
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言
1、[CL] HREF:Human Response-Guided Evaluation of Instruction Following in Language Models
2、[CV] Personalized Representation from Personalized Generation
3、[CL] Maximize Your Data's Potential:Enhancing LLM Accuracy with Two-Phase Pretraining
4、[CL] Inference-Aware Fine-Tuning for Best-of-N Sampling in Large Language Models
5、[CL] A Systematic Examination of Preference Learning through the Lens of Instruction-Following
摘要:人类响应引导的语言模型指令遵循评估、从个性化生成到个性化表示、通过两阶段预训练提高LLM精度、面向大型语言模型N选一最佳采样的推理感知微调、从指令遵循的角度对偏好学习进行系统研究
1、[CL] HREF: Human Response-Guided Evaluation of Instruction Following in Language Models
X Lyu, Y Wang, H Hajishirzi, P Dasigi
[Allen Institute for AI]
HREF:人类响应引导的语言模型指令遵循评估
要点:
-
对自动指令遵循评估的重新评估:本文重新评估了评估大型语言模型 (LLM) 指令遵循能力的现有自动方法,其关注的任务范围比以往的工作更广。这包括与指令微调模型训练更一致的更具代表性的任务分布。 -
人类响应引导的评估:核心发现是,结合人工编写的参考响应可以显著提高自动评估的可靠性。这导致与人工评判员的一致性提高了 3.2%。这种改进是通过在“LLM 作为评判员”的方法中包含人工响应作为附加上下文来实现的。 -
人类响应的正交视角:人工编写的响应与模型生成的响应相比,提供了正交的视角。在判断模型输出时,它们作为附加上下文比作为直接比较参考更有效。令人惊讶的是,即使在人工引导的评估更准确的情况下,LLM 也经常更喜欢模型生成的响应而不是人工编写的响应。 -
HREF 基准:引入了一个新的基准,即人类响应引导的指令遵循评估 (HREF)。它包含 11 个任务类别中的 4258 个样本,采用组合评估设置,为每个类别选择最可靠的方法。HREF 解决了现有基准的局限性,包括易受污染(私有测试集)和对单个任务的关注有限(以任务为中心的设 计)。 -
设计选择分析:本文分析了 HREF 中关键设计选择的影响,包括数据集大小、评判模型(首选 Llama-3.1-70B-Instruct)、基线模型和提示模板。选择 Llama 模型而不是 GPT 模型的理由是成本效益、更低的长度偏差和可重复性。
主旨:解决现有大型语言模型指令遵循能力评估方法的不足,提出了一种新的基于人类响应引导的评估基准 HREF,并对其设计选择进行了深入分析。
创新:提出了一种新的评估方法:将人工编写的参考响应作为附加上下文融入到 LLM-as-a-Judge 的评估方法中,显著提高了自动评估的可靠性,并构建了一个更全面、更可靠的指令遵循能力评估基准 HREF。
贡献:
-
提出了一种新的利用人工响应提高 LLM 指令遵循能力评估可靠性的方法。 -
构建了一个新的、更全面、更可靠的指令遵循能力评估基准 HREF,解决了现有基准的污染和任务关注度有限的问题。 -
对 HREF 的关键设计选择进行了深入分析,为未来的研究提供了宝贵的经验。
提升:HREF 相比现有方法,在与人工判断的一致性方面有了显著提升,最高可达 3.2%。此外,HREF 在任务粒度上提供了更细致的评估结果,能够更好地指导模型的改进。
不足:本文主要关注单轮指令遵循评估,对多轮对话场景的评估能力有限。此外,HREF 基于基线模型进行成对比较,缺乏独立的绝对评分机制。
心得:
-
人工标注数据的重要性:人工编写的参考响应在提高自动评估的可靠性方面发挥了关键作用,这凸显了高质量人工标注数据的重要性。 -
LLM 评估方法的局限性:LLM 作为评判员的方法存在偏差,例如长度偏差,需要进一步改进。 -
任务粒度的重要性:对不同任务类型的单独评估能够提供更细致的模型性能分析,指导模型的改进方向。
一句话总结: 本文提出了一种新的基于人类响应引导的指令遵循评估方法,并构建了 HREF 基准,有效提高了评估的可靠性并解决了现有基准的局限性,其核心发现是人类响应作为辅助上下文而非直接比较基准更能提升 LLM 评估的准确性,这为大型语言模型的评估和改进提供了新的思路。
Evaluating the capability of Large Language Models (LLMs) in following instructions has heavily relied on a powerful LLM as the judge, introducing unresolved biases that deviate the judgments from human judges. In this work, we reevaluate various choices for automatic evaluation on a wide range of instruction-following tasks. We experiment with methods that leverage human-written responses and observe that they enhance the reliability of automatic evaluations across a wide range of tasks, resulting in up to a 3.2% improvement in agreement with human judges. We also discovered that human-written responses offer an orthogonal perspective to model-generated responses in following instructions and should be used as an additional context when comparing model responses. Based on these observations, we develop a new evaluation benchmark, Human Response-Guided Evaluation of Instruction Following (HREF), comprising 4,258 samples across 11 task categories with a composite evaluation setup, employing a composite evaluation setup that selects the most reliable method for each category. In addition to providing reliable evaluation, HREF emphasizes individual task performance and is free from contamination. Finally, we study the impact of key design choices in HREF, including the size of the evaluation set, the judge model, the baseline model, and the prompt template. We host a live leaderboard that evaluates LLMs on the private evaluation set of HREF12.
