
字节跳动AI Lab揭秘文本生成技术:从深度隐变量模型到多语言翻译实践[k]
李磊详解火山引擎在机器写作、对话生成与多语言翻译中的核心技术突破与落地应用[k]

人工智能正深刻改变信息的创作、获取与分发方式,但高质量内容生成与公平的信息获取仍面临挑战。本文整理自字节跳动AI Lab总监李磊在火山引擎智能增长技术专场的演讲,系统介绍了文本生成的技术进展、核心难点及火山引擎的实践经验[k]。
随着新媒体平台发展,AI显著提升了内容创作效率,个性化推荐则优化了信息分发。其中,文本生成技术在机器翻译、自动写作、对话系统和问答等领域广泛应用。MIT研究显示,机器翻译技术已推动全球国际贸易量增长10%,相当于缩短了国家间25%的“距离”[1]。
字节跳动自主研发的火山翻译平台已服务50多个内外部客户,支持超50种语言互译。此外,公司推出的Xiaomingbot自动写稿系统自2016年上线以来,累计生成60万篇文章,覆盖17项体育赛事,支持6种语言,在自媒体平台拥有15万粉丝[k]。
Xiaomingbot通过整合比赛数据(如球员布阵、进球信息)和计算机视觉技术,识别球员号码、运动轨迹、关键动作等场景,再经文本生成算法自动撰写新闻[2]。
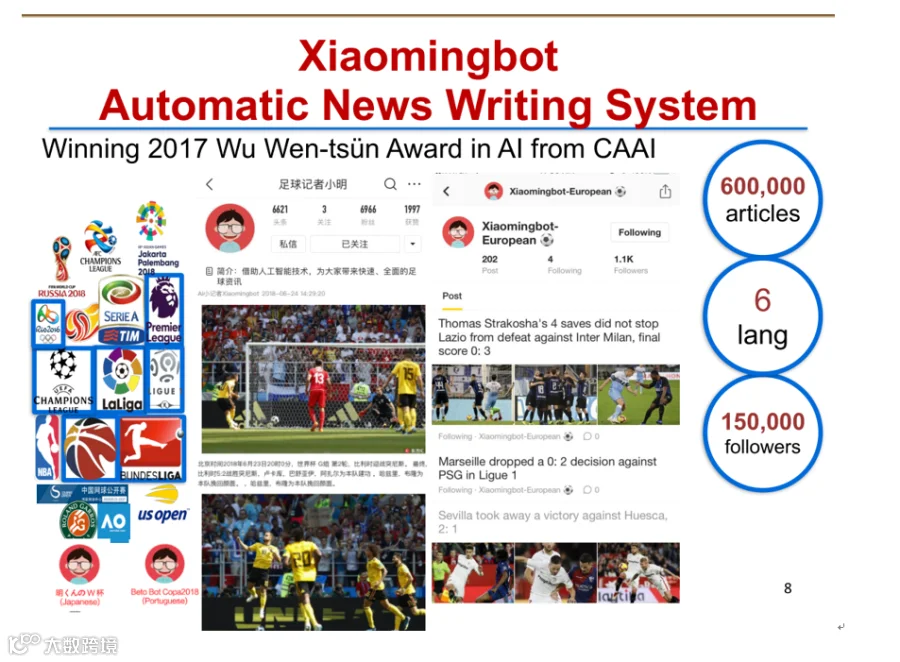
在斯诺克赛事中,系统通过分析球路轨迹与球员动作,结合机器学习预测击球策略与落袋位置,生成专业解说,帮助非专业观众理解比赛进程[3]。

本次分享涵盖五大主题:序列生成问题的挑战、深度隐变量模型、受限文本生成算法、双语能力建模与多语言翻译系统mRASP[k]。

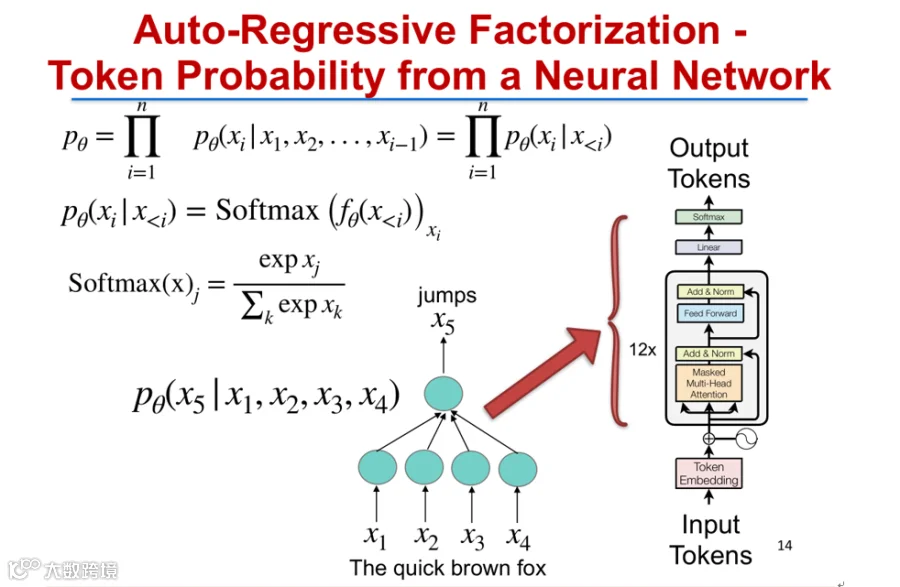
自然语言处理的核心是对句子序列建模,即计算任意长度L句子的联合概率。主流方法为自回归语言模型(Auto-Regressive Language Model),将联合概率分解为前序词条件概率的乘积。自2017年起,Transformer模型采用多头注意力机制对条件概率建模,成为主流架构[4]。

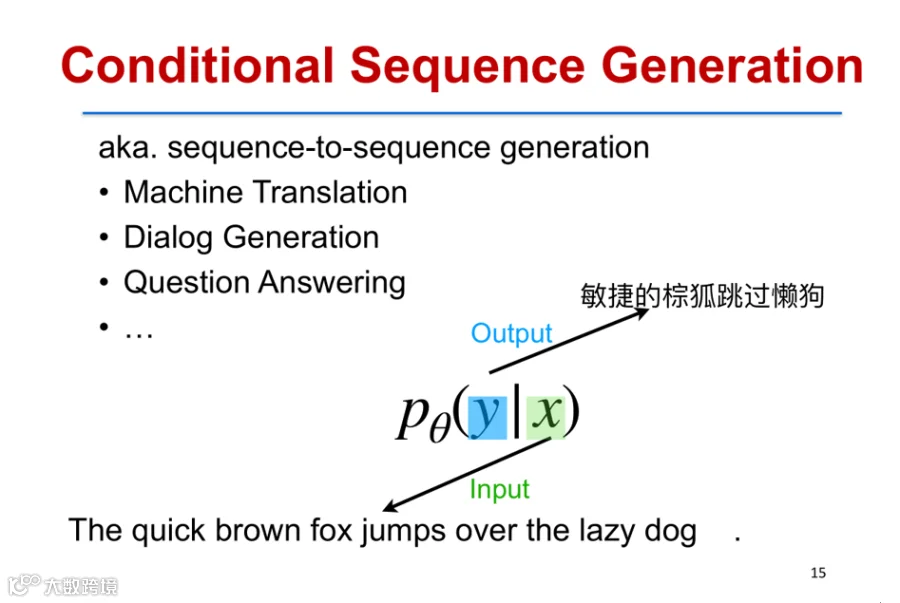
在机器翻译、对话生成等任务中,需建模输入序列X到输出序列Y的条件概率P(Y|X),同样可基于Transformer实现[k]。

