
在日常工作中,你是否遇到过这些需求:用“秋天金黄的银杏大道”,“一辆黑色宝马车前一个老人在骑自行车”这句话搜相关图片,用一段产品截图找对应的说明书文档,或是用短视频片段搜同类内容?这些“跨类型信息匹配”的场景,背后都离不开多模态检索技术的支撑。
今天我们就从多模态检索的核心逻辑入手,拆解3类主流的多模态表征模型(GME、CLIP、VISTA),最后横向对比它们的适用场景,帮你快速理清技术选型思路。
一、什么是多模态检索?先搞懂核心逻辑
首先明确一个关键概念:通用多模态检索(UMR) ——简单说,就是用一个统一模型,实现“文本、图像、视频”等不同类型信息的跨模态搜索(比如“文搜图”“图搜视频”“图文组合搜内容”)。
它的核心原理很直观:通过多模态表征模型,把文本、图片、视频这些“不同语言”的信息,统一转换成计算机能理解的“高维浮点数向量”(可以想象成一串带语义的数字密码)。这些向量被放进同一个“语义空间”后,就能通过计算“余弦相似度”,快速判断不同模态内容的关联度——这也是视频分类、图文检索、相似内容聚类的底层逻辑。
多模态表征模型的3大核心能力
多模态检索的价值,全靠表征模型的这3个能力支撑,每个能力都对应具体场景:
- 跨模态检索
:打破模态壁垒,比如用“猫咪在阳台晒太阳”的文本搜同款图片,用一张手机截图搜对应的产品介绍视频,甚至“以图搜图”“以文搜文”。 - 语义相似度计算
:判断不同内容的“语义关联度”,比如给“红色运动鞋”的文本和“暗红色跑鞋”的图片打分,确认两者是否匹配。 - 内容分类与聚类
:按语义自动分组,比如把海量商品图按“服装”“家电”“美妆”分类,或给用户评论按“好评”“差评”“疑问”打标。
需要注意的是:多模态表征模型聚焦的是高层语义特征,不会过度纠结纹理、颜色这类细节。比如你用“淡蓝色碎花裙子”检索,模型大概率能匹配到“蓝色裙子”,但“碎花”的细节可能因表征精度不足而无法精准命中——这是当前技术的常见局限,选型时需提前考虑。
下图展示了多模态检索的核心逻辑:所有模态均转换为统一向量后进行匹配
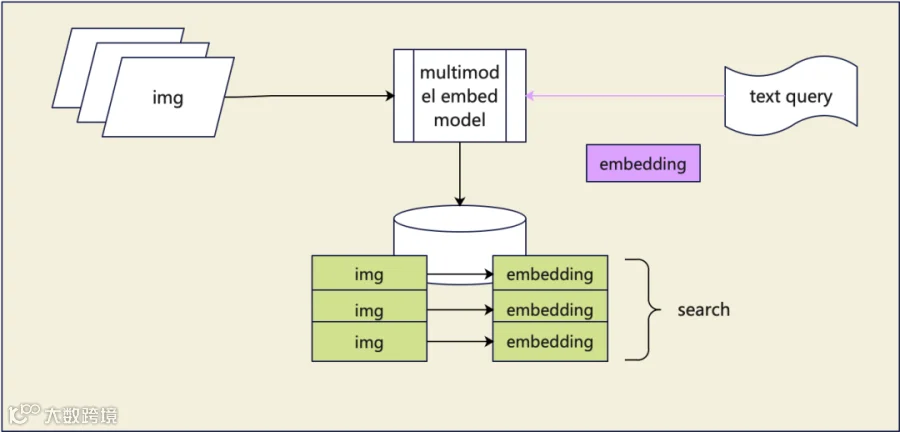
二、3类主流多模态表征模型:技术细节与适用场景
想实现多模态检索,关键是选对表征模型。目前行业内应用最广的是3类模型:阿里的GME、OpenAI的CLIP(及中文优化版)、BAAI的VISTA。我们分别拆解它们的核心设计、优势与局限。