https://arxiv.org/abs/2412.15524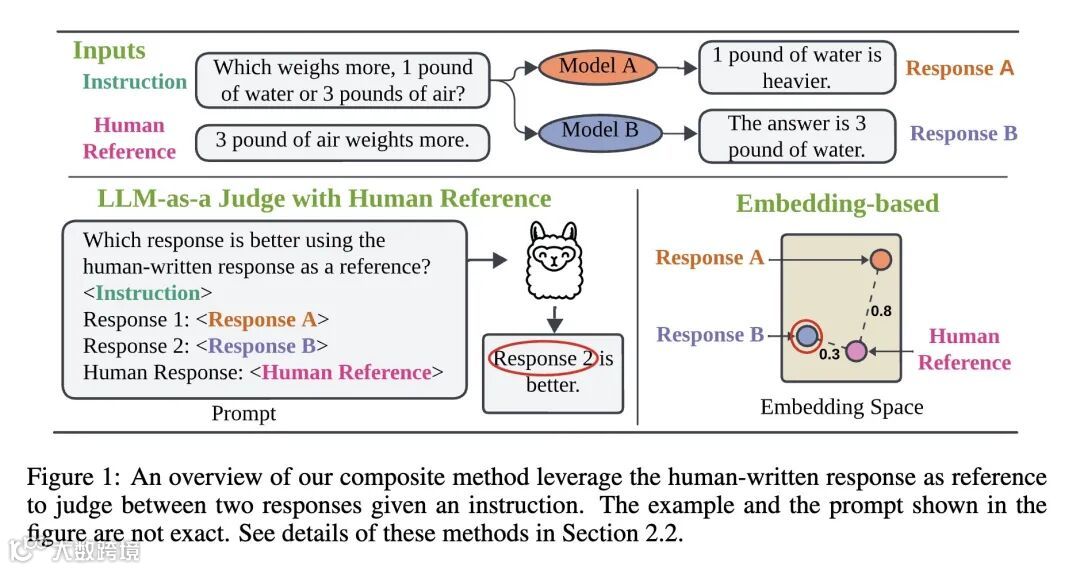


2、[CV] Personalized Representation from Personalized Generation
S Sundaram, J Chae, Y Tian, S Beery, P Isola
[MIT & OpenAI]
从个性化生成到个性化表示
要点:
-
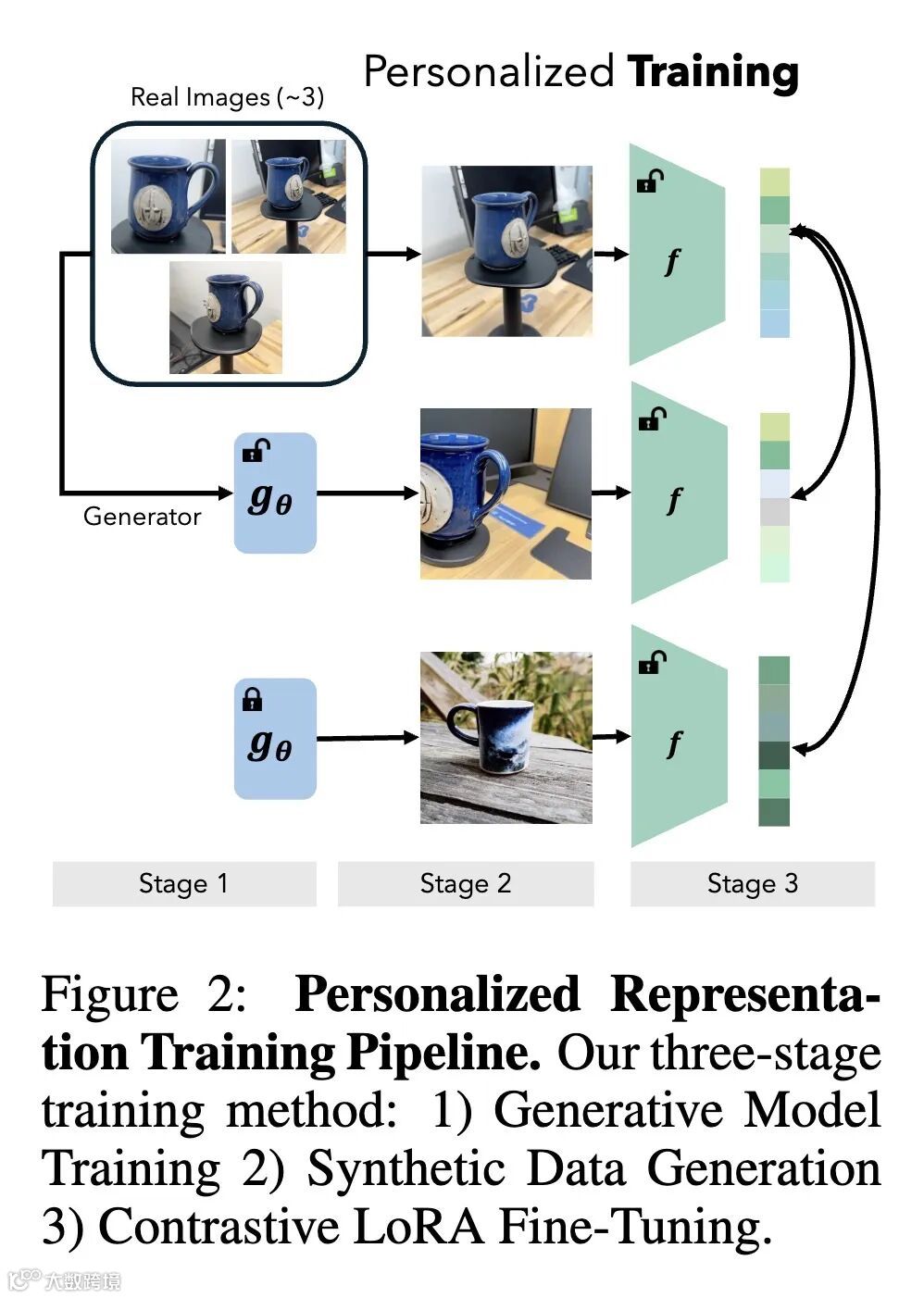
仅使用三张真实图像和从文本到图像(T2I)模型生成的合成数据训练的个性化表征,在各种数据集、骨干网络和下游任务(分类、检索、检测、分割)上显著优于预训练模型。这挑战了强个性化视觉性能需要大型数据集的假设。 -
本文引入了一个新的数据集PODS(个人物体辨识套件),用于评估在各种分布偏移(姿态、干扰物、两者兼有)下的个性化表征。这比现有数据集提供了更丰富的评估,并为不同方法的鲁棒性提供了宝贵的见解。 -
本文探讨了不同的T2I生成方法(DreamBooth、剪切粘贴)及其超参数(无分类器引导、LLM生成的提示)对学习到的个性化表征质量的影响。研究结果揭示了生成数据中保真度和多样性之间微妙的相互作用,突出了为获得最佳性能而平衡这些因素的重要性。不同的生成器表现出独特的偏差——DreamBooth擅长姿态泛化,但难以处理细粒度的细节,而剪切粘贴保持了保真度,但缺乏姿态多样性。 -
本文证明,即使真实数据有限,结合额外的资源(分割掩码、互联网数据)也可以显著提高个性化表征学习,为计算成本较高的T2I模型提供了具有成本效益的替代方案。然而,本文还表明,即使有更多真实数据可用,合成数据增强仍然是有益的。
主旨:研究了如何利用少量真实图像和文本到图像生成模型来学习用于各种下游任务的个性化视觉表征,并探讨了影响个性化表征学习的关键因素。
创新:提出了一种利用个性化合成数据进行个性化表征学习的新方法,该方法结合了对比学习和文本到图像生成模型,并引入了一个新的评估套件PODS,用于评估个性化表征在不同分布偏移下的鲁棒性。
贡献:
-
提出了一种利用少量真实图像和合成数据学习个性化视觉表征的新方法。 -
引入了一个新的数据集PODS,用于评估个性化表征的性能和鲁棒性。 -
系统地研究了不同T2I生成方法和超参数对个性化表征学习的影响。 -
证明了合成数据增强即使在有更多真实数据的情况下仍然是有益的。
提升:提出的方法在各种数据集、骨干网络和下游任务上,显著提高了个性化视觉任务的性能,特别是分类、检索等全局任务和检测、分割等局部任务。
不足:
-
T2I模型的计算成本较高,限制了该方法的应用范围。 -
合成数据可能继承T2I模型的偏差和局限性,影响个性化表征的质量。 -
部分实验结果表明,在某些情况下,合成数据方法的提升幅度有限,尤其是在数据量增加后。
心得:
-
少量数据学习的潜力: 本文证明了利用合成数据和对比学习,即使只有少量真实数据,也能学习到性能强大的个性化表征,这为数据稀缺的个性化视觉任务提供了新的思路。 -
数据多样性和保真度的平衡: 生成数据的质量对个性化表征学习至关重要,需要在多样性和保真度之间取得平衡,才能获得最佳性能。不同生成方法有其自身的优缺点,需要根据具体任务选择合适的生成方法。 -
资源利用的策略: 本文探讨了如何利用额外的资源(如分割掩码、互联网数据)来提高个性化表征学习的效率和性能,为用户提供了多种选择,以平衡计算成本和性能。
一句话总结: 本文提出了一种利用少量真实图像和文本到图像生成模型,结合对比学习训练个性化视觉表征的新方法,并通过新数据集PODS验证了其在各种下游任务上的有效性和鲁棒性,同时揭示了合成数据多样性和保真度对性能的影响,以及利用额外资源提高效率的策略。