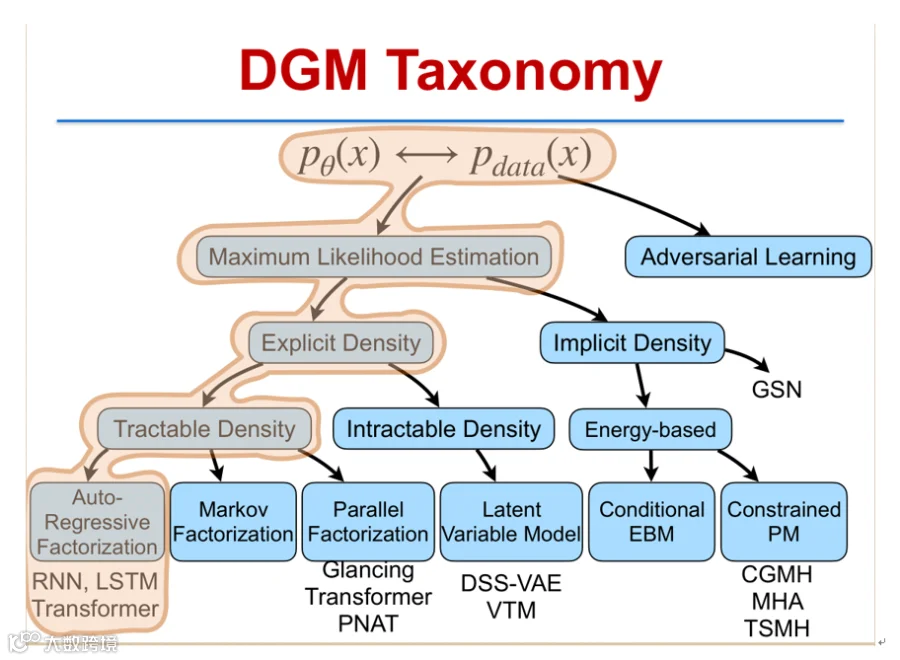
深度生成模型按密度建模方式可分为显式密度与隐式密度两类。显式密度模型包括自回归分解(如Transformer)[4]、马尔科夫分解和并行分解(如GLAT)。另一类为不可高效计算的显式密度模型,即隐变量模型(Latent Variable Model),如DSSVAE、VTM等,具备更强的表示能力[k]。
对于无显式概率公式的隐式密度模型,通常通过能量函数建模,如条件能量模型或受限概率模型。本次将重点介绍后者如何实现高效文本生成,涵盖CGMH、MHA、TSMH等算法。对抗学习因超出最大似然框架,不在本次讨论范围[k]。

本部分聚焦两类研究:从文本中学习可解释的深层隐含表示,以及学习解耦表示以提升生成质量[k]。
以对话系统为例,不同语句对应不同意图(如提醒、信息查询),目标是通过生成模型自动学习这些语义意图,实现基于意图的可控回复生成[k]。
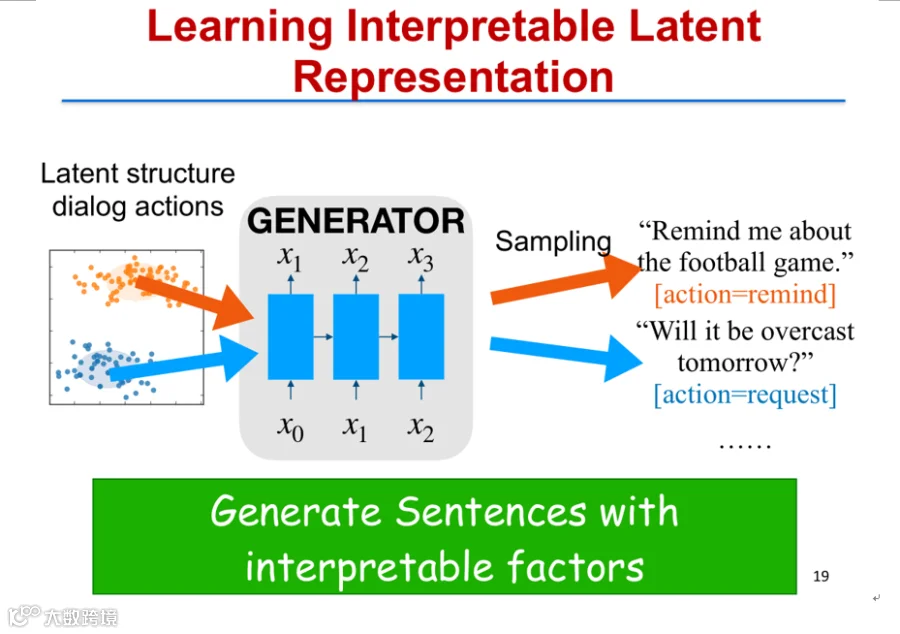
传统变分自编码器(VAE)虽可学习隐表示,但其低维可视化常呈现混合状态,缺乏明确聚类,难以解释[k]。
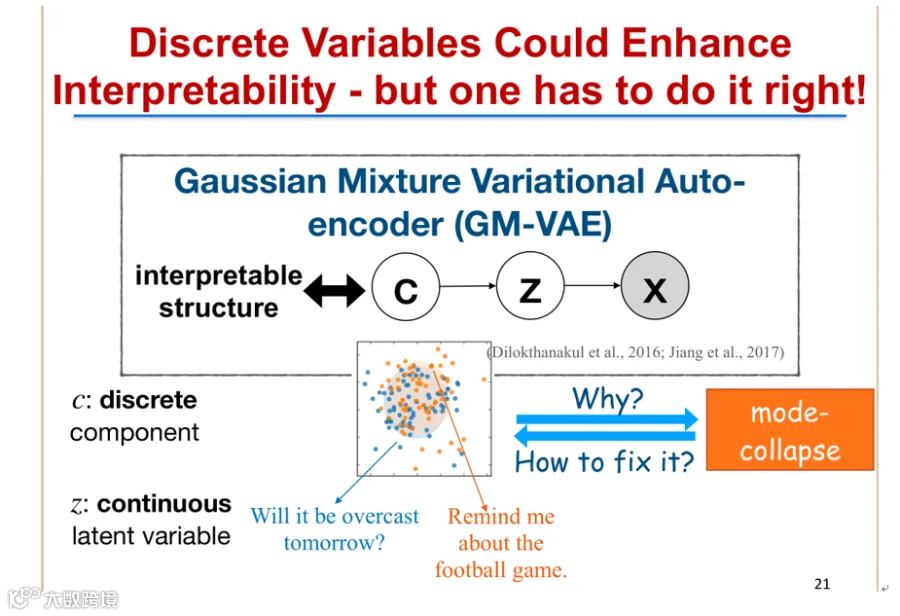
为此,可在隐变量Z基础上引入离散先验变量C,使Z服从高斯混合分布,不同C对应不同语义聚类,提升可解释性[k]。
然而,实际训练中易出现“模式坍缩”(mode collapse),导致隐空间表示仍混合不清[k]。
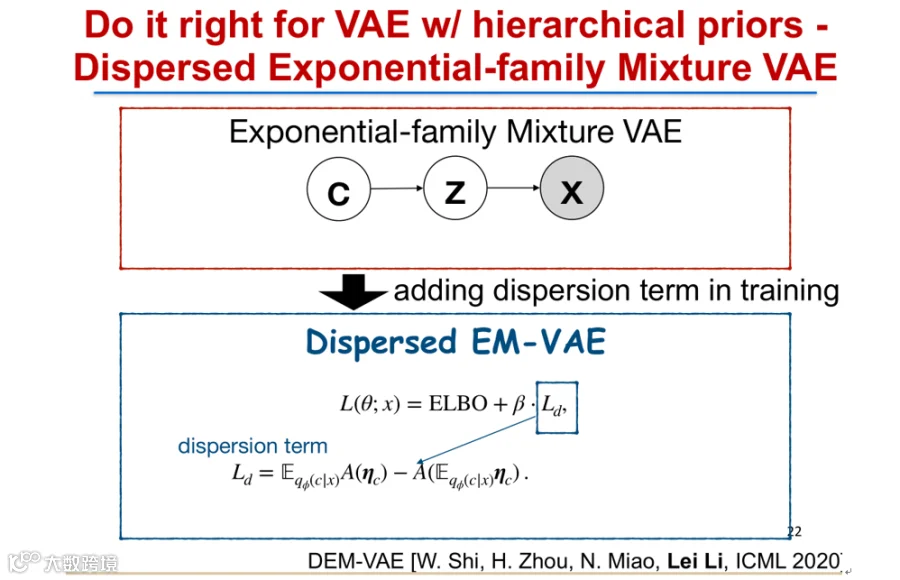
字节跳动在ICML 2020提出的DEMVAE工作解决了该问题[5]。该模型将隐变量扩展为指数族混合分布,并在变分下界中引入“离散项”(dispersion term)作为惩罚机制,有效防止模式坍缩[k]。