2.1 阿里GME:2025年“性能新秀”,主打复杂场景与文档理解
2025年初,阿里巴巴通义实验室推出的GME(General MultiModal Embedding) ,是近期多模态检索领域的“黑马”——它基于Qwen2-VL大模型优化,专门解决高难度的跨模态匹配问题,比如学术论文截图检索、复杂文档理解等。
GME的核心设计:统一模态+动态分辨率
GME的最大特点是“全场景覆盖”,具体体现在3个方面:
- 输入类型灵活
:支持单文本、单图像、“文本+图像”组合(图文对)3类输入,能实现“Any2Any Search”(比如用图文对搜图文对,用文本搜视频截图); - 动态图像分辨率
:依托Qwen2-VL的底座能力,能自适应处理不同分辨率的图片,不用手动调整尺寸; - 表征精度优化
:虽然Qwen2-VL本身有强多模态理解能力,但GME额外做了“表示学习微调”——用最后一个token的隐藏状态作为表征,让向量更贴合检索需求。
GME的模型架构如下,清晰展示了3类输入的处理逻辑
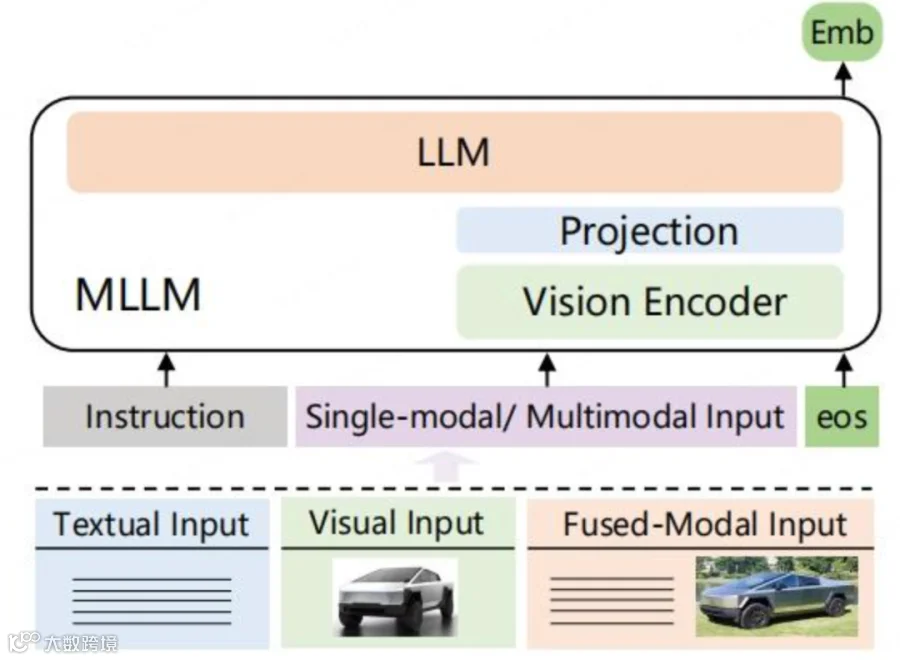
GME的4大核心优势
- 性能顶尖
:在通用多模态检索基准(UMRB)上实现SOTA(当前最优)结果,在MTEB(多模态文本评估基准)上分数也领先; - 文档理解强
:能精准识别文档截图中的细节(比如学术论文的公式、表格),特别适合“多模态RAG”(比如用文本检索包含公式的论文片段); - 检索场景全
:支持单模态(文搜文/图搜图)、跨模态(文搜图/图搜文)、融合模态(图文对搜内容)3类检索; - 版本可选
:目前在魔塔平台发布了2B和7B两个版本(链接见下文),可根据算力需求选择。
注意:GME的2个使用限制
- 单张图片输入限制
:为保证训练效率,图片转换后的“视觉标记”patch数量被限制为1024个——超高清图片可能会被压缩,细节要求极高的场景需谨慎; - 仅英文训练
:虽然Qwen2-VL支持多语言,但GME的训练数据全是英文,中文场景的多模态匹配性能暂未保证。
GME模型获取链接:
-
gme-Qwen2-VL-2B-Instruct -
gme-Qwen2-VL-7B-Instruct
2.2 CLIP与中文CLIP:经典双塔模型,中文场景的“性价比之选”
