
2025年10月20日,亚马逊AWS(云计算服务)发生了大规模宕机事故,影响范围遍及全球。此次故障波及多个知名平台及应用,暴露了全球互联网服务对云基础设施的高度依赖,并引发了对云服务容灾能力与高可用性设计的广泛讨论。
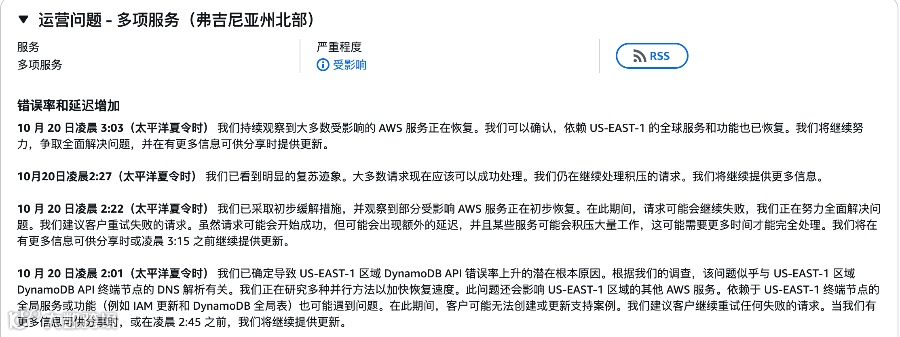
事件发生在美东时间2025年10月20日,AWS的US-East-1区域(弗吉尼亚州)因DNS解析故障导致多个核心服务中断,包括DynamoDB、EC2、CloudFront等关键服务。

图源网络
此故障导致亚马逊平台的卖家中心功能瘫痪,用户无法创建货件、编辑A+页面或访问结算中心等,且移动端APP频繁出现白屏或订单加载失败。此外,多个知名第三方平台,包括Snapchat、Robinhood、Coinbase、Venmo等,也出现了无法访问的情况,部分银行APP、游戏平台(如Fortnite)和智能设备(如Alexa)也受到波及,服务中断影响了数百万用户。
AWS官方发布声明,表示故障源自配置更新引发的DNS解析异常。由于AWS平台在US-East-1区域的DNS系统出现问题,导致多个数据库和服务无法正常访问。AWS已启动修复,并逐步恢复服务,但具体恢复时间尚未明确。
图源网络
企业若希望避免因单一云平台出现故障而导致的重大影响,必须采取一系列应对措施:
1.多区域部署与容灾设计:通过在不同地理位置的云数据中心部署业务系统,确保即便某一地区发生故障,其他区域的服务能够自动接管,最大限度减少服务中断。
2.高可用性架构:采用负载均衡、自动扩展和冗余系统等技术,确保在突发流量或服务故障时,能够自动切换到备用系统,确保业务系统持续运行。
3.定期备份与数据同步:关键数据应定期进行备份,并通过实时同步技术确保备份数据与生产数据的一致性,以便在出现故障时能够迅速恢复。
4.灾难恢复预案:建立并定期演练应急预案,确保在发生系统故障时能够迅速响应,并采取适当的措施恢复业务。
随着云服务的普及,容灾能力和高可用性架构已经成为保障企业数据安全和持续运营的基础。在全球互联网生态中,任何平台的宕机都可能对数百万用户产生巨大影响,企业必须充分认识到这一点,并为可能的故障做好充分准备。
此次AWS事件也提醒我们,未来的技术架构必须更加关注灾难恢复与业务连续性管理。企业应当借此机会重新审视自身的云服务策略,确保在面临突发故障时,能够快速恢复并减少损失。

长按二维码关注我们

云和大数据领域自媒体,关注数据安全、业务连续性、大数据管理、云灾备、存储等行业热点趋势,洞察商业价值,传递大咖观点,欢迎关注。
本公众号发布的内容(包括但不限于字体、图音视频等),版权归原作者或相关权利人所有。如有相关异议,核实后将第一时间进行处理。