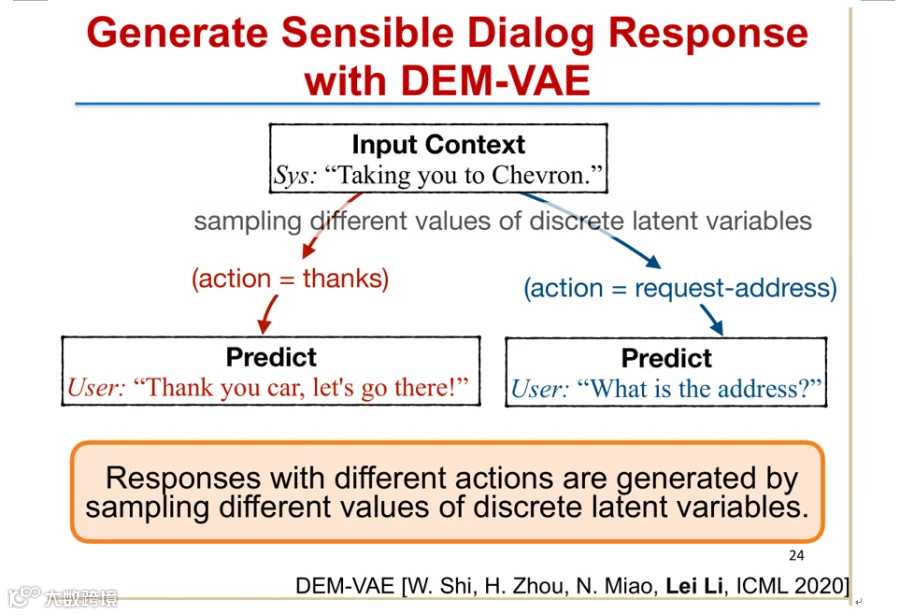
实验表明,DEMVAE能准确识别对话意图(如问路、问天气),并实现基于意图的可控回复生成,显著提升对话系统的灵活性与可解释性[k]。
在数据到文本生成(Data-to-Text Generation)任务中,传统方法依赖人工模板,效率低且多样性差。为此,团队提出变分模板机(Variational Template Machine, VTM),自动从语料中学习无限模板[k]。
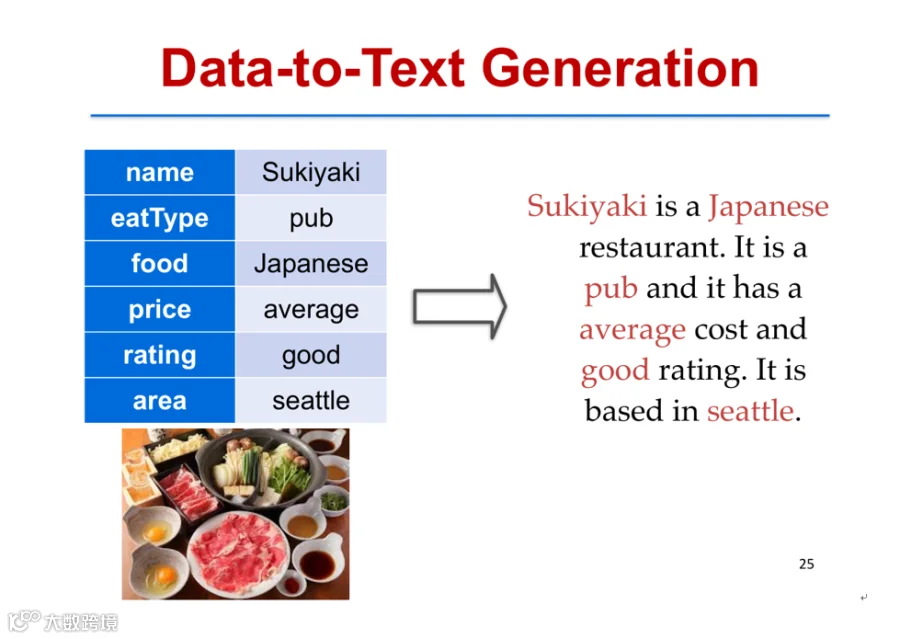
VTM引入两个隐变量:内容变量C(来自输入数据)和模板变量Z(来自先验分布),二者结合后通过神经网络(如Transformer)生成文本[k]。
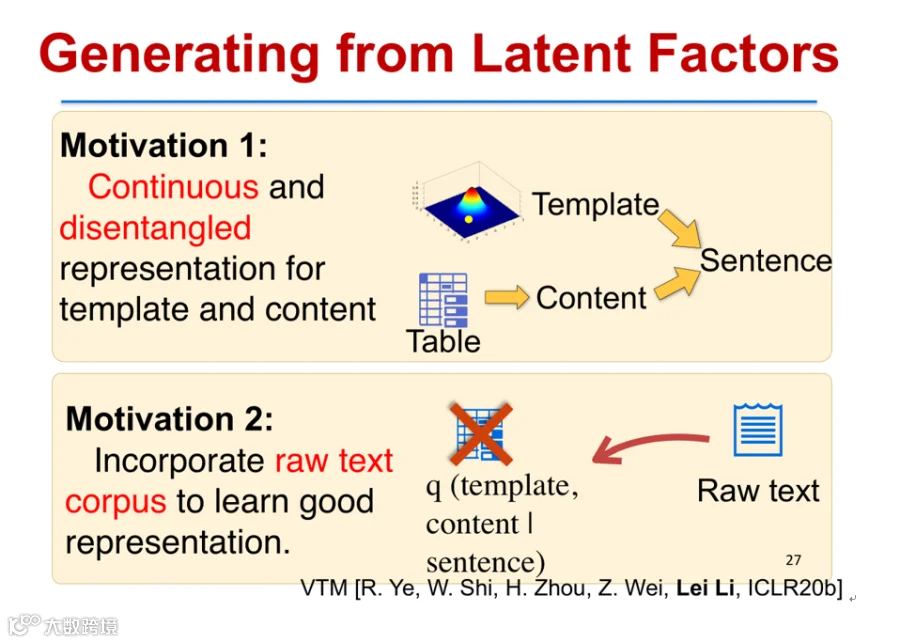
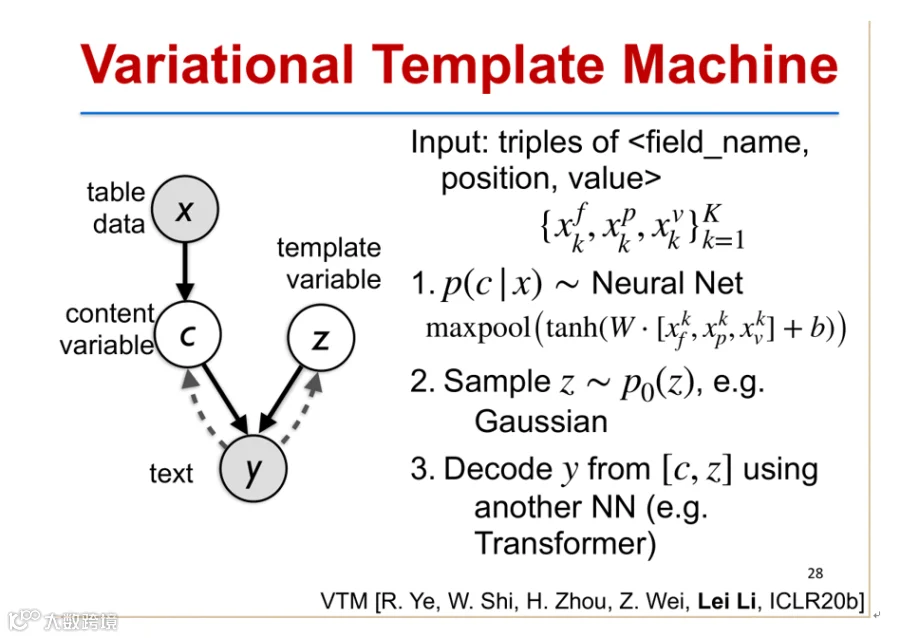
VTM的独特优势在于可同时利用成对数据(表格-文本)和原始文本进行训练,通过反向推断生成伪平行语料,提升模型性能[6]。