如果说GME是“新秀”,那OpenAI的CLIP就是多模态表征领域的“经典款”——它凭借“双塔模型”的简洁设计和大规模数据训练,成为很多入门场景的首选;而中文CLIP则是针对中文场景的“定制优化版”,解决了原始CLIP不支持中文的痛点。
CLIP:双塔结构的“简洁美”
CLIP的核心优势在于“简单且通用”,具体设计有3个关键点:
- 双塔模型架构
:分为“图像塔”和“文本塔”——图像塔用Vision Transformer(ViT)提取图片特征,文本塔用经典Transformer提取文本特征,两者独立工作却能实现语义对齐; - 弱监督训练
:不用人工标注数据,而是用从网络采集的4亿组“图文对”(比如图片+标题)做对比学习,让模型自动学习“图与文的关联”; - 零样本能力强
:训练后不用额外微调,就能直接实现“图文相似度计算”“跨模态检索”“零样本图片分类”(比如用“小狗”“小猫”的文本,给未标注的动物图片分类)。
CLIP的双塔结构:图像与文本分别通过独立编码器转换为向量,再进行对齐训练
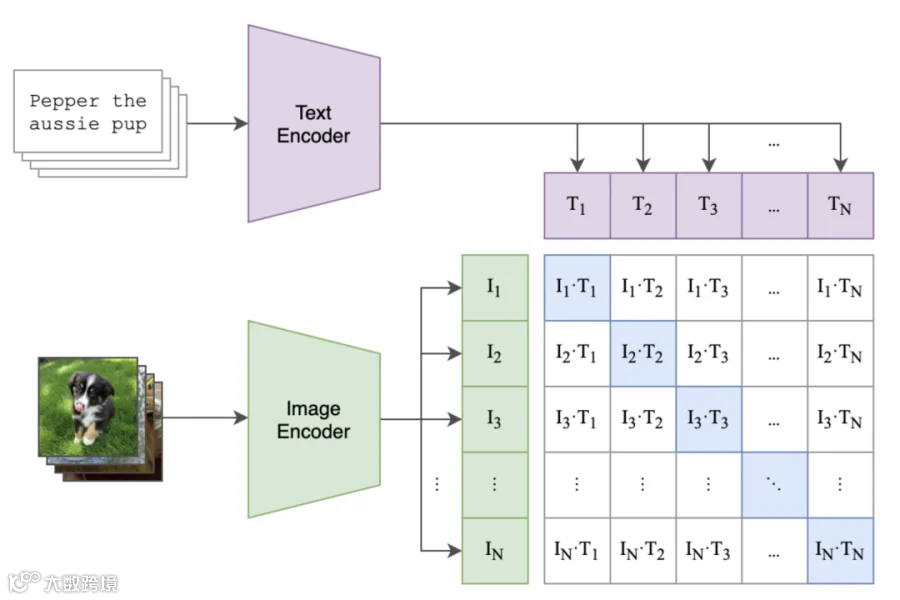
再看中文CLIP:针对中文的“定制化优化”
原始CLIP基于英文数据训练,无法精准理解中文语义(比如用“红烧排骨”检索,可能匹配到“炖肉”而非精准的“排骨”)。而中文CLIP通过2点改进,解决了这个问题:
- 文本编码器改造
:把原始的英文文本编码器,替换为适配中文的RoBERTa-wwm-Chinese模型,能更好捕捉中文语义; - 分阶段训练
:第一阶段冻结图像编码器,只优化文本编码器(让文本侧先适配中文);第二阶段再同时训练两个编码器,确保“中文文本”与“图像”的语义对齐。
中文CLIP的版本选择:看参数量与分辨率
目前中文CLIP提供5个版本,核心差异在“参数量”和“支持的图片分辨率”,可根据场景选择:
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
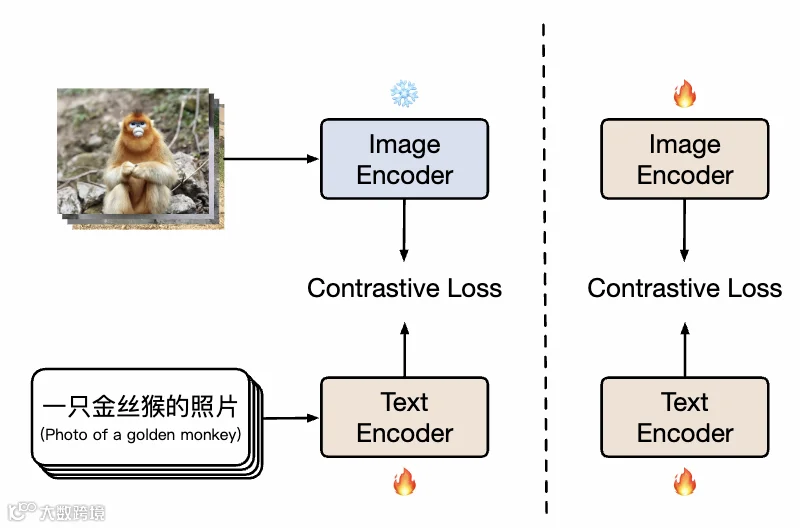
下图为中文CLIP的训练流程,清晰展示了“分阶段优化”的逻辑
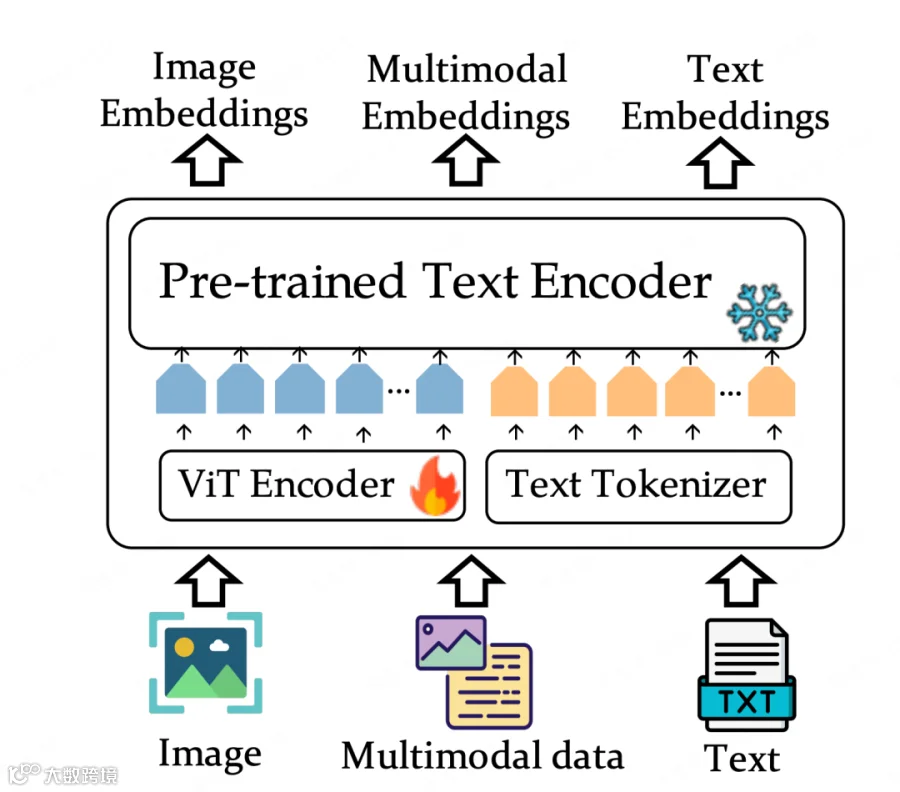
2.3 BAAI VISTA:聚焦“混合模态检索”,小参数量也能打
相比GME的“大参数量高性能”和CLIP的“通用场景覆盖”,BAAI推出的VISTA(Visualized-BGE) 走了另一条路——以“小参数量”为优势,专门优化“混合模态检索”(即“文本+图像”组合查询的场景)。