Modern vision models excel at general purpose downstream tasks. It is unclear, however, how they may be used for personalized vision tasks, which are both fine-grained and data-scarce. Recent works have successfully applied synthetic data to general-purpose representation learning, while advances in T2I diffusion models have enabled the generation of personalized images from just a few real examples. Here, we explore a potential connection between these ideas, and formalize the challenge of using personalized synthetic data to learn personalized representations, which encode knowledge about an object of interest and may be flexibly applied to any downstream task relating to the target object. We introduce an evaluation suite for this challenge, including reformulations of two existing datasets and a novel dataset explicitly constructed for this purpose, and propose a contrastive learning approach that makes creative use of image generators. We show that our method improves personalized representation learning for diverse downstream tasks, from recognition to segmentation, and analyze characteristics of image generation approaches that are key to this gain.
https://arxiv.org/abs/2412.16156

3、[CL] Maximize Your Data's Potential: Enhancing LLM Accuracy with Two-Phase Pretraining
S Feng, S Prabhumoye, K Kong, D Su...
[NVIDIA & Stanford University & Boston University]
最大限度发挥数据潜力:通过两阶段预训练提高LLM精度
要点:
-
两阶段预训练: 论文提出了一种用于大型语言模型(LLM)的两阶段预训练方法。第一阶段侧重于多样化的数据(主要是网络爬取数据),第二阶段则强调高质量的数据(数学、代码、维基百科等)。这种反直觉的方法,即优先使用多样化数据,带来了显著的性能提升。 -
数据质量和轮数: 研究系统地考察了数据质量和每个数据源在训练过程中看到的轮数的影响。结果突出了平衡数据多样性和质量以及仔细管理轮数(尤其对于高质量数据,避免过拟合)的重要性。 -
下采样以提高可扩展性: 作者证明了在下采样数据(1万亿个token)以原型设计最佳数据混合方法的有效性,然后可以有效地扩展到更大的数据集(15万亿个token)和模型大小(250亿参数)。这大大降低了实验的计算成本。 -
显著的精度提升: 两阶段方法始终比基线方法(自然分布和随机排序)具有显著的优势(平均分别提高了3.4%和17%),展示了所提出方法的有效性。在涉及代码和数学的任务中,改进尤为明显。 -