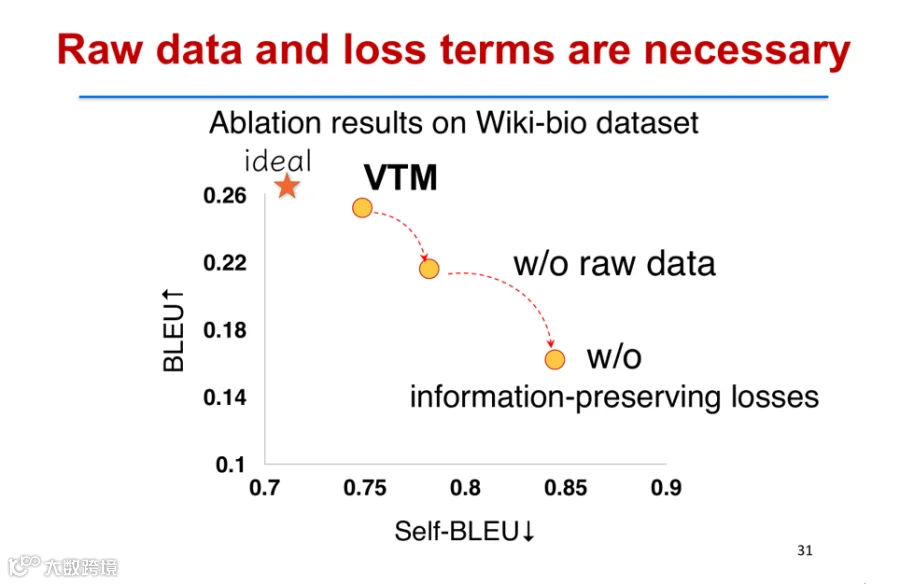
在WIKI Data与SPNLG数据集上的实验表明,VTM在BLEU Score(生成质量)和Self-BLEU(多样性)两个指标上均优于现有方法,位于理想区域(高生成质量、低重复性)[k]。
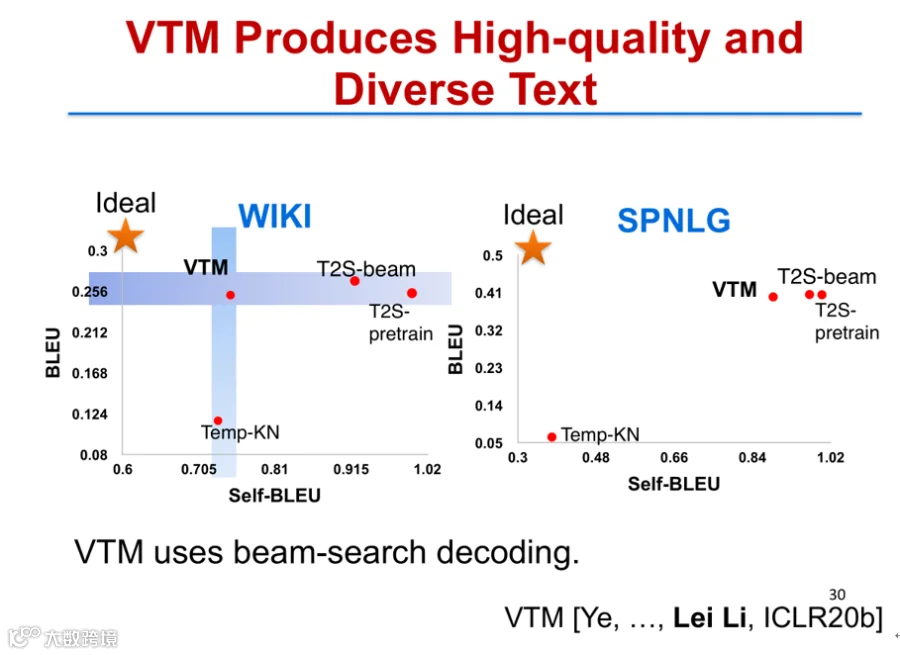
消融实验验证了原始文本数据与关键训练目标的重要性:若仅用成对数据训练,模型性能与多样性均会下降[k]。
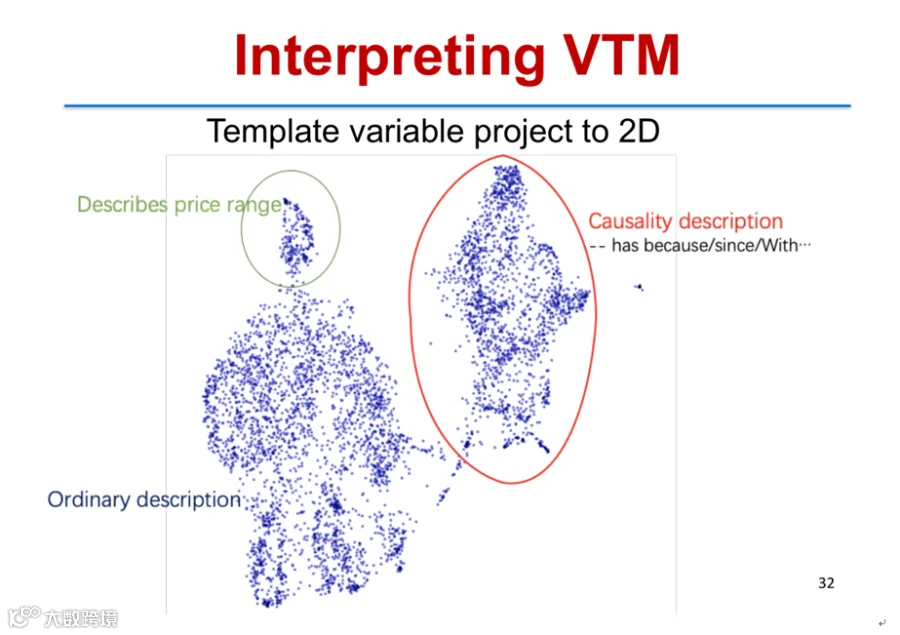
进一步分析发现,模板变量Z在二维空间中形成语义聚类(如因果表达类),证明模型能自动发现语言结构[k]。
通过采样不同模板,VTM可生成风格、长度各异的高质量描述,适用于用户画像转简历等场景[k]。

