
模型部署与应用
导出模型
将训练好的模型导出为可用于推理的格式(如.pt文件导出为onnx,rknn等)。
先讲一下onnx是个啥
1. ONNX 是什么?为什么需要它?
深度学习领域有很多框架(PyTorch、TensorFlow、Keras、MXNet 等),但不同框架训练的模型格式不兼容(比如 PyTorch 的 .pt、TensorFlow 的 .h5)—— 如果用 PyTorch 训练了一个模型,想放到 TensorFlow 部署的环境中,直接用原格式会报错。
ONNX 就是为解决这个 “格式壁垒” 而生的:
·它定义了一套统一的神经网络计算图和参数存储标准,任何框架都可以将模型 “导出” 为 ONNX 格式(.onnx 文件);
·任何支持 ONNX 的框架 / 部署工具(如 TensorRT、ONNX Runtime、OpenVINO 等),又能直接 “导入” ONNX 模型进行推理或优化。
简单说,ONNX 是模型的 “通用翻译官”,让模型能在不同工具间 “自由流转”。
2. ONNX 与 YOLOv8
YOLOv8(yolov8n.pt 是其 PyTorch 权重),也常需要导出为 ONNX 格式,主要用于部署阶段的优化—— 因为 ONNX 格式的模型更易被部署工具(如 TensorRT、ONNX Runtime)加速,适配更多硬件(CPU、GPU、边缘设备如 Jetson)。
将 YOLOv8 的 .pt 模型转为 ONNX 格式的操作(用 Ultralytics 库):
from ultralytics import YOLO# 加载YOLOv8 PyTorch模型model = YOLO("yolov8n.pt")# 导出为ONNX格式(会生成 yolov8n.onnx 文件)model.export(format="onnx") # 可加参数指定输入尺寸、是否简化等
3. ONNX 模型的核心优势
·跨框架兼容:PyTorch/TensorFlow 训练的模型,导出为 ONNX 后,可在 ONNX Runtime、TensorRT 等工具中运行,无需依赖原训练框架;
·部署友好:主流部署工具(TensorRT、OpenVINO、MNN、TNN 等)都优先支持 ONNX,能针对不同硬件做性能优化(如 GPU 加速、量化压缩);
·轻量可解析:ONNX 文件结构清晰,可通过工具(如 netron)可视化模型计算图,方便调试和优化。
模型转换
将yolov8训练出来的.pt文件转换成rknn可供rk芯片板端使用的模型分为两个步骤:
.pt ---> onnx ---> rknn
yolov8n.pt 到 yolov8n.onnx
1. 将.pt文件转换成适配 RKNPU 分割/检测/姿态/旋转框 模型的onnx模型,请参考RKOPT_README.zh-CN.md,该仓库的优化只在导出模型时生效,训练代码按照原仓库的指引即可。
转换代码仓库:https://github.com/airockchip/ultralytics_yolov8
# onnx格式:/home/xhl/yolo/led/rockchip/ultralytics_yolov8# 调整 ./ultralytics/cfg/default.yaml 中 model 文件路径,默认为 yolov8n.pt,若自己训练模型,请调接至对应的路径。支持检测、分割、姿态、旋转框检测模型。# 如填入 yolov8n.pt 导出检测模型# 如填入 yolov8-seg.pt 导出分割模型export PYTHONPATH=./python ./ultralytics/engine/exporter.py# 执行完毕后,会生成 ONNX 模型. 假如原始模型为 yolov8n.pt,则生成 yolov8n.onnx 模型。
yolov8n.onnx 到 yolov8n.rknn
2. 将转换后的onnx模型再转换成对应于芯片的rknn模型。
这部分需要用RKNN-Toolkit2 的环境,这里用RKNN-Toolkit2 的docker环境进行转换。
## rknndocker run -t -i --privileged -v /dev/bus/usb:/dev/bus/usb -v /home/xhl/yolo/led/rockchip:/rockchip rknn_toolkit2-1.6.0 /bin/bashpython3 convert-best.py ../model/best.onnx rk3562
RKNN-Toolkit2又是什么?