详细的消融研究: 论文包含了关于数据质量(特别是网络爬取数据)、不同数据源的轮数以及第二阶段最佳持续时间的广泛消融研究。这些研究为从业者提供了可操作的指导。
主旨:研究了如何优化大型语言模型的预训练数据选择、混合和排序策略,以提高模型的准确性。
创新:提出了一种两阶段预训练方法,第一阶段使用多样化数据,第二阶段使用高质量数据,并通过下采样数据进行小规模实验,从而高效地探索最佳数据混合策略,最终将该策略扩展到更大规模的数据集和模型。
贡献:
-
提出并大规模评估了用于LLM的两阶段预训练方法,并提供了可操作的策略,使LLM预训练更有效。 -
通过基于质量和轮数的数据分析,提高了对数据选择和混合的理解,包括网络爬取数据。 -
证明了使用1万亿token下采样数据进行混合策略设计,并将其扩展到15万亿token和250亿参数模型的可扩展性。
提升:相比于基线方法(自然分布和随机排序),该方法在多个下游任务上的平均准确率分别提高了13.2%和3.4%。在代码和数学等特定任务上的提升更为显著。
不足:
-
模型和评估基准的范围有限,可以扩展到更多架构和更广泛的下游任务。 -
没有探索多阶段预训练以及不同阶段顺序的影响。 -
大规模实验需要大量的计算资源,存在环境问题。
心得:
-
数据多样性和质量的平衡至关重要: 预训练初期注重数据多样性,后期再引入高质量数据,这种策略能够有效提升模型性能。这颠覆了以往单纯追求高质量数据的传统观念。 -
下采样策略的有效性: 利用下采样数据进行小规模实验,可以有效降低计算成本,并找到可扩展的最佳数据混合策略。这为大型模型的预训练提供了高效的实验方法。 -
数据轮数的精细控制: 对不同质量的数据,需要控制其在训练过程中的轮数,避免过拟合。高质量数据并非越多越好,需要找到一个最佳的平衡点。
一句话总结: 本文提出了一种反直觉的两阶段大型语言模型预训练方法,通过先使用多样化数据再使用高质量数据,并结合下采样策略和对数据轮数的精细控制,显著提升了模型在下游任务上的准确率,尤其在代码和数学领域。
Pretraining large language models effectively requires strategic data selection, blending and ordering. However, key details about data mixtures especially their scalability to longer token horizons and larger model sizes remain underexplored due to limited disclosure by model developers. To address this, we formalize the concept of two-phase pretraining and conduct an extensive systematic study on how to select and mix data to maximize model accuracies for the two phases. Our findings illustrate that a two-phase approach for pretraining outperforms random data ordering and natural distribution of tokens by 3.4% and 17% on average accuracies. We provide in-depth guidance on crafting optimal blends based on quality of the data source and the number of epochs to be seen. We propose to design blends using downsampled data at a