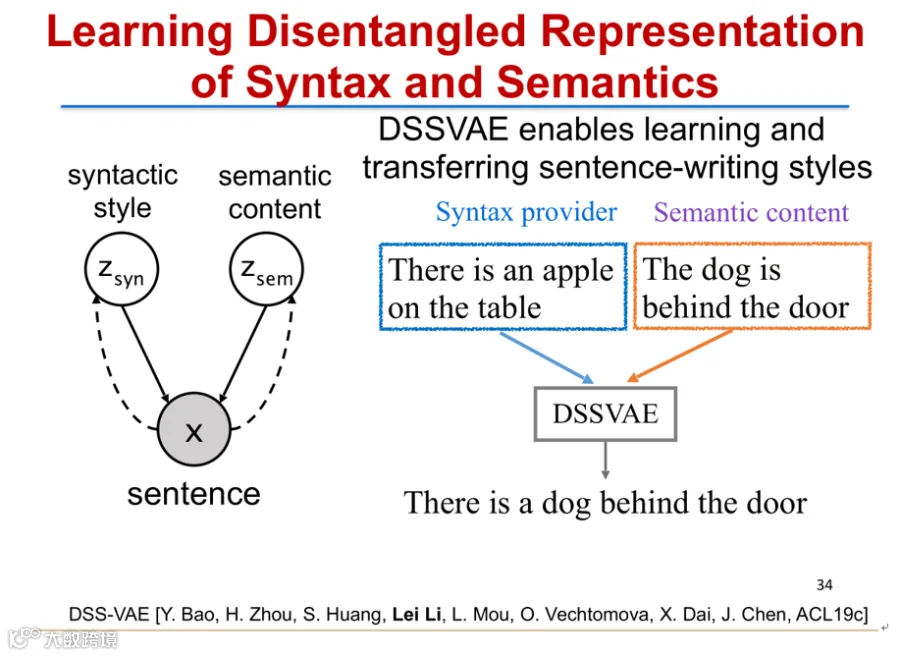
类似解耦学习方法还可分离句子的语法与语义表示,实现“句子嫁接”:例如结合“There is an apple on the table”的句式与“The dog is behind the door”的语义,生成“There is a dog behind the door”[7]。
该技术可用于辅助写作,借助高质量文本的语法结构提升普通作者的表达水平[k]。
基于约束的文本生成与多语言机器翻译新进展
CGMH、TSMH 与 mRASP 模型提升文本生成及翻译性能
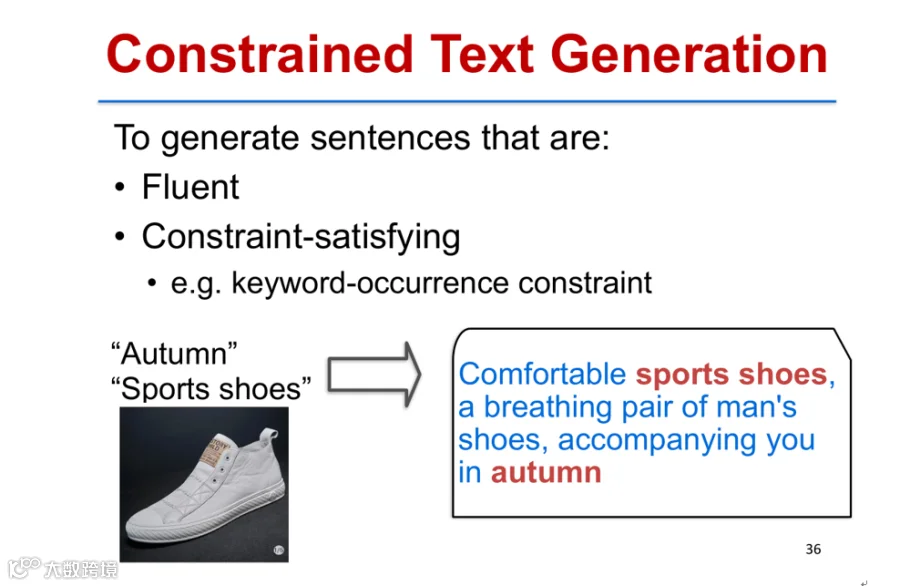
在广告文案生成等场景中,需确保特定关键词出现在文本中,这属于受限文本生成(Constrained Text Generation)中的关键词约束问题。传统方法如格束搜索(Grid Beam Search)虽能保证关键词出现,但生成文本质量不佳[k]。
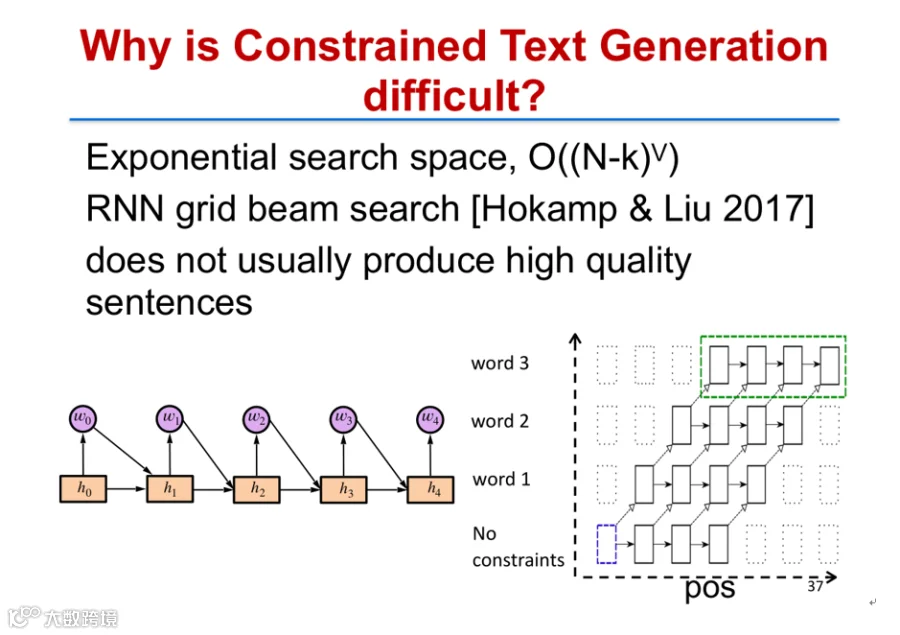
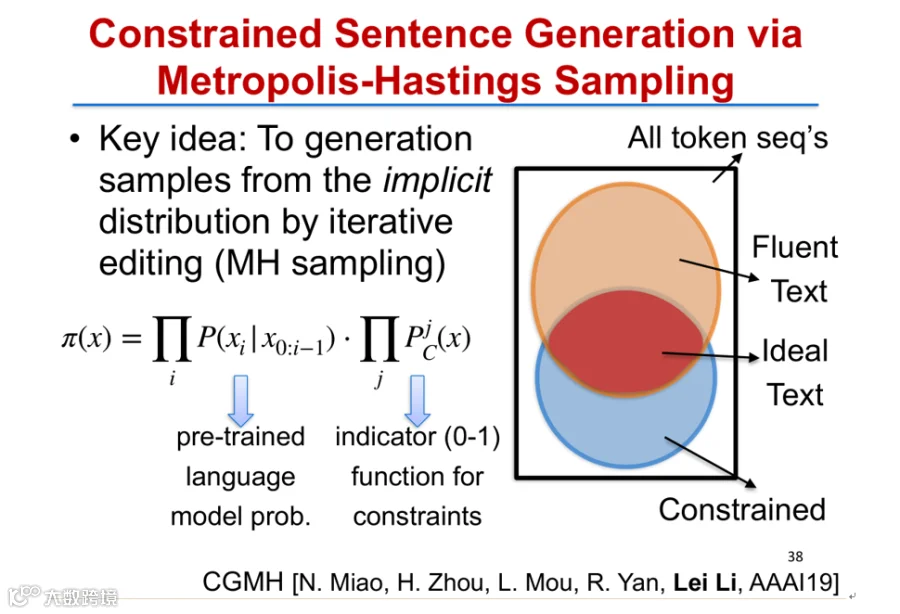
为此,研究提出一种基于采样的新框架——CGMH。该方法结合预训练语言模型(如GPT-2/GPT-3)与指示函数,分别衡量句子流畅度与约束满足程度。通过梅特罗波利斯-黑斯廷斯算法(Metropolis-Hastings),在初始句子基础上迭代进行词的插入、替换或删除,并判断是否接受新句子,最终生成既通顺又满足关键词约束的高质量文本[k]。

