
你可能听说过腾讯IMA,这是腾讯推出的一款基于微信生态的AI智能工作台,主打 “搜、读、写、管”一体化的知识管理与内容创作平台。
它不仅仅是一个AI问答工具,也一个面向个人和团队的 “第二大脑” 级知识库系统。

但是线上IMA有一个缺点,不适合企业端,以及注重个人数据隐私的用户。
比如要上传企业内部规章制度、合同、法律文书、产品技术文档等等,线上IMA就不合适。也无法实现跨部门、多文档格式、合规要求较高等的需求。
但是近日腾讯开源了自家的IMA(知识库)开源了,换了个新名字叫WeKnora(维娜拉)。上线以来已经获得3.2K Star。
github 地址:https://github.com/Tencent/WeKnora
本期为你详细介绍
-
1. WeKnora(维娜拉)核心特性 -
2. 知识库主流 LLM + RAG架构 -
3. WeKnora适用场景 -
4. 部署方式 -
5. 多模态图谱信息提取 -
6. API调用成本&个人使用感受
- 精准理解:支持 PDF、Word、图片等文档的结构化内容提取,统一构建语义视图
- 智能推理:借助大语言模型理解文档上下文与用户意图,支持精准问答与多轮对话
- 灵活扩展:从解析、嵌入、召回到生成全流程解耦,便于灵活集成与定制扩展
- 高效检索:混合多种检索策略:关键词、向量、知识图谱
- 简单易用:直观的Web界面与标准API,零技术门槛快速上手
- 安全可控:支持本地化与私有云部署,数据完全自主可控
官网地址:https://weknora.weixin.qq.com/
使用LLM + RAG主流架构
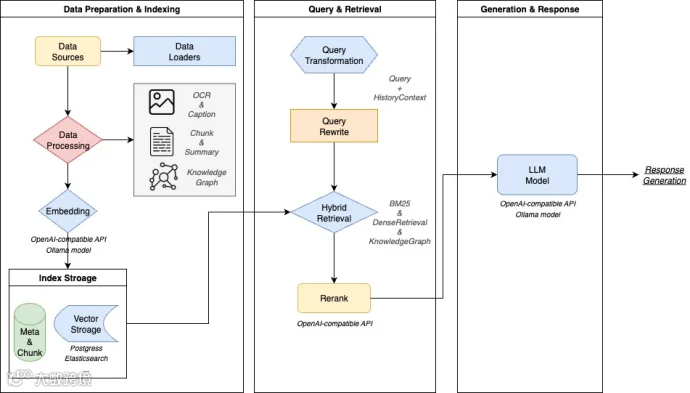
这是一款基于大语言模型(LLM)的文档理解与语义检索框架,专为结构复杂、内容异构的文档场景而打造。
