
📚分布式训练系列文章
数据并行VS模型并行VS混合并行
本文建议阅读时长:8分钟
在大模型训练中,显存瓶颈是制约模型规模的重要因素。DeepSpeed 推出的Zero Redundancy Optimizer(ZeRO) 系列,通过将模型状态(参数、梯度、优化器状态)分布到不同 GPU 上,实现显著的显存优化。

本文将详细介绍 ZeRO-1、ZeRO-2、ZeRO-3 的原理、区别与应用场景。
希望大家带着下面的问题来学习,我会在文末给出答案。
1. ZeRO 核心原理
ZeRO的全称为 Zero Redundancy Optimizer,意思是去除冗余的优化器,我们都知道在分布式训练中,主要的参数包括三部分:模型参数(Parameters)、优化器状态(Optimizer States)、梯度(Gradients),其中优化器状态会占据大约2倍参数量的显存空间,ZeRO 的目标就是 减少每个 GPU 的显存占用,从而支持更大模型训练。它通过 分布式存储模型状态 来降低冗余:

2. ZeRO-1:优化器状态分片
ZeRO-1仅将 优化器状态(如 Adam 的动量、平方梯度)分片到不同 GPU,参数和梯度仍是完整拷贝。
模型训练过程中正向传播和反向传播中并不会用到优化器状态,只有在梯度更新的时候才会使用梯度和优化器状态计算新参数,因此每个GPU单独使用一段优化器状态,对各自GPU的参数更新完之后,再把各个GPU的模型参数合并成完成的模型。
它的训练过程与DDP类似,forward过程由每个rank的GPU独自完整的完成,然后进行backward过程,在backward过程中,梯度通过AllReduce进行同步。
ZeRO-1使显存占用下降,支持更大 batch-size 或更大模型,并且实现简单,通信开销低,适用于模型参数较大,但优化器状态占显存比例高的场景。
3. ZeRO-2:优化器状态 + 梯度分片
ZeRO第二阶段在 ZeRO-1 基础上,进一步将 梯度 分片。前向计算后,GPU 只保存本地梯度的部分,反向传播完成后通过 AllReduce 聚合梯度。
ZeRO显存节省比 ZeRO-1 更大,支持更大模型和更高 batch-size。AllReduce 用于聚合梯度,需要一定通信开销,但与显存节省相比收益明显。适用于模型参数大、梯度占用显存较多的场景,在多节点训练中尤为有效。
4. ZeRO-3:全模型状态分片
ZeRO-3将 参数、梯度、优化器状态 全部分片到不同 GPU。每个 GPU 只持有自己负责的模型片段,计算时通过通信获取必要片段。
ZeRO-3显存占用最低,理论上可以训练无限大模型(受通信和计算限制),支持千亿、万亿参数级别模型训练。参数和梯度都需要按需通信,通信开销较 ZeRO-1/2 高,需要精心设计分片策略和通信调度以提升效率。
适用于超大模型训练(千亿参数以上),多节点训练、大 batch-size、混合精度训练场景。
5.图解ZeRO
官方给出了一个5分钟的解释视频,我们一帧帧的看一下:
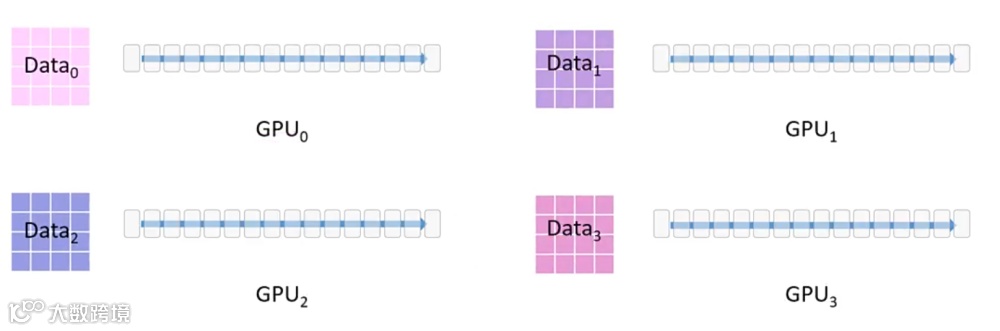
1. 我们拥有一个由 16 个 Transformer 块组成的模型,每个块都是一个完整的 Transformer 模块。

2. 在训练中,我们使用一个大型数据集并借助 4 张 GPU 进行训练。

3. 为此,采用了 三阶段分布式策略,对模型参数(Optimizer + Parameter + Gradient,简称 OPG)和数据同时进行切分与分配,使得它们分布在四张 GPU 上。
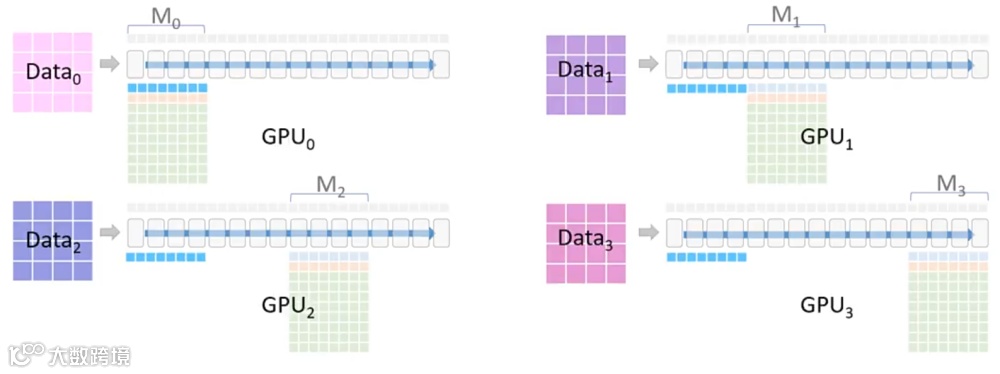
4.每个模块下的方格表示该模块的显存占用情况:
此外,每个模块还需要分配一部分显存用于保存激活值(Activation),图中以蓝色部分表示。

