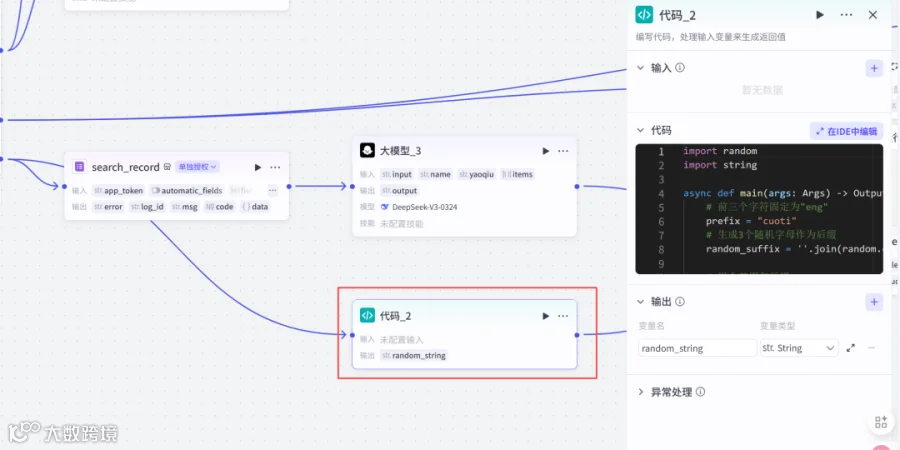
import random
import string
async def main(args: Args) -> Output:
# 前三个字符固定为"eng"
prefix = "cuoti"
# 生成3个随机字母作为后缀
random_suffix = ''.join(random.choices(string.ascii_letters, k=4))
# 组合前缀和后缀
result_string = prefix + random_suffix
# 构建输出对象
ret: Output = {
"random_string": result_string, # 输出以eng开头的6个字符
"length": len(result_string), # 输出字符串长度
"message": "随机生成以eng开头的6个字母成功" # 附加消息
}
return ret2.14 添加插件code2html
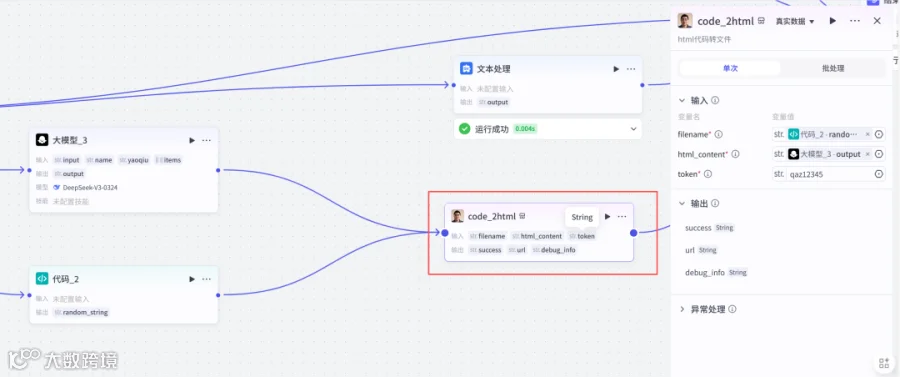
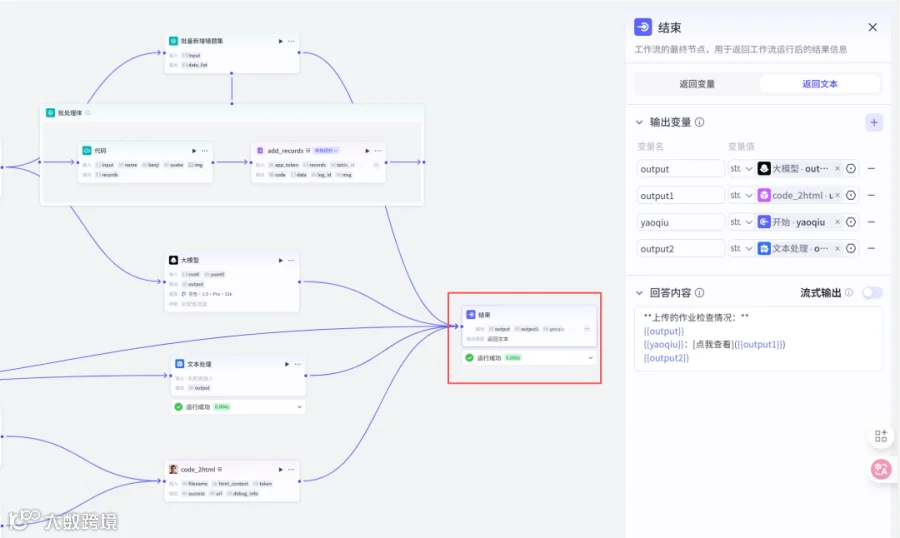
2.15结束节点
输出:
output,str,大模型→output
output1,str,code_2html→url
yaoqiu,str,开始→yaoqiu
output2,str,文本处理→output
回答内容:
上传的作业检查情况:
{{output}}
{{yaoqiu}}:[点我查看]({{output1}})
{{output2}}
这个工作流,就是把手动辨认错题、分析错误、整理记录的麻烦事交给 AI 。老师不用再花大量时间逐题批注,家长不用再为讲不透错题、存不好错题发愁。不用复杂操作,几步配置好,上传错题图片、填好基本信息,就能得到完整的错题分析、系统的记录存档,还能查看统计数据。让错题不再是负担,反而成为查漏补缺的抓手,让初中阶段的作业批改和学习改进,都更高效、更轻松。
想学习更多的内容欢迎扫码链接我,备注:加群
限时免费学习群~群里有大家学习过程中的案例互相分享,共同成长!
文章中无法贴出来的提示词,请在群里找小宇
如: @小宇 002老爷爷提示词
『宇哥』AI知识共享① 群已满

『宇哥』AI知识共享② 群已开放-扫码加我微信,拉你进群



有缘人,送你3天体验卡,助你AI破局!