核心检索流程基于 RAG(Retrieval-Augmented Generation) 机制,将上下文相关片段与语言模型结合,实现更高质量的语义回答。
小知识:RAG是什么
RAG(Retrieval-Augmented Generation,检索增强生成)是当下大模型时代最实用、最落地的“外挂知识”技术。通过让模型回答前先查资料,减少幻觉、提升时效、支持私有知识。
RAG基本流程
- 切片(Chunking):PDF/Word/网页 → 固定长度文本块(512 token 常见)。
- 向量化(Embedding):用 BERT/Embedding 模型把文本变成向量,存入向量数据库(Milvus、Pinecone、Chroma、PGVector)。
- 检索(Retrieval):用户问题向量化 → Top-K 近似搜索(ANN/HNSW)。
- 重排(Rerank):用 Cross-Encoder 再精排,过滤低相关块。
- 生成(Generation):把检索结果拼成 Prompt,喂给大模型,输出来源可追溯的答案。
WeKnora适用场景
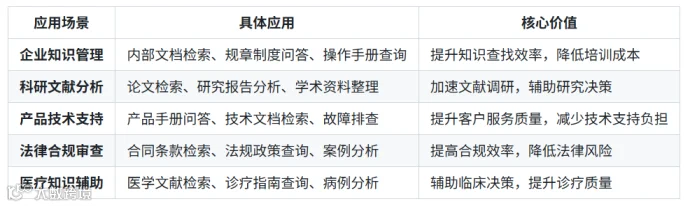
比如:
-
1. 制造型企业通过部署 WeKnora,将 设备手册转化为结构化知识库,帮助技术人员快速查询故障解决方案。 -
2. 律所可以利用 WeKnora 处理上万份合同,系统能自动标记 "违约责任"" 争议解决 " 等关键条款,并通过知识图谱展示相似案例的判决结果关联。 -
3. 科研机构科轶通过WeKnora 的跨文档关联能力,帮助研究人员发现隐藏联系。通过构建知识图谱,系统自动揭示相关技术概念在不同研究中的演化关系,辅助科研人员快速把握领域进展。 -