rk官方仓库地址:https://github.com/rockchip-linux/rknn-toolkit2/tree/master现在移到了:https://github.com/airockchip/rknn-toolkit2
简介
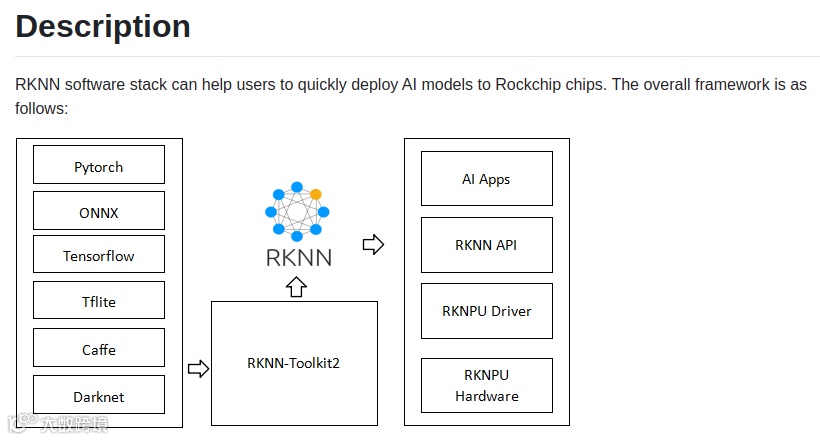
为了使用 RKNPU,用户需要先在电脑上运行 RKNN-Toolkit2 工具,将训练好的模型转换为 RKNN 格式的模型,然后在开发板上使用 RKNN C API 或 Python API 进行推理。
·RKNN-Toolkit2是一套软件开发工具包,供用户在PC和Rockchip NPU平台上进行模型转换、推理和性能评估。
·RKNN-Toolkit-Lite2 为 Rockchip NPU 平台提供 Python 编程接口,帮助用户部署 RKNN 模型,加速 AI 应用落地。
·RKNN Runtime 为 Rockchip NPU 平台提供 C/C++ 编程接口,帮助用户部署 RKNN 模型,加速 AI 应用落地。
·RKNPU 内核驱动负责与 NPU 硬件交互,已开源,可以在 Rockchip 内核代码中找到。
RKNN-Toolkit2 是为用户提供在 PC 平台上进行模型转换、推理和性能评估的开发套件,用户通过该工具提供的 Python 接口可以便捷地完成以下功能:
·模型转换:支持 Caffe、TensorFlow、TensorFlow Lite、ONNX、DarkNet、PyTorch 等模型转为 RKNN 模型,并支持 RKNN 模型导入导出,RKNN 模型能够在 Rockchip NPU 平台上加载使用。
·量化功能:支持将浮点模型量化为定点模型,目前支持的量化方法为非对称量化 (asymmetric_quantized-8),并支持混合量化功能。
·模型推理:能够在 PC 上模拟 NPU 运行 RKNN 模型并获取推理结果;或将 RKNN 模型分发到指定的 NPU 设备上进行推理并获取推理结果。
·性能和内存评估:将 RKNN 模型分发到指定 NPU 设备上运行,以评估模型在实际设备上运行时的性能和内存占用情况。
·量化精度分析:该功能将给出模型量化前后每一层推理结果与浮点模型推理结果的余弦距离,以便于分析量化误差是如何出现的,为提高量化模型的精度提供思路。
·模型加密功能:使用指定的加密等级将 RKNN 模型整体加密。因为 RKNN 模型的加密是在 NPU 驱动中完成的,使用加密模型时,与普通 RKNN 模型一样加载即可,NPU 驱动会自动对其进行解密。
关于量化的几个问题
1. 什么叫 量化 (Quantization)?
