
清华、华为等提出认知超分辨率框架CoSeR,让图像修复更智能
结合图像理解与语言认知,突破传统超分技术局限,实现更真实、泛化性更强的画质提升
机器之心专栏
机器之心编辑部
从低清图像中提取认知特征,这样的超分辨率才更真实。
图像超分辨率(Super-Resolution, SR)技术旨在将低分辨率图像转换为高分辨率图像,提升清晰度与细节真实性,广泛应用于手机影像等领域[k]。然而,现有方法存在泛化能力弱和缺乏图像内容理解两大瓶颈[k]。一方面,模型往往依赖特定场景数据训练,跨场景表现不佳且计算成本高;另一方面,主流方法仅学习图像退化分布,难以利用常识恢复物体结构与纹理[k]。

图 2. 真实场景超分 SOTA 方法的局限性:(行一)难以处理训练集外的退化分布;(行二)难以利用常识恢复物体结构。
受诺贝尔奖得主丹尼尔・卡尼曼“双系统”认知理论启发,研究团队提出认知超分辨率(Cognitive Super-Resolution, CoSeR)框架[k]。传统方法类似于“系统一”——快速但直觉化;而CoSeR模拟“系统二”——缓慢、多步、基于认知推理,通过理解图像内容并结合先验知识实现超分[k]。

图 3. CoSeR 采用类似于人脑中系统二的修复方式。
由清华大学、华为诺亚方舟实验室、香港科技大学等联合提出,CoSeR框架首次将图像外观与语言理解结合,从低清图像中提取认知特征,实现具备内容理解能力的通用超分模型[k]。其核心贡献包括:
- 提出通用万物超分大模型CoSeR,显著提升模型泛化性与语义理解能力;
- 设计基于认知特征的参考图像生成方法,生成内容一致的高质量参考图以指导修复;
- 引入“All-in-Attention”模块,融合低清图像、认知特征与参考图像,增强多源信息交互;
- 在多个真实场景测试集上超越现有方法,展现优异保真度与视觉质量[k]。

CoSeR架构如图4所示:首先通过轻量级认知编码器解析低清图像,提取语义与细节特征;随后将认知特征注入Stable Diffusion模型,激活图像先验以恢复精细纹理[k]。同时,利用认知特征生成高质量参考图像,辅助超分过程。最终通过“All-in-Attention”机制实现三路条件融合,提升重建精度[k]。
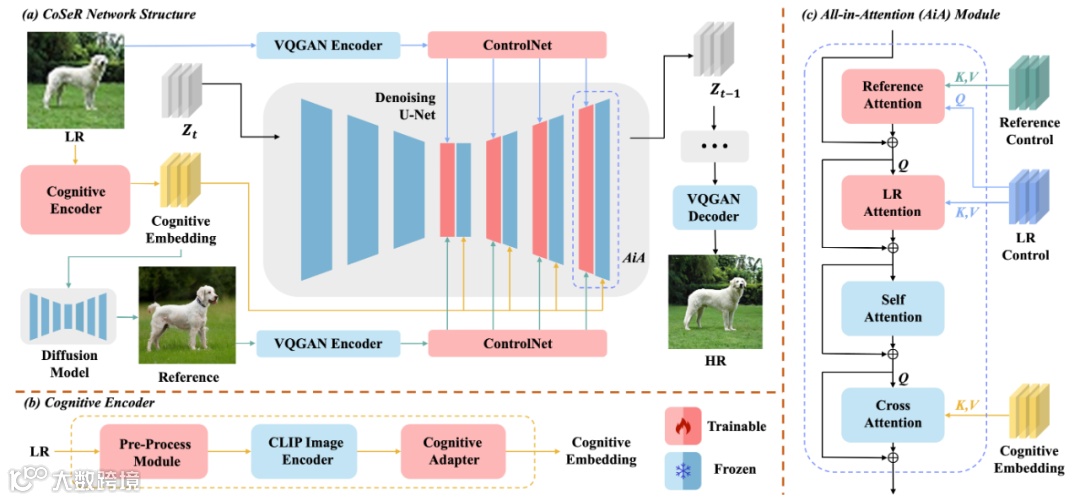
图 4. 本文提出的万物超分画质大模型 CoSeR。
实验表明,相比BLIP2等大模型生成描述的方式,CoSeR的认知特征更鲁棒且细粒度更强[k]。在复杂退化或分布外场景下仍能生成内容一致的参考图像,且认知编码器参数量仅为BLIP2的3%,显著提升推理效率[k]。

图 5.(行一)使用 BLIP2 描述生成的参考图和 CoSeR 生成的参考图;(行二)CoSeR 的高鲁棒性。
在ImageNet、RealSR和DRealSR等多个数据集上的定量与定性结果表明,CoSeR在视觉质量、内容一致性与结构完整性方面均优于现有方法[k]。
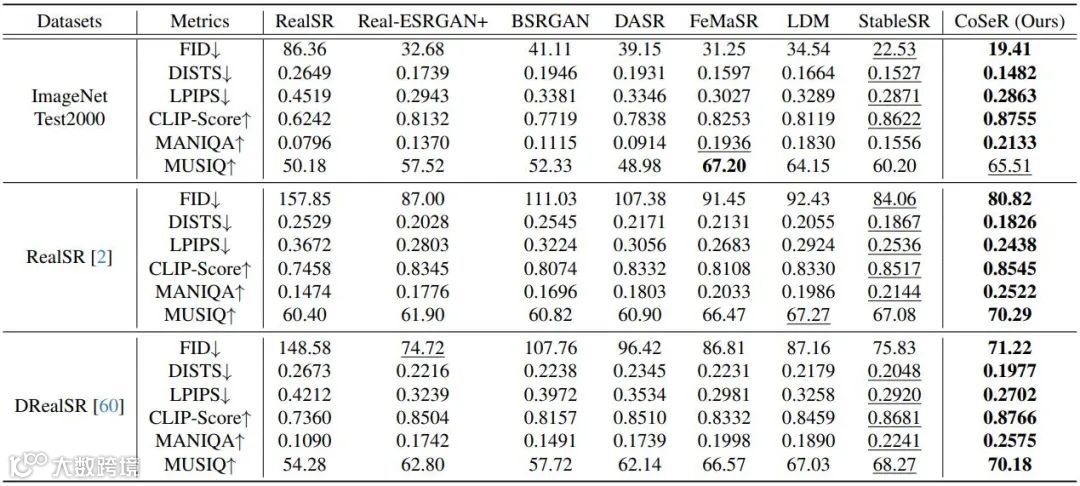
表 1. 定量结果对比。

图 6. 定性结果对比。
CoSeR为图像超分提供了认知驱动的新范式,未来研究将聚焦于加速采样过程以提升效率,并探索该统一模型在更多图像修复任务中的应用潜力[k]。