VISTA的核心定位:混合模态检索的“轻量选手”
VISTA的设计初衷是解决“单一模态查询不够精准”的问题,比如你想检索“如何用Photoshop裁剪圆形图片”,仅用文本可能搜到文字教程,而用“文本+PS界面截图”的组合查询,能更精准匹配到图文教程。
它的核心应用场景有3类,每类都对应具体需求:
- 多模态知识检索
:用“文本”检索“图文对”或“图像”(如用“手机拍照虚化设置”的文本,找包含步骤截图的教程); - 组合图像检索
:用“图文对”检索“图像”(如用“红色笔记本电脑+办公场景”的图文对,找同款电脑的场景图); - 多模态query检索
:用“图文对”检索“文本”(如用“蛋糕烘焙步骤图+‘如何避免开裂’”的图文对,找对应的文字技巧)。
VISTA的模型结构如下,展示了如何处理“文本+图像”的混合输入
三、3类模型横向对比:参数量、性能与适用场景
看完单个模型的细节,我们用一张表做横向对比,帮你快速判断“什么场景该选什么模型”:
|
|
|
|
|
|
|
|---|---|---|---|---|---|
|
|
|
2. 支持动态图像分辨率 3. UMRB基准SOTA性能 |
|
2. 复杂文档的多模态RAG 3. 对性能要求极高的场景 |
2. 参数量大,对算力要求高 |
|
|
|
2. 版本选择多,适配不同算力 3. 零样本能力强,开箱即用 |
|
2. 算力有限但需中文支持的场景 3. 零样本图片分类 |
2. 不支持混合模态检索 |
|
|
|
2. 混合模态检索(图文对查询)能力强 |
|
2. 算力有限的轻量化场景 |
2. 中文支持能力需进一步验证 |
最后总结:3个选型小建议
- 优先看语言场景
:如果是中文业务(如中文电商、中文内容检索),直接选中文CLIP;如果是英文场景且追求高精度,选GME; - 再看检索类型
:需要“文本+图像”组合查询,选VISTA;需要单模态/跨模态检索,选GME或中文CLIP; - 最后看算力预算
:算力有限(如中小团队),选中文CLIP(base版)或VISTA;算力充足(如企业级应用),选GME(7B版)或中文CLIP(huge版)。
多模态检索的核心是“让不同类型的信息‘说话同一种语言’”,而选择合适的表征模型,就是实现这一目标的关键。希望这篇文章能帮你理清思路,找到适合自己场景的技术方案~