![[MYSQL] 使用undrop-for-innodb和ibd2sql恢复mysql 8.0环境被drop的表](https://cdn.10100.com/user/de571bd04dbb4a089808a73926025ac3.png?x-oss-process=style/180x)
导读
日常运维中, 难免遇到某些表不小心被drop的场景, 而恰好又没有备份? 咋办呢? 当然是跑路啦
undrop-for-innodb 是一款很NB的数据恢复工具,支持在没有备份的时候恢复被drop的表; 网上教程也很多, 但是都是针对5.6/5.7环境的, 其实这款工具也是支持MySQL 8.0环境的. 本文主要就是讲如何使用undrop-for-innodb和ibd2sql恢复mysql 8.0环境被drop的表
undrop-for-innodb原理
先来看看undrop-for-innodb的原理:
-
使用stream_parser提取ibdata1中的索引信息, -
使用c_parser提取上述索引信息中被删除表的tableid -
根据tableid使用sys_parser提取上述索引信息中的字段信息(拼接表结构),可选 -
根据tableid使用c_parser提取上述索引信息中的indexid -
根据indexid使用stream_parser扫描磁盘获取相关索引页 -
根据表结构信息使用c_parser解析第五步得到的索引页.
stream_parser是扫描磁盘提取索引页的工具,支持使用
-T指定要解析的索引
看起来比较啰嗦, 总结就是:解析ibdata1获取indexid,根据indexid扫描磁盘获取数据.
为了方便展示, 我们画个图:
而8.0里面的表/索引信息是放在mysql.ibd中的, 表结构信息还可以找开发提供, 而indexid部分就无法使用undrop-for-innodb了. 咋办呢?
ibd2sql
有一款名叫ibd2sql的工具可以解析ibd文件, mysql.ibd也是ibd文件, 那不就可以解析了么!
ibd2sql解析ibd文件的原理其实就是: 根据表结构一行行,一个个字段的读取ibd文件中的数据. 当然可以使用一些特殊选项来解析需要的数据.
所以我们可以把获取索引id之类的信息交给ibd2sql做, 抽取索引页的步骤给undrop-for-innodb做, 解析数据部分,两个都可以做.
恢复被drop的表
目前ibd2sql不支持根据系统表(mysql.tables,mysql.columns等)来拼接DDL, 所以DDL部分我们还得找开发要. 我这里就直接给出DDL了
软件下载与安装
undrop-for-innodb的下载安装及编译(需要先安装好mysql)
# 软件下载wget https://github.com/twindb/undrop-for-innodb/archive/refs/heads/master.zipunzip master.zipcd undrop-for-innodb-master# 环境准备yum install make gcc -y# 编译make# 输出stream_parser,c_parser,innochecksum_changer 在当前目录# 编译sys_parser (需要安装mysql, 即需要使用mysql_config)make sys_parser# 输出 sys_parser# 需要libmysqlclientln -s /soft/mysql_3306/mysqlbase/mysql/lib/libmysqlclient.so.20 /usr/lib64/mysql/libmysqlclient.so.20ldconfig
ibd2sql的下载
yum install python3 -ywget https://github.com/ddcw/ibd2sql/archive/refs/heads/ibd2sql-v2.x.zipunzip ibd2sql-v2.x.zipcd ibd2sql-ibd2sql-v2.x/
模拟drop表
数据库的安装就省略了.
本次使用8.0.43版本模拟.
select @@version;create table t20250913_test_drop(id int, name varchar(200));insert into t20250913_test_drop values(1,'ddcw'),(2,'https://github.com/ddcw/ibd2sql'),(3,'https://github.com/twindb/undrop-for-innodb');drop table t20250913_test_drop;