smaller scale of 1T tokens and then demonstrate effective scaling of our approach to larger token horizon of 15T tokens and larger model size of 25B model size. These insights provide a series of steps practitioners can follow to design and scale their data blends.
https://arxiv.org/abs/2412.15285


4、[CL] Inference-Aware Fine-Tuning for Best-of-N Sampling in Large Language Models
Y Chow, G Tennenholtz, I Gur, V Zhuang...
[Google DeepMind & Google Research]
面向大型语言模型N选一最佳采样的推理感知微调
要点:
-
推理感知微调: 一种新的范式,它在训练过程中直接优化推理策略的性能,这与传统方法(将训练和推理解耦)不同。 -
最佳N选一 (BoN) 策略: 本文重点研究BoN策略,该策略对大型语言模型生成的多个候选答案进行排序,并选择最佳答案。结果表明,这比传统的单一答案生成方法更有效。 -
不可微的argmax运算符: BoN中的argmax运算符对标准基于梯度的优化提出了挑战。本文介绍了克服这一挑战的新型模仿学习和强化学习 (RL) 方法。 -
隐式元策略: BoN感知模型隐式地学习了一种元策略,该策略平衡了探索(多样化的答案)和利用(最佳答案),这让人联想到强化学习中的探索-利用权衡。 -
协同缩放行为: 本文实证地证明了BoN中最佳样本数 (N) 和温度 (T) 之间的协同缩放关系,揭示了探索和利用之间的权衡。较高的T需要较高的N才能获得最佳性能。 -
性能提升: BoN感知微调显著提高了基准数据集(Hendrycks MATH、HumanEval)上的BoN和pass@N性能,优于基线方法。例如,Hendrycks MATH上的Bo32性能从26.8%提高到30.8%,pass@32从60.0%提高到67.0%。 -
变分逼近和新算法: 本文使用BoN分布的变分逼近来使优化问题可微,从而为监督学习和强化学习设置开发了新算法。 -
二元奖励简化: 对于二元奖励场景(在推理任务中很常见),本文推导出了更高效的算法(BoN-RLB和BoN-RLB(P))。 -
泛化到未见过的基准和温度: 性能提升很好地泛化到未见过的基准和不同的温度,证明了其鲁棒性。
主旨:研究如何通过推理感知微调来提高大型语言模型在最佳N选一 (BoN) 推理策略下的性能。
创新:提出了推理感知微调的范式,并针对BoN策略,设计了基于模仿学习和强化学习的BoN感知微调算法,克服了BoN中不可微的argmax操作符的挑战。 此外,文章还实证分析了BoN策略中样本数量和温度的协同缩放关系。
贡献:提出了推理感知微调的范式,并针对BoN推理策略设计了有效的模仿学习和强化学习算法,显著提高了大型语言模型在BoN策略下的性能,并揭示了BoN策略中样本数量和温度的协同缩放关系。
提升:提出的方法在Hendrycks MATH数据集上将Bo32性能从26.8%提升到30.8%,pass@32从60.0%提升到67.0%;在HumanEval数据集上将pass@16性能从61.6%提升到67.1%。 这些提升都显著优于基线方法。
不足:主要关注BoN策略,未来可以扩展到更复杂的推理算法。 此外,部分算法在样本数量较大时可能存在效率和稳定性问题,需要进一步改进。 对Verifier的依赖也可能限制了方法的普适性。
心得:
-
推理感知的重要性: 传统的训练方法忽略了推理过程,导致模型训练与实际应用脱节。推理感知微调强调了将推理策略融入训练过程的重要性,从而显著提高模型性能。 -