5.在ZeRO3模式下,每张GPU仅负责模型的一部分参数,训练流程如下:
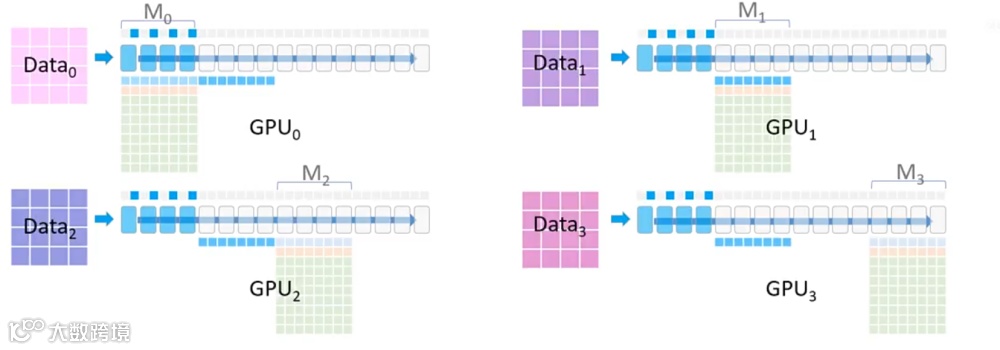
(1)参数广播与前向计算


(2)依次广播其余分块

(3)反向传播阶段
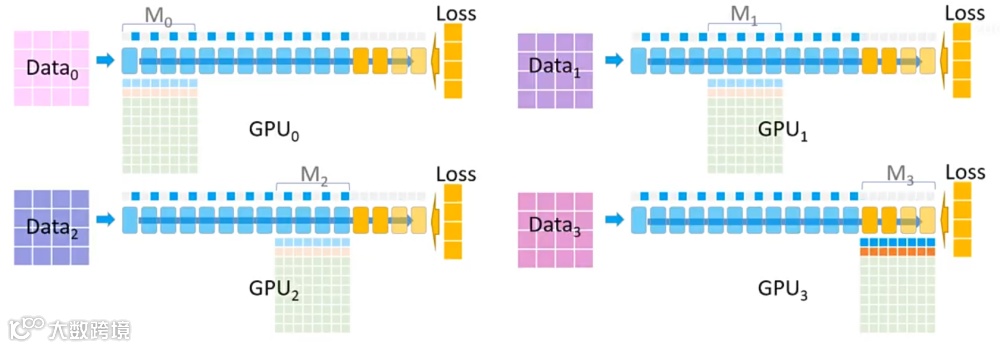
(4)继续回传并更新前面的分块
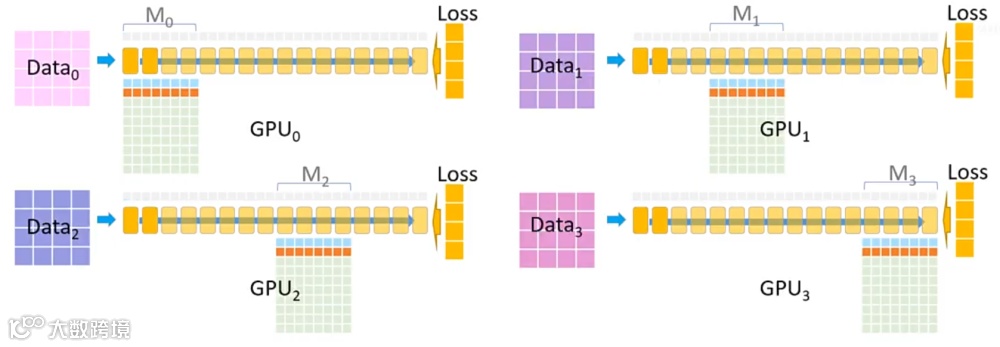
(5)优化器更新与精度回写
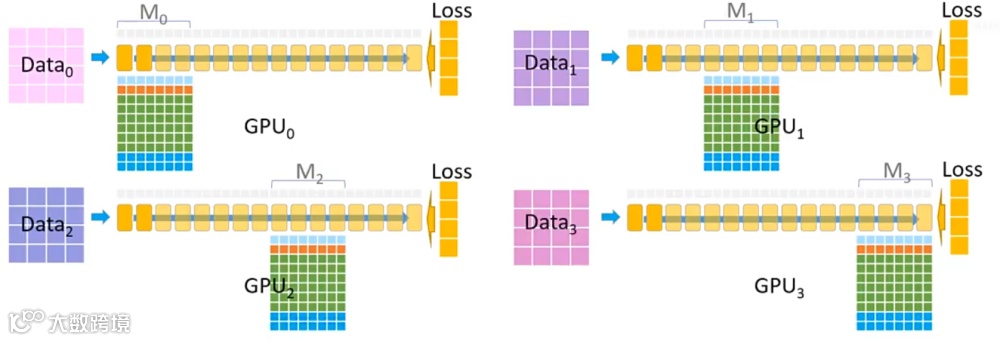
至此,一个完整的 ZeRO3 分布式训练迭代完成。
最后,我们回答文章开头提出的问题
以上内容部分参考 DeepSpeed 官方文档和论文,非常感谢,如有侵权请联系删除!