
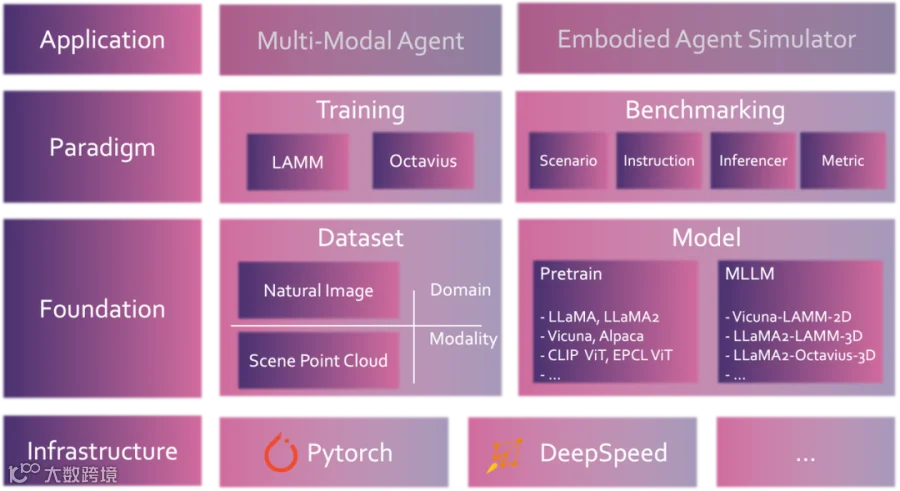
LAMM:开源多模态大语言模型社区助力AI研究
北航、复旦、港中大(深圳)等联合推出轻量高效、支持多模态与Agent研究的开源框架
LAMM(Language-Assisted Multi-Modal)致力于构建面向开源学术社区的多模态指令微调与评测体系,涵盖优化训练框架与全面评估机制,支持图像、点云等多种视觉模态[k]。
自ChatGPT问世以来,大语言模型(LLM)在自然语言交互方面取得突破性进展。然而,现实世界中的交互不仅限于文本,还包括图像、深度信息等多模态数据。当前多数多模态大语言模型(MLLM)研究闭源,限制了高校与研究机构的探索。同时,LLM在时事理解与复杂推理方面仍显不足,缺乏“深度思考”能力。AI Agent技术正成为突破这一瓶颈的关键路径,赋予模型自主决策、环境反应与社交互动等智能特征,被视为MLLM的重要演进方向[k]。
来自北京航空航天大学、复旦大学、悉尼大学、香港中文大学(深圳)以及上海人工智能实验室的研究团队共同发布了早期开源多模态语言模型项目之一——LAMM。该项目旨在打造可持续发展的开源生态,支持MLLM训练与评测、以及基于MLLM的智能Agent研究,推动更多研究者参与多模态AI创新[k]。

LAMM提供低资源门槛的MLLM训练与评估方案,仅需RTX 3090或V100即可启动;支持构建基于MLLM的具身智能Agent,适用于机器人与游戏模拟器任务;并可在多个专业领域扩展应用[k]。
开源框架特性
LAMM代码库实现统一数据格式、组件化模型设计与一键式分布式训练,便于用户快速搭建专属多模态语言模型[k]。
- 标准化数据格式:兼容LLaVA、ShareGPT4V等主流多模态指令数据集,支持无缝接入与一键训练[k]。
- 模块化模型架构:将模型分解为视觉编码器、特征映射器与语言模型三大组件,支持Image、Point Cloud等输入模态及LLaMA/LLaMA2系列语言模型自由组合[k]。
- 低资源训练优化:集成Deepspeed、LightLLM、Flash Attention等加速技术,可在4张RTX 3090上微调7B参数模型,显著降低计算成本[k]。
- 支持具身智能Agent构建:结合机器人或模拟器生成任务指令数据,利用MLLM实现环境感知与决策分析[k]。
多模态训练与评测体系
LAMM支持图像与点云等多模态输入,并可通过新增编码器扩展至其他模态。借助PEFT高效微调方法及Flash Attention、xFormers等计算优化工具,进一步压缩训练开销。面对多任务学习挑战,LAMM引入MoE策略统一管理微调参数,提升模型泛化能力[k]。
针对当前多模态模型评估缺乏标准化与全面性的难题,LAMM构建了高可扩展、灵活的评测框架ChEF,支持多维度能力评估与跨模型公平对比,助力全面认知MLLM性能边界[k]。
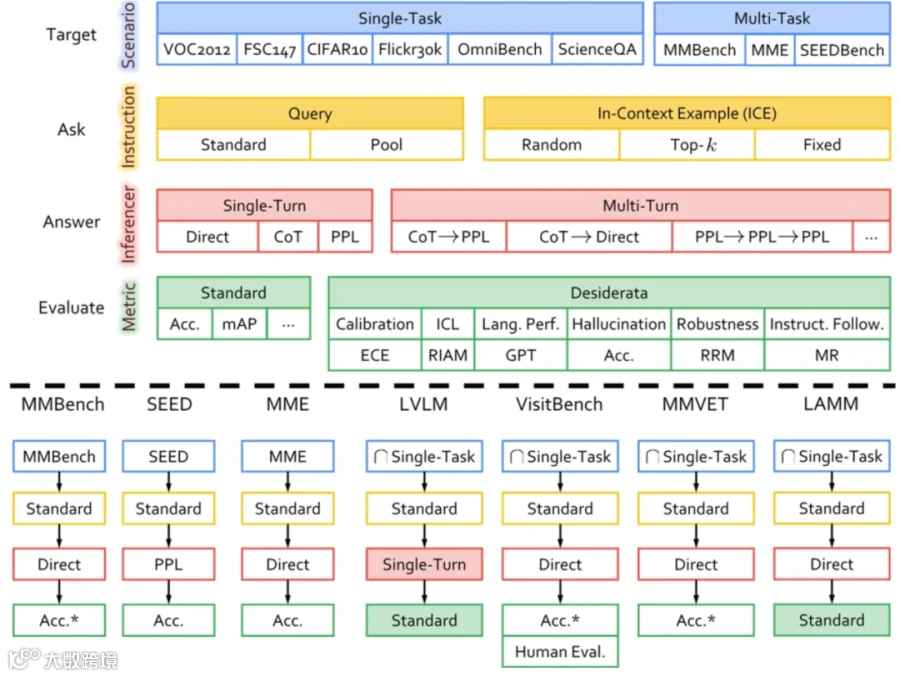
一键式组合式多模态语言模型评测框架
基于LAMM框架的模型能力示例如下:
2D图像问答能力


3D点云视觉问答能力

多模态驱动的具身智能Agent
现有基于LLM的Agent研究常忽略实时感知环节,假设环境信息完全可得。为弥补这一缺陷,研究团队提出由MLLM驱动的具身智能体MP5,集成视觉感知与主动探索能力。其核心架构基于LAMM模型,能够应对未知任务,通过主动获取环境信息做出合理决策,具备开放环境下的长序列复杂任务执行能力[k]。
例如,在Minecraft中,MP5可完成“在晴天光线充足时,寻找位于平原、靠近水源且有草的猪”这类需综合多种环境条件的任务,展示其强大的感知与规划协同能力[k]。
总结
LAMM标志着多模态学习进入新阶段,致力于建设开放、协作的学术生态。项目已开源完整的数据准备、模型训练与评测流程,持续更新于官网。作为早期深耕该领域的团队,研究者希望不断优化LAMM工具箱,提供轻量易用的研究平台,携手全球开发者推动多模态AI前沿探索[k]。

投稿或寻求报道请联系:content@jiqizhixin.com[k]。