探索-利用的平衡: BoN策略以及本文提出的算法,巧妙地平衡了探索和利用,这为解决复杂问题提供了新的思路。 这启示我们,在设计算法时,需要仔细考虑探索和利用之间的权衡。 -
变分方法的应用: 本文巧妙地利用变分方法处理了BoN中不可微的argmax操作符,这为解决其他类似问题提供了借鉴。
一句话总结: 本文提出了一种新的推理感知微调范式,通过将最佳N选一策略融入训练过程,显著提升了大型语言模型的性能,并揭示了样本数量和温度之间的协同缩放关系,为提高大型语言模型的推理能力提供了新的方向。
Recent studies have indicated that effectively utilizing inference-time compute is crucial for attaining better performance from large language models (LLMs). In this work, we propose a novel inference-aware fine-tuning paradigm, in which the model is fine-tuned in a manner that directly optimizes the performance of the inference-time strategy. We study this paradigm using the simple yet effective Best-of-N (BoN) inference strategy, in which a verifier selects the best out of a set of LLM-generated responses. We devise the first imitation learning and reinforcement learning~(RL) methods for BoN-aware fine-tuning, overcoming the challenging, non-differentiable argmax operator within BoN. We empirically demonstrate that our BoN-aware models implicitly learn a meta-strategy that interleaves best responses with more diverse responses that might be better suited to a test-time input -- a process reminiscent of the exploration-exploitation trade-off in RL. Our experiments demonstrate the effectiveness of BoN-aware fine-tuning in terms of improved performance and inference-time compute. In particular, we show that our methods improve the Bo32 performance of Gemma 2B on Hendrycks MATH from 26.8% to 30.8%, and pass@32 from 60.0% to 67.0%, as well as the pass@16 on HumanEval from 61.6% to 67.1%.
https://arxiv.org/abs/2412.15287


5、[CL] A Systematic Examination of Preference Learning through the Lens of Instruction-Following
J Kim, A Goyal, A Zhang, B Xiong...