4. 微信生态集成。比如教育机构通过公众号接入 WeKnora,家长上传招生简章图片即可自动解答 "招生范围"" 报名时间 " 等问题。 5. 零售企业在小程序中部署产品手册问答,用户拍摄说明书照片就能获取保修政策解读,大幅降低客服压力。
部署方式
推荐使用Docker方式,参考官方手册:https://github.com/Tencent/WeKnora
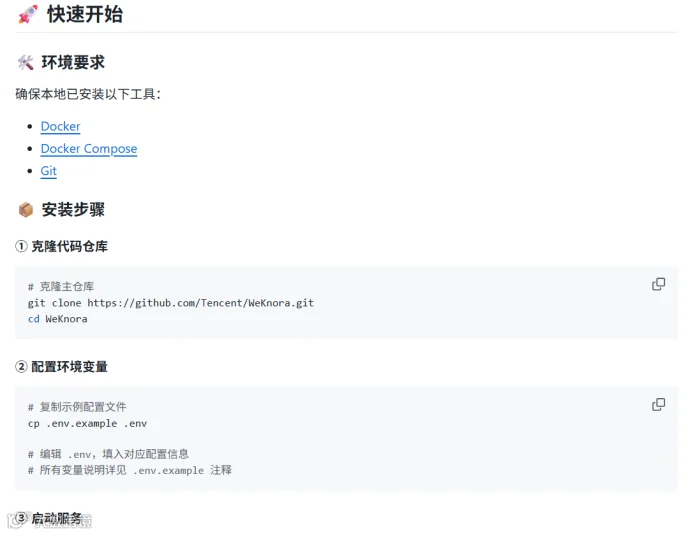
启动成功后,浏览器通过http://+服务器公网IP地址 访问
初始化配置
首次访问会自动跳转到初始化配置页面,必须配置的模块有:LLM 大语言模型配置、Embedding 嵌入模型配置、Rerank配置。下面逐个介绍:
-
1. LLM 大语言模型配置
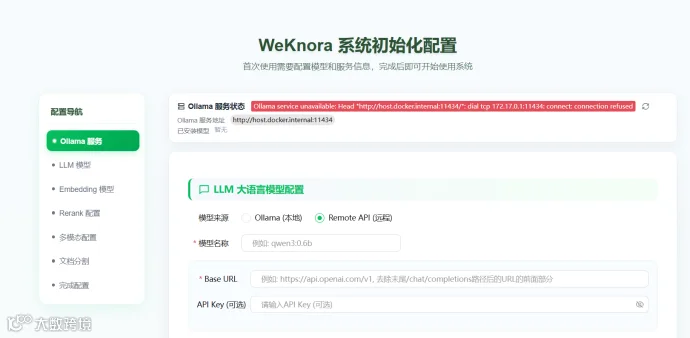
这里选择硅基流动,比如选择最新的 deepseek-ai/DeepSeek-V3.1
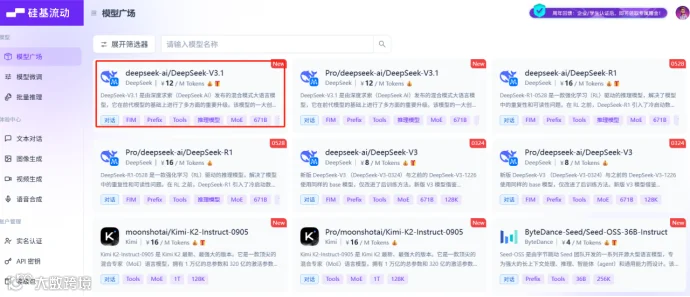
创建API Key
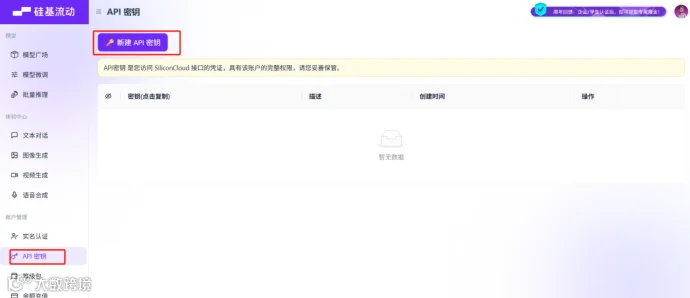
硅基流动新用户会赠送一定金额,大概14元左右。新手测试WeKnora是完全够用的。
选择Remote API(远程),将模型名词、Base URL、API Key依次填入
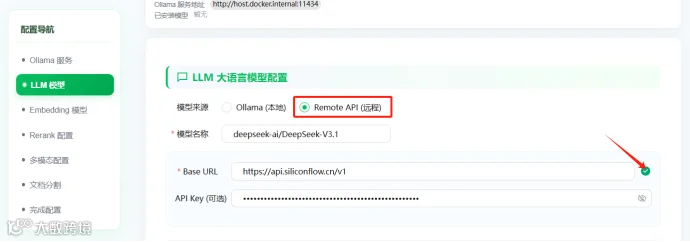
硅基流动Base URL地址为:https://api.siliconflow.cn/v1,注意Base URL旁边显示有绿色箭头,说明模型接入成功
填入Rerank模型
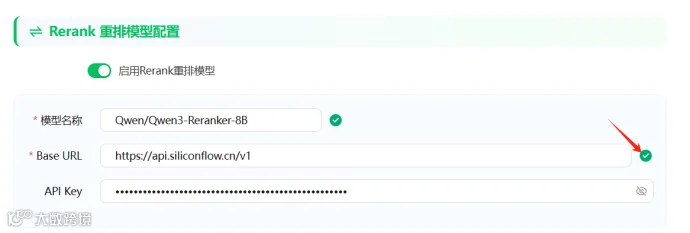
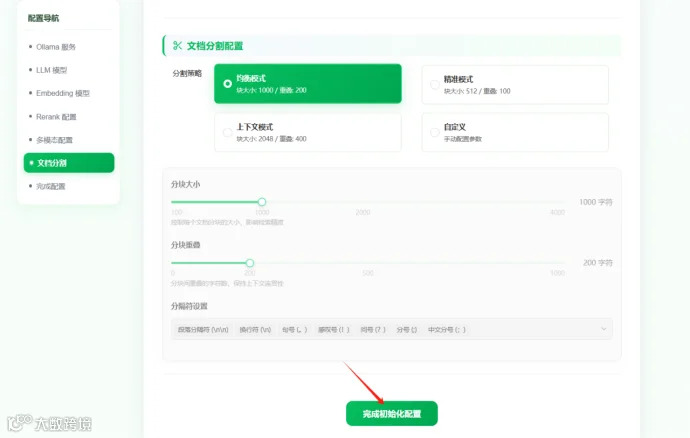