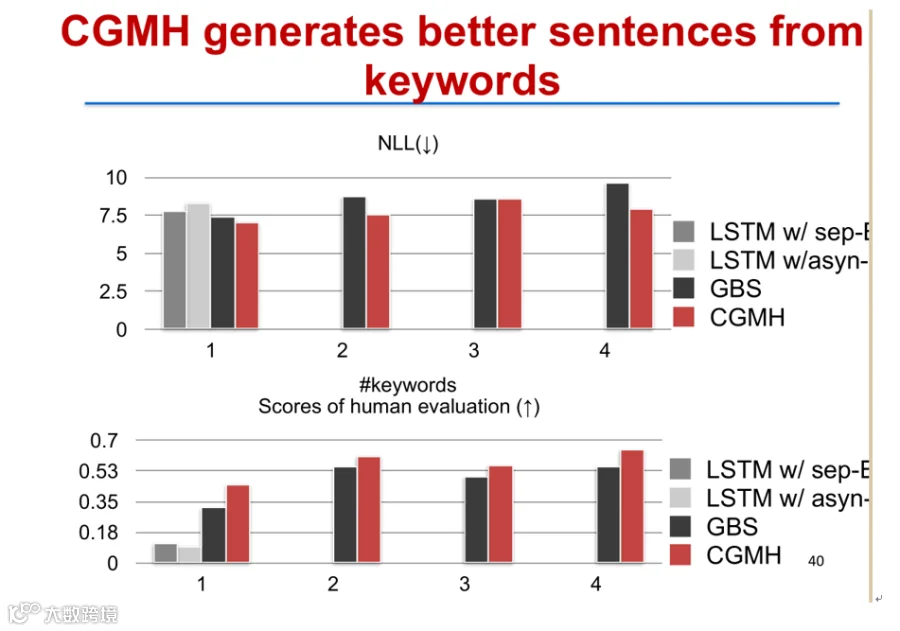
实验表明,CGMH在自动评估(NLL)和人工评分上均优于格束搜索与LSTM等方法。该技术已应用于大规模广告创作平台,服务超10万广告主,日均生成大量文案,采纳率超75%,验证了其实际有效性[k]。

CGMH还可用于生成对抗文本。例如,在情感分类任务中,通过对“I really like this movie”进行微小修改,生成语义相近但导致分类器误判的句子(如“we truely like the show”),有效测试模型鲁棒性[k]。

对于更复杂的逻辑或结构化约束(如将陈述句转为保留原意的疑问句),研究进一步提出TSMH算法(Tree Search enhanced Metropolis-Hastings)。该方法通过构造逻辑公式表达复杂限制,结合树搜索与采样机制,高效生成符合多重语义与结构约束的高质量文本[k]。


镜像生成式模型提升神经机器翻译性能
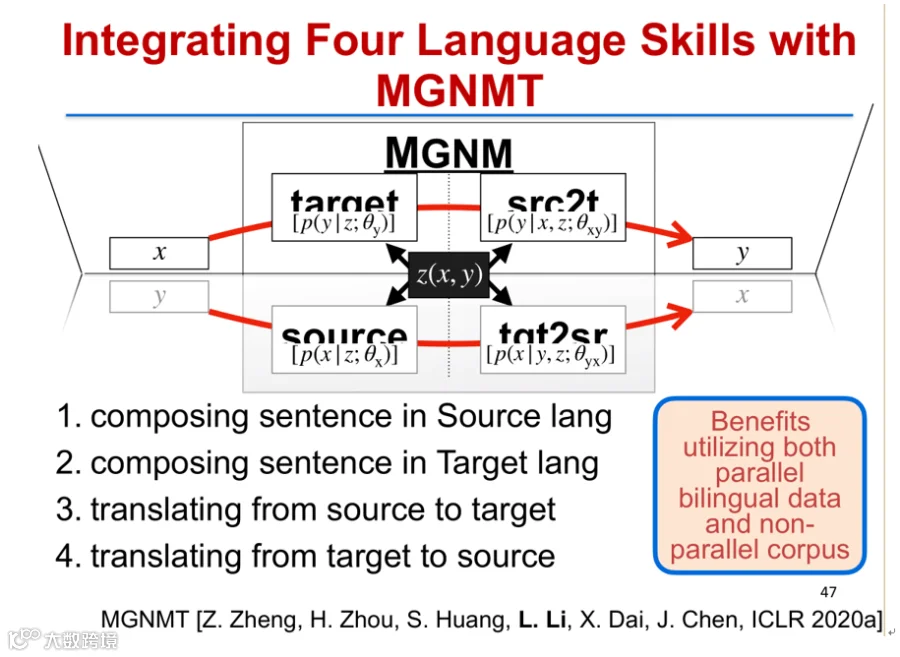
神经机器翻译依赖大量双语平行语料,但在低资源语言对(如中文-印地语)中数据稀缺。受人类语言能力启发——掌握两种语言即具备造句与双向翻译四种能力,研究提出镜像生成式神经机器翻译模型(MGNMT)[k]。