使用ibd2sql获取indexid
先根据表名获取tableid
python3 main.py /data/mysql_3306/mysqldata/mysql.ibd --sql --delete --complete --set table=tables | grep t20250913_test_drop
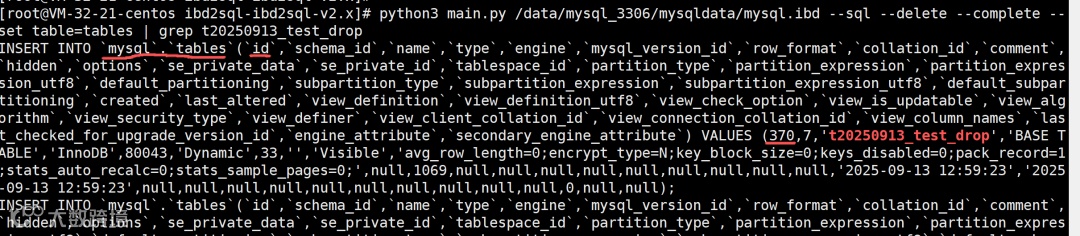
这个id字段就是tableid, 故tableid=370
根据tableid获取主键的索引id
python3 main.py /data/mysql_3306/mysqldata/mysql.ibd --sql --delete --complete --set table=indexes | grep 370
table_id为370对应的数据有个 “id=159;root=4…” 中id=159的159就是indexid; root=4中的4是root pageno, 但都被drop了, 就无法根据pageno来恢复了. 所以我们只需要indexid.
根据indexid扫描磁盘
./stream_parser -f /dev/vda1 -t 50G -T 159


注意不一定能扫描出来的, 有可能被回收了, 全看运气, 所以备份是很重要的.
使用ibd2sql解析数据(二选一)
然后我们就可以使用ibd2sql解析相关数据页的数据了.
得需要相同表结构的frm/ibd文件, 且需要修改后缀.page为.ibd
python3 main.py /root/undrop-for-innodb-master/pages-vda1/FIL_PAGE_INDEX/0000000000000159.ibd --sdi /data/mysql_3306/mysqldata/db2/t20250913_test_drop.ibd --sql --set leafno=0 --set rootno=0 --force

这里解析出来数据是重复的, 是因为undrop-for-innodb扫描的页就是重复的导致的.
使用undrop-for-innodb中的c_parser解析数据(二选一)
需要构造相关的表结构
-- t20250913_test_drop.sql
create table t20250913_test_drop(
id int,
name varchar(200));
然后解析数据
./c_parser -6f pages-vda1/FIL_PAGE_INDEX/0000000000000159.page -t t20250913_test_drop.sql

思考
思考1:
ibd2sql v1.x版本的时候也是支持恢复drop的表的,但原理是解析xfs文件系统, 根据Inode记录的信息去对应的磁盘构建完整的ibd文件. 这种设计限制太大了,如果inode被破坏了, 就无法恢复了. 所以ibd2sql v2.x后续版本也会根据indexid扫描磁盘文件然后尽可能的恢复数据.
对于drop的表的恢复, 和undrop-for-innodb的设计比起来,ibd2sql还是太’老实’了, 不够创新,不够胆大.
思考2:
数据是放在索引页里面的, 索引页是有索引id的; 但是对于溢出数据而言是放在溢出页(off-page)的,而溢出页是不记录索引id的, 那么应该怎么解析呢?
undrop-for-innodb的做法是每个溢出页都放在pages-vda1/FIL_PAGE_TYPE_BLOB目录下面, 解析的时候需要哪个page就去读哪个page. 但如果存在相同的pageid的溢出页时会怎么样呢?

FIL_PAGE_INDEX 目录的文件是根据indexid来的, FIL_PAGE_TYPE_BLOB目录下的文件是根据pageid来的
总结
准备使ibd2sql支持解析undrop-for-innodb碎片页的时候, 看了下undrop-for-innodb的原理, 发现其还不支持8.0环境, 故尝试使其与ibd2sql结合的效果, 还不错. 后续ibd2sql也会引进该功能(不再傻兮兮的解析文件系统了…)
根据indexid,spaceid直接扫描磁盘,然后尽可能的还原为ibd文件, 可能实现起来更简单点. 但如果目标文件很大的话, 还原出来的ibd文件也可能很大了, 即使实际数据并不算多. 道阻且长.
备份很重要!
参考:
https://github.com/twindb/undrop-for-innodb
https://github.com/ddcw/ibd2sql