文档分割配置默认即可,点击完成初始化配置
跳转自动进入Weknora主页,可以看到页面分为三个部分左侧菜单栏提供知识库和对话入口,中间是上传文档。
下面,上传一些内部文档进行测试
等待解析完成
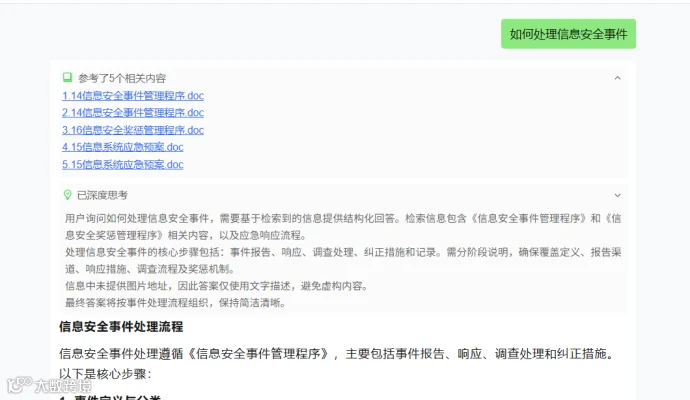
在知识库中提问,比如打入 如何处理信息安全事件 可以看到知识库对上传文档进行了搜索,并参考了5个相关内容,最后整理输出。回答内容可读性很好。
多模态图谱信息提取
WeKnora除了支持支持 PDF、Word外,还可以对图片进行内容提取,只需要几步配置就可以实现。
首先在硅基流动筛选视觉模型 比如 Pro/QwenyQwen2.5-VL-7B-Instruct
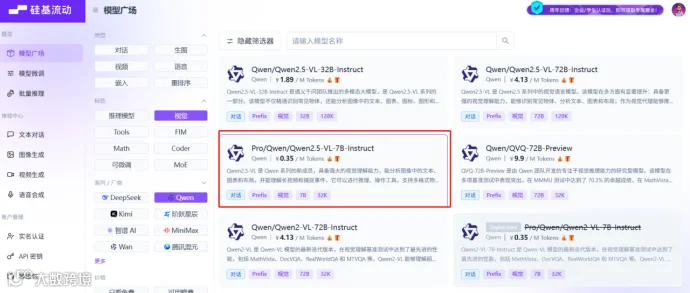
将硅基流动对应模型信息填入
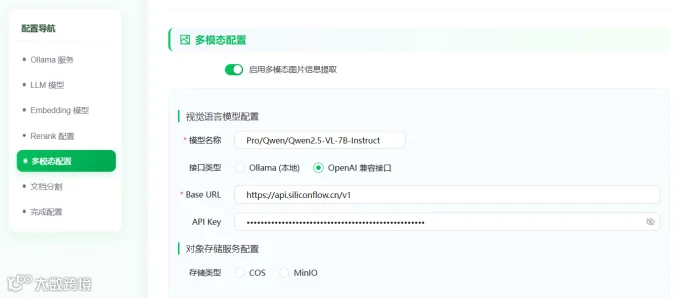
继续配置对象存储服务配置,这里选择COS
腾讯云 COS(Cloud Object Storage)是腾讯云提供的分布式对象存储服务,用于存储和管理海量非结构化数据,如图片、音视频、文档、备份文件等。它具有高可靠性、高扩展性、低成本和安全性强等特点,适用于网站托管、数据备份、大数据分析、多媒体处理等多种场景。
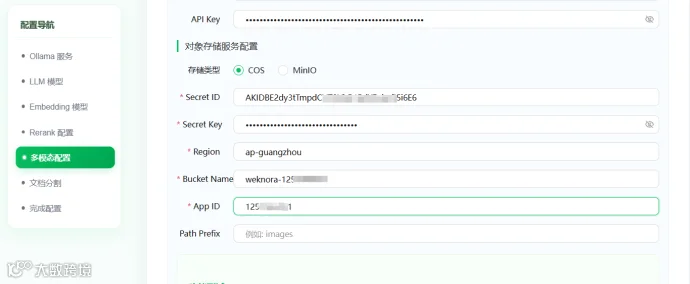
COS如何开通和使用可以参考官方文档:https://cloud.tencent.com/document/product/436/7751
填写完毕后,系统要求必须上传一张图片测试图片描述和文字识别功能
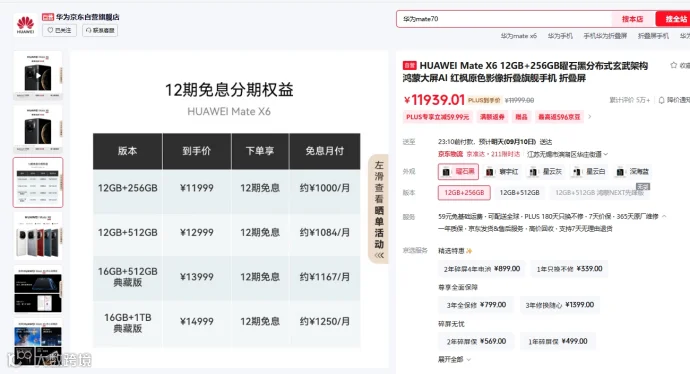
这里某品牌手机宣传页举例
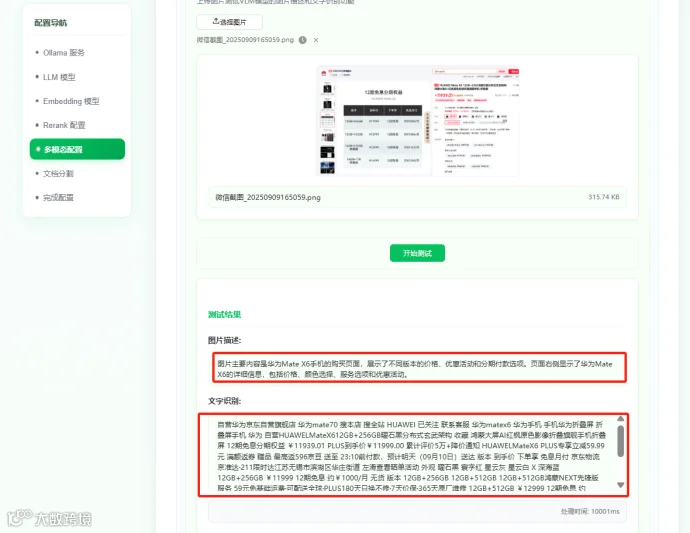