MGNMT引入隐变量Z连接源语言X与目标语言Y,统一建模P(Y|Z)(目标语言生成)、P(X|Z)(源语言生成)、P(Y|X,Z)(正向翻译)和P(X|Y,Z)(反向翻译)。利用“镜像性”特性,联合优化四项任务,实现平行语料与单语语料协同训练[k]。
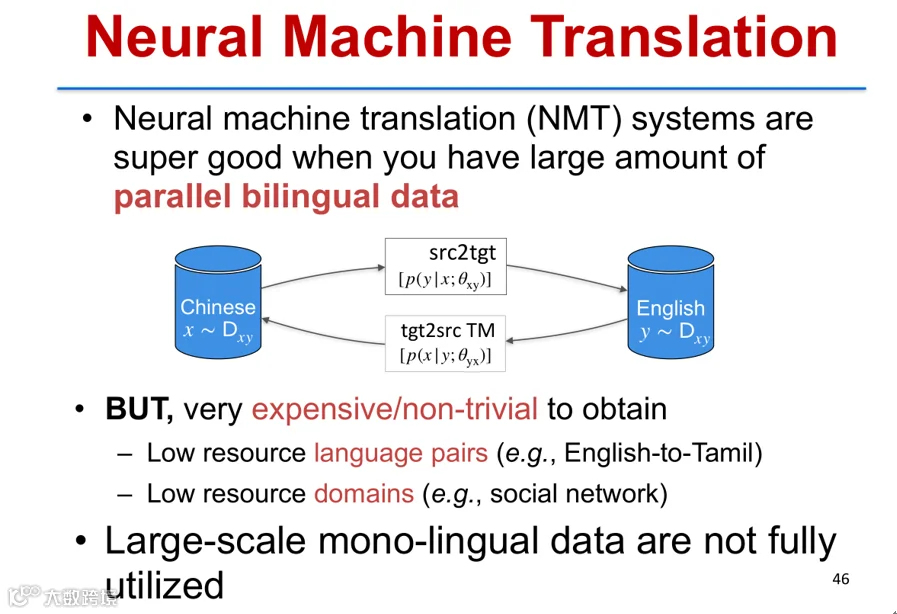

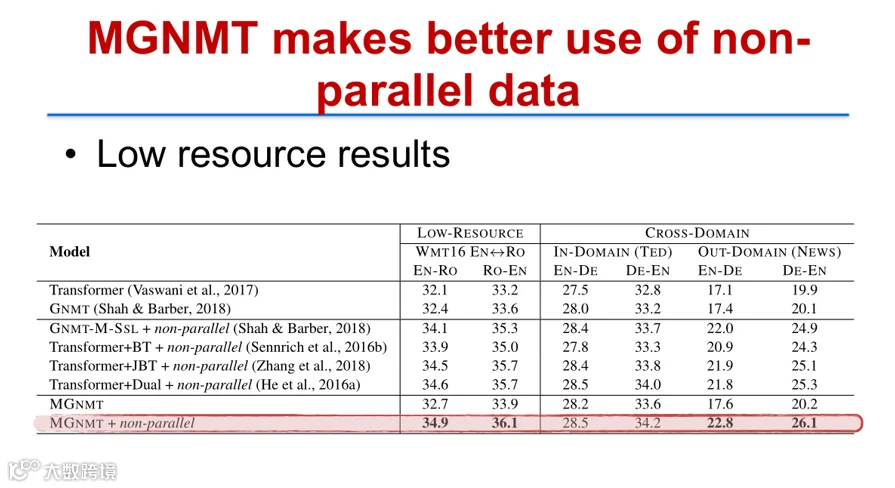
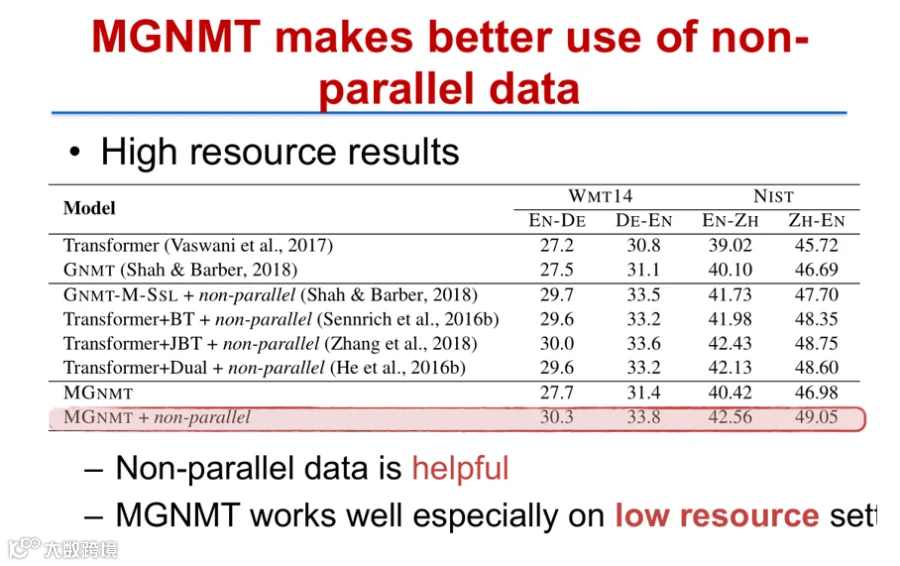
实验显示,MGNMT在低资源场景下显著优于传统Transformer及反向翻译方法;在高资源语言对(如英-德)中,结合非平行语料仍可取得明显性能提升[k]。
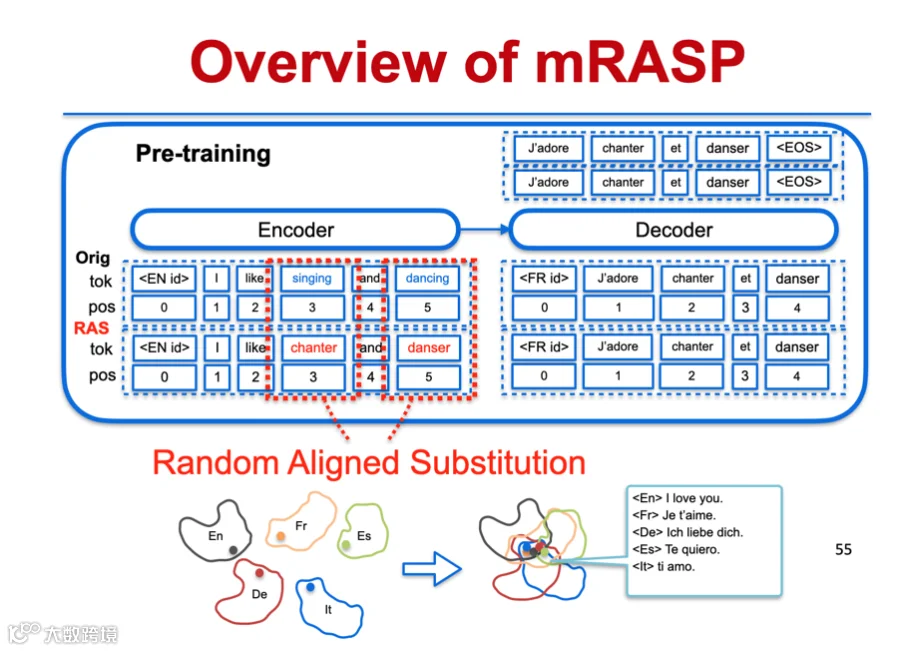
mRASP:多语言预训练提升翻译泛化能力
针对全球6900余种语言的翻译需求,研究提出多语言表示学习框架mRASP。其核心思想是利用跨语言语义锚点(即语义相同的句子),将多种语言映射至统一语义空间,实现知识迁移与低资源语言翻译能力增强[k]。


mRASP采用Transformer编解码结构,在输入端加入语言标识符以区分语种。通过“随机对齐替换”技术进行数据增强:利用双语词典替换源句中的词,生成伪平行语料,从而提升模型鲁棒性与泛化能力[k]。