在深度学习里,量化就是把模型中原本使用的高精度浮点数(比如 FP32)转换成低精度整数(比如 INT8、UINT8)来进行存储和计算。
FP32:32 位浮点数,常见于训练阶段,精度高但计算和存储开销大。
INT8:8 位整数,常见于部署阶段,精度稍低但速度快、占用小。
举个例子:原本一层卷积的权重是:[0.123456, -0.987654, 0.543210],量化后可能变成:[15, -128, 70]。在推理时,再配合量化参数(scale、zero_point)还原近似的真实值。
2.为什么要量化
主要有三大原因:
·提升推理速度
o像 RK3562、RK3588、RK1126 这类 Rockchip 芯片里,NPU 对 INT8 运算做了硬件加速。如果不量化,模型只能跑在 CPU 或 GPU 上,速度会慢很多。量化后的模型能充分利用 NPU 的并行计算能力。
·减少模型大小
oFP32:每个数占 4 字节
oINT8:每个数占 1 字节
o所以量化后 模型大小直接减少 75%,非常适合嵌入式设备、移动端。
·降低功耗
o整数运算耗能更低,部署在 边缘设备 / 嵌入式平台 时,能显著降低功耗、延长续航。
·量化的代价
o精度下降:因为浮点数被压缩成整数,表示能力有限。
o对数据分布敏感:如果量化时选的校准数据集不合适,精度损失会更严重。
o不同层影响不同:有些层(比如输入层、激活层)更敏感,量化时需要特殊策略。
·量化的常见方式
o动态量化 (Post Training Dynamic Quantization):不需要样本,简单快速,但精度可能下降较多。
o静态量化 (Post Training Static Quantization, PTQ):需要提供一批真实样本作为 校准集,精度更高。RKNN 推荐这种方式。
o量化感知训练 (Quantization Aware Training, QAT):在训练时模拟量化效果,最终模型对量化更鲁棒。精度最好,但训练成本高。
总结:
量化 = 高精度浮点数 → 低精度整数
作用:提速、减小模型、降低功耗
成本:可能会 精度下降在 Rockchip NPU 上,量化是必需的步骤,否则 NPU 无法运行。
如何安装RKNN-Toolkit2
目前提供两种方式安装 RKNN-Toolkit2:
1. 通过 Python 包安装与管理工具 pip 进行安装;
2. 运行带完整 RKNN-Toolkit2 工具包的 docker 镜像。
这里主要讲解使用docker方式。
(pip方式可以查看rk官方文档:docs/cn/Common/NPU/rknn-toolkit2/Rockchip_User_Guide_RKNN_Toolkit2_CN-1.4.0.pdf)
通过docker安装
在RKNN-Toolkit2 源码的docker 文件夹下提供了一个已打包所有开发环境的 Docker 镜像,用户只需要加载该镜像即可直接上手使用 RKNN-Toolkit2
加载镜像
docker load --input rknn-toolkit2-1.x.x-cpxx-docker.tar.gz
运行镜像
docker run -t -i --privileged -v /dev/bus/usb:/dev/bus/usb rknn-toolkit2:1.x.x /bin/bash//将examples代码映射进Docker环境可通过附加“-v:” 参数 -v /dev/bus/usb:/dev/bus/usb
运行转换
参考 :RKNN Model Zoo中examples/yolov8/README.md
#rknndocker run -t -i --privileged -v /dev/bus/usb:/dev/bus/usb -v /home/eco/yolo/led/rockchip:/rockchip rknn_toolkit2-1.6.0 /bin/bash# convert-best.py在RKNN Model Zoo中python3 convert-best.py ../model/best.onnx rk3562
- <onnx_model>
: Specify ONNX model path. - <TARGET_PLATFORM>
: Specify NPU platform name. Such as 'rk3588'. - <dtype>(optional)
: Specify as `i8`, `u8` or `fp`. `i8`/`u8` for doing quantization, `fp` for no quantization. Default is `i8`. - <output_rknn_path>(optional)
`: Specify save path for the RKNN model, default save in the same directory as ONNX model with name `yolov8.rknn`
convert-best.py 做了什么?

import sysfrom rknn.api import RKNNDATASET_PATH = '../../../datasets/animals/animals.txt' #需 要修改为自己的量化图片路径txtDEFAULT_RKNN_PATH = '../model/best.rknn'# 需要修改为自己训练出来的模型DEFAULT_QUANT = Truedef parse_arg