上传图片,并点击开始测试,可以看到大模型返回了结果,图片描述和文字识别都准确进行了识别。
点击更新配置信息,显示配置更新成功
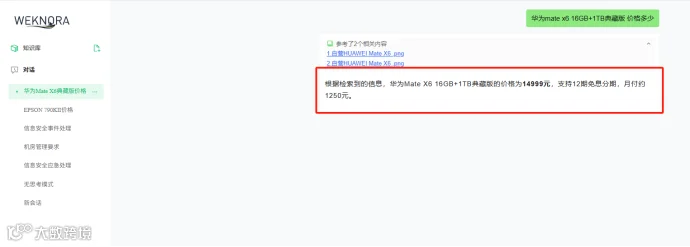
然后把图片上传到WeKnora中,然后新建对话,比如问一下 华为mate x6 16GB+1TB典藏版 价格多少
可以看到知识库回答正确和图片上信息完全一致
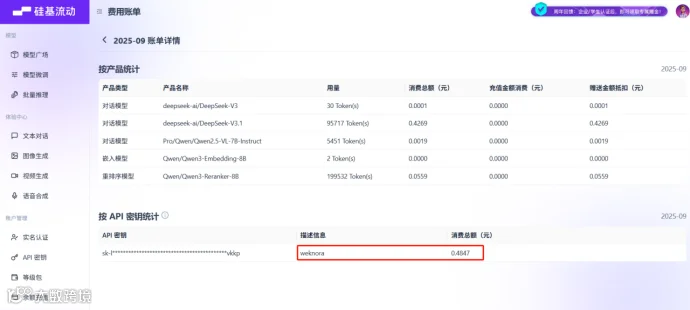
最后查看一下本次测试所耗费的API费用 一共0.5元不到。后面也可以改换硅基流动其他模型,或者接入Ollama本地模型,进一步降低成本。
个人使用感受
-
1. WeKnora有强大的多模态解析能力,它不仅支持 PDF、Word 等主流格式,还能通过多模态模型识别图片中的文本信息,尤其对图文混排文档的处理堪称精准 。体验下来,这点是很不错的。 -
2. 可以接入微信生态,零代码在微信生态快速部署智能问答服务。 -
3. 作为私有化部署的知识库系统,可以满足基本个人/企业知识库需求。但整体上,更像是精简版的腾讯IMA。 -
4. 区别于线上IMA版本,WeKnora没有文件夹概念,文档无法分类,不知道为什么这样设计。 -
5. 对了,还有WeKnora(维娜拉)这个名字太难读啦!期待后续更新。
以上就是今天的分享内容,我们下期见。
如果你觉得文章好看,请点赞 + 转发 + 评论 关注「科叔AI进化记」
END
为了帮助大家快速入门AI工作流和AI编程,科叔拉了一个微信交流群,围绕Dify、n8n、coze、Trae等展开,每天分享最新AI资讯和学习干货。
感兴趣可以关注公众号「科叔AI进化记」聊天框回复「AI交流群」加入
#RAG #weknora #ima #知识库 #国产 #开源 #腾讯