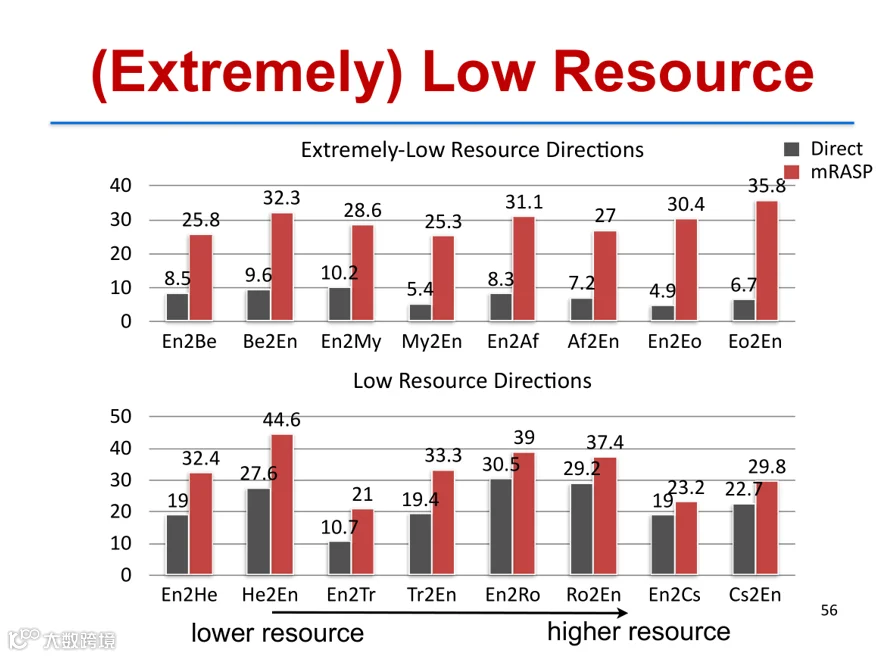
实验表明,在极低资源与低资源语言对上,mRASP预训练+微调策略带来超过10个BLEU点的提升;在中高资源场景下也显著优于XLM、MASS、mBART等基线模型[k]。
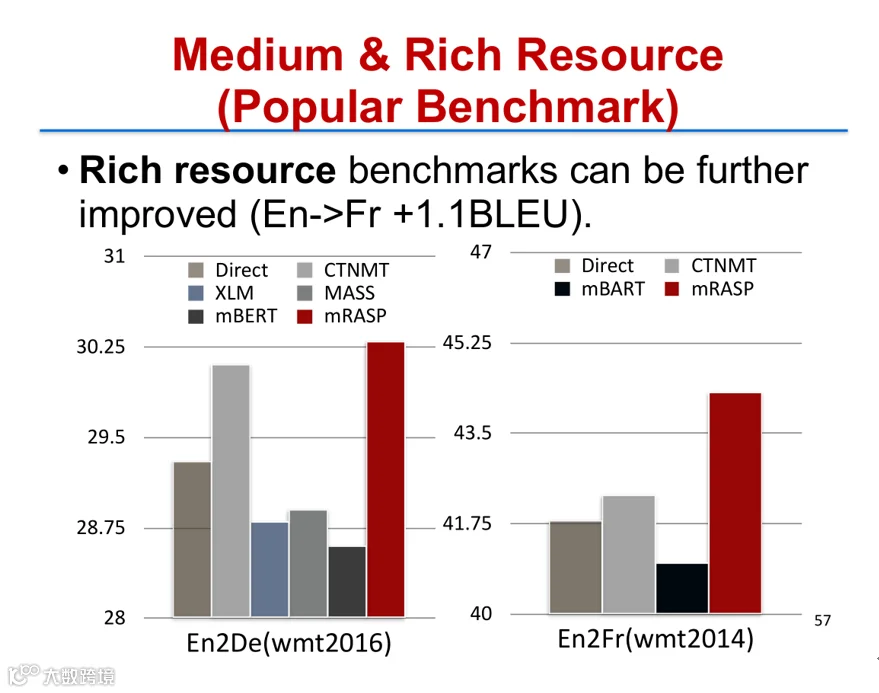
更重要的是,mRASP展现出对未见语言对的良好泛化能力。例如,在未参与预训练的荷兰语-葡萄牙语方向,仅用1.25万平行语料微调后,BLEU分数从0提升至13,证明其强大的迁移学习能力[k]。

研究成果已开源mRASP模型及高性能序列推理工具LightSeq,后者在NVIDIA GPU上实现相较TensorFlow超10倍的生成速度提升。相关技术集成于火山翻译系统,支持视频翻译、智能同传等功能,助力企业实现高效多语言内容处理[k]。

作者介绍:
李磊,字节跳动 AI Lab 总监、杰出科学家,卡耐基梅隆大学计算机科学博士,专注于机器翻译、机器写作与智能机器人研发。
数据到文本生成与自然语言处理领域重要研究成果综述
[6] R. Ye, W. Shi, H. Zhou, Z. Wei 和 L. Li 在 2020 年国际学习表征会议(ICLR)上提出了“变分模板机”(Variational Template Machine),用于数据到文本的生成[6]。
[7] B. Bao, H. Zhou, S. Huang, L. Li, L. Mou, O. Vechtomova, X. Dai 和 J. Chen 在 2019 年计算语言学协会第 57 届年会(ACL)上,探讨了从解耦的句法与语义空间生成句子的方法[7]。
[8] C. Hokamp 和 Q. Liu 在 2017 年计算语言学协会第 55 届年会上,提出了基于网格束搜索的词汇约束解码技术,用于序列生成[8]。
[9] N. Miao, H. Zhou, L. Mou, R. Yan 和 L. Li 在 2019 年第 33 届 AAAI 人工智能会议上,提出了基于 Metropolis-Hastings 采样的受限句子生成方法 CGMH[9]。
[10] T. Brown, B. Mann, N. Ryder 等人在 2020 年神经信息处理系统大会(NeurIPS)上发表了“语言模型是少样本学习者”(Language Models are Few-Shot Learners),推动了大模型的发展[10]。
[11] H. Zhang, N. Miao, H. Zhou 和 L. Li 在 2019 年计算语言学协会第 57 届年会(短文)上,研究了自然语言中流畅对抗样本的生成方法[11]。
[12] M. Zhang, N. Jiang, L. Li 和 Y. Xue 在 2020 年自然语言处理经验方法会议(EMNLP)的 Findings 分会上,提出了一种基于组合约束满足的树搜索增强蒙特卡洛方法用于语言生成[12]。
[13] Z. Zheng, H. Zhou, S. Huang, L. Li, X. Dai 和 J. Chen 在 2020 年国际学习表征会议(ICLR)上提出了用于神经机器翻译的镜像生成模型[13]。
[14] Z. Lin, X. Pan, M. Wang, X. Qiu, J. Feng, H. Zhou 和 L. Li 在 2020 年自然语言处理经验方法会议(EMNLP)上,提出利用对齐信息预训练多语言神经机器翻译模型[14]。
[15] LightSeq 项目相关信息可参考其 GitHub 开源地址[15]。