[Meta]
从指令遵循的角度对偏好学习进行系统研究
要点:
-
关于共享前缀的反直觉发现:蒙特卡洛树搜索 (MCTS) 生成具有共享前缀的偏好对,始终优于不具有共享前缀的拒绝采样 (RS),尽管性能差异很小。这表明偏好对中的结构一致性可以微妙地提高模型的稳定性,尤其是在难以量化响应正确性时。 -
高对比度与低对比度偏好对:虽然高对比度对通常产生更好的结果,但高对比度和低对比度对的混合通常能提供最佳性能。这平衡了多样性和学习效率。选择的和拒绝的响应之间的 相对 对比比它们的绝对正确性更重要。 -
最佳提示难度:与过于具有挑战性的提示相比,在中等难度的提示上进行训练会导致在各种任务(甚至包括更复杂的任务)中获得更好的泛化能力。过于困难的提示会降低偏好对的产出率并阻碍学习效率。 -
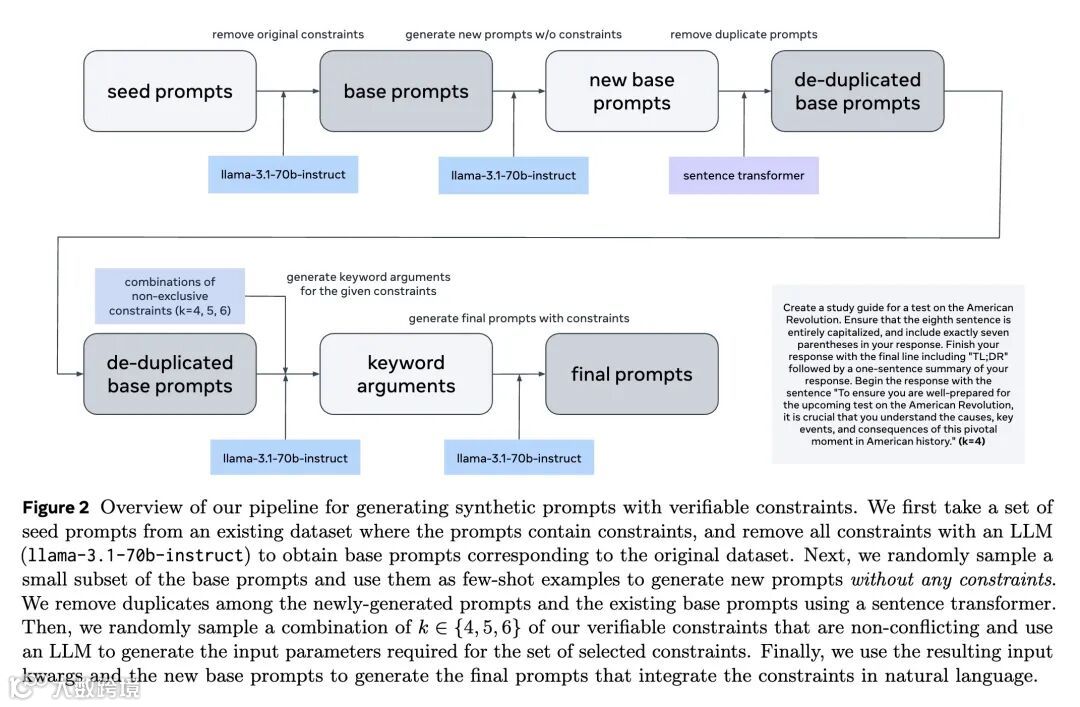
新的合成数据生成流程:本文介绍了一种新的流程,用于生成具有可验证约束的合成指令遵循提示,从而能够进行细粒度和自动化的质量评估。这使得对偏好学习属性的系统研究成为可能。 -
对偏好学习的系统研究:本研究系统地调查了自动整理的偏好数据集的不同属性(共享前缀、响应的对比度/质量、提示难度)如何影响指令遵循任务中的模型性能。
主旨:研究了不同属性的自动生成的偏好数据集如何影响大型语言模型在指令遵循任务中的性能。
创新:提出了一种新的合成数据生成流程,用于生成具有可验证约束的指令遵循提示,并系统地研究了共享前缀、响应对比度/质量和提示难度这三个关键维度对模型性能的影响。 使用了MCTS方法生成具有共享前缀的偏好对,这在以往研究中较少见。
贡献:对偏好学习进行了系统性的研究,揭示了偏好数据集的几个关键属性对模型性能的影响,为优化偏好数据整理提供了可操作的见解,并提出了一个可扩展且有效的框架来增强LLM的训练和对齐。 特别是,对共享前缀、对比度和难度之间关系的发现具有重要意义。
提升:与基线模型相比,本文提出的方法在IFEval以及更具挑战性的评估集上都取得了性能提升,具体提升幅度在表格中有所体现,并且MCTS方法在稳定性方面优于RS方法。
不足:本文主要关注指令遵循任务,其结论可能无法直接推广到其他类型的任务。 混合高低对比度对的最佳比例并未给出明确结论,需要进一步研究。 MCTS方法计算成本较高。
心得:
-
数据质量对模型性能至关重要,需要仔细设计和优化偏好数据集。 -
并非所有方法都适用所有场景,需要根据具体任务选择合适的偏好数据生成和整理方法。 -
在偏好学习中,需要平衡多样性和学习效率,找到最佳的提示难度。
一句话总结: 该论文通过构建新的合成数据生成流程并系统性地研究共享前缀、响应对比度以及提示难度对模型性能的影响,为大型语言模型的偏好学习提供了宝贵的见解,特别是发现中等难度提示和混合对比度偏好对能带来更好的泛化能力,以及共享前缀能提升模型稳定性,这些结论具有反直觉性和重要的启发意义。
Preference learning is a widely adopted post-training technique that aligns large language models (LLMs) to human preferences and improves specific downstream task capabilities. In this work we systematically investigate how specific attributes of preference datasets affect the alignment and downstream performance of LLMs in instruction-following tasks. We use a novel synthetic data generation pipeline to generate 48,000 unique instruction-following prompts with combinations of 23 verifiable constraints that enable fine-grained and automated quality assessments of model responses. With our synthetic prompts, we use two preference dataset curation methods - rejection sampling (RS) and Monte Carlo Tree Search (MCTS) - to obtain pairs of (chosen, rejected) responses. Then, we perform experiments investigating the effects of (1) the presence of shared prefixes between the chosen and rejected responses, (2) the contrast and quality of the chosen, rejected responses and (3) the complexity of the training prompts. Our experiments reveal that shared prefixes in preference pairs, as generated by MCTS, provide marginal but consistent improvements and greater stability across challenging training configurations. High-contrast preference pairs generally outperform low-contrast pairs; however, combining both often yields the best performance by balancing diversity and learning efficiency. Additionally, training on prompts of moderate difficulty leads to better generalization across tasks, even for more complex evaluation scenarios, compared to overly challenging prompts. Our findings provide actionable insights into optimizing preference data curation for instruction-following tasks, offering a scalable and effective framework for enhancing LLM training and alignment.
https://arxiv.org/abs/2412.15282

另外几篇值得关注的论文
[LG] Formal Mathematical Reasoning: A New Frontier in AI
https://arxiv.org/abs/2412.16075
-
非形式化AI4Math方法的局限性:当前AI数学(AI4Math)主要依赖于在大规模非形式化数学数据(教科书、论文等)上训练的大型语言模型(LLM)。这种方法面临着高级数学数据稀缺以及验证LLM生成解(特别是证明)正确性的难题。LLM容易产生看似合理但错误的推理步骤,其成功主要局限于高中水平的数学。 -
形式化数学推理的潜力:本文倡导转向基于形式化系统的形式化数学推理,例如证明辅助工具(Lean、Coq、Isabelle)。这些系统允许对推理进行严格验证并提供自动反馈,从而减轻数据稀缺和幻觉问题。 -
AI形式化推理的最新进展:在自动形式化(将非形式化数学转换为形式化系统)和神经定理证明(生成形式化证明)方面取得了显著进展。LLMs在加速这一进展方面发挥了关键作用,特别是通过合成数据生成和上下文学习来缓解数据稀缺问题。AlphaProof和AlphaGeometry等例子证明了这种方法的成功。 -
开放性挑战和未来方向:本文指出了几个开放性挑战,包括形式化数据稀缺、改进自动形式化和定理证明算法(特别是扩展搜索)的需要,以及开发更好的AI工具来辅助人类数学家的需求。它强调需要更好的评估指标和基准,特别是对于猜想等更高级的能力。 -
里程碑和成功衡量:本文提出一个框架来对AI在形式化数学推理中的能力进行分类,定义了定理证明、经过验证的自然语言推理、自动形式化和猜想等各个领域的能力级别。它强调需要新的基准和评估方法来衡量这些领域的进展,特别是对于更高级的能力。 -
形式化和非形式化方法的互补性:本文强调AI4Math的形式化和非形式化方法是互补的,而不是相互排斥的。未来的模型可以结合这两种方法来实现更强大和通用的推理。
主旨:探讨了将形式化数学推理应用于AI数学领域,并论证了其相较于现有非形式化方法的优势和潜力。
心得:本文最大的启发在于其对AI4Math领域发展方向的战略性思考,以及对形式化方法重要性的强调。 它提醒我们,仅仅依靠大规模数据和参数规模的提升并不能解决AI4Math领域的所有问题,需要探索新的方法和技术路线。形式化方法的引入,为解决数据稀缺和推理正确性验证等难题提供了新的思路。
一句话总结: 本文倡导将形式化数学推理融入AI数学领域,认为其能克服现有方法在高级数学问题求解和推理正确性验证方面的局限性,并提出了衡量该领域未来进展的里程碑式框架。

