
一切的开端
大道至简
没想到2025年1月,突然Deepseek发了一个论文,并发布了R1系列模型。他们直接给大家揭开了CloseAI一直藏着掖着的秘密:如何训练出一个真正有思考能力的模型。

原型机
Deepseek通过让Deepseek-V3模型纯强化学习(RL),训练了个模型叫Deepseek-R1-Zero,其实这玩意比较像一个原型机,用来验证这个概念是正确的。结果也如图片所示,能力超群,经过8000步的训练后,模型能力提高了几倍,甚至超越了o1-0912。但是这个模型放到生产环境,会有很多问题(比如多语言混杂,输出看不懂等),需要再精加工一下,让这个模型变得更用户友好。

(模型能力随着RL训练次数的增加,线性上升)
成熟产品
他们就继续搞了个现在大家熟知的Deepseek-R1。R1其实就是在原来的纯强化学习(RL)基础上,加了很多人类的干预(SFT),让输出更加可控,让整个模型更加友好。过程比较复杂,大概就是结合了微调和强化学习,算是传统和创新结合,重新训练了一个生产环境可用的模型:Deepseek-R1。
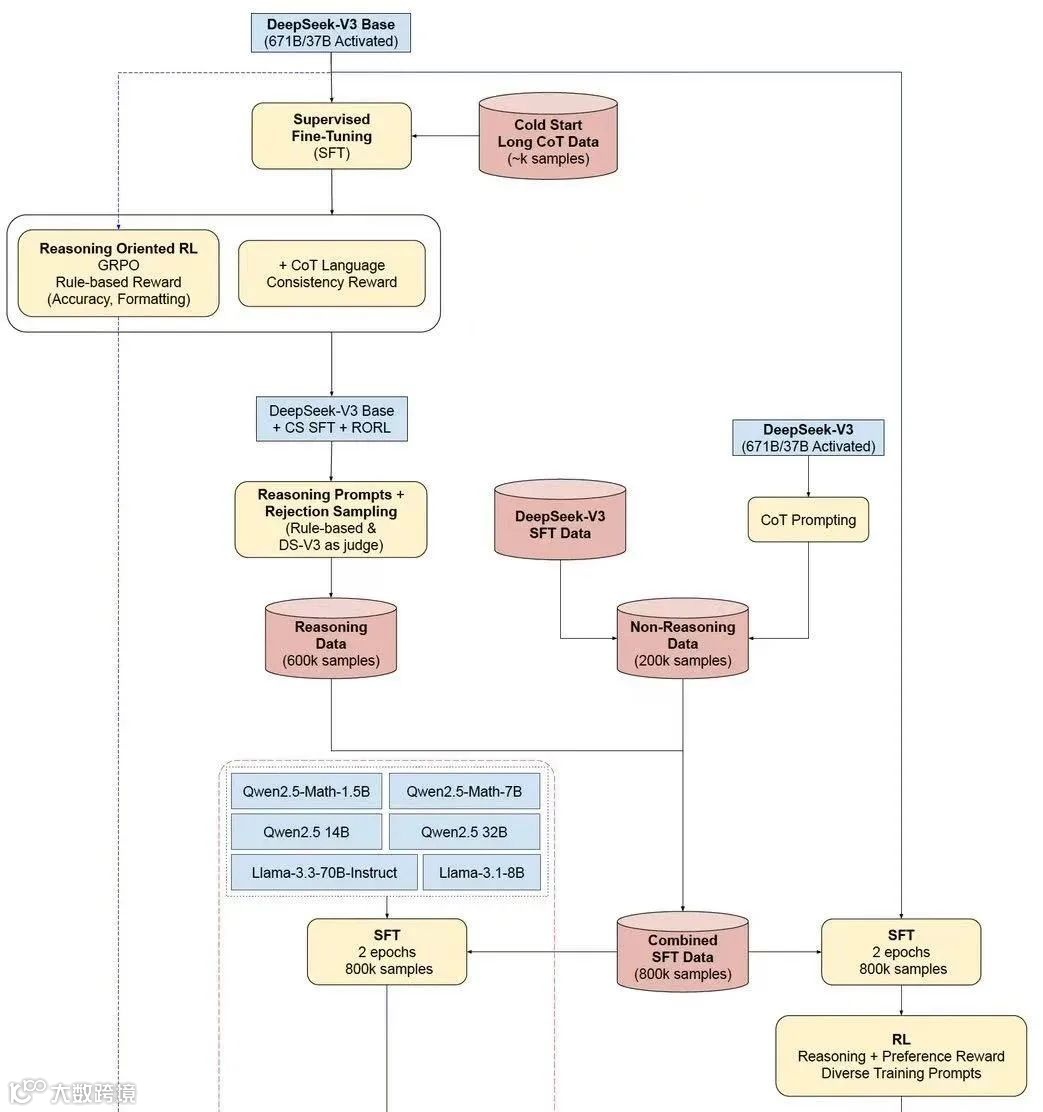
(R1的训练步骤图解)
从大到小
但是这玩意本质还是Deepseek-V3基于训练的,参数很大,普通机器是跑不起来的,他们又继续搞了一些小模型出来,大大降低部署门槛,甚至做到个人电脑可部署。


三个结论
所以Deepseek这个研究成果,展示了三个结论:
模型的思考能力的锻炼靠强化学习就可以了,这个阶段人类不要干预(Deepseek-R1-zero)
模型学会思考后,还是需要人类的参与才能让模型学会如何和人类沟通(Deepseek-R1)
小模型就别自己思考了,蒸馏的效果更好。思考能力的增强和原来的模型的能力密切相关。(Deepseek-R1-distill)
四个推断
这三个结论,把CloseAI藏着掖着的商业秘密直接揭露了(有可能CloseAI了解得还没Deepseek多,who knows),并且我也得出几个
更大的基础模型可能不是没有意义,而是需要经过强化学习的后训练,才知道提升有多大。这就是新的Scaling Law。
小模型可以不用学会思考,越强的思考模型可以蒸馏出越好的小模型,小模型应该很快就会超越现在顶级模型的水平
在不同领域通过强化学习训练出强大的专业思考模型,再将思考模型蒸馏出轻量的小模型,再本地化部署,可能会是一个不错的生意
真正的思考模型展示了真正的智能,AI不仅是知识的压缩,而是真的可以学会思考,最终超越人类,AGI又往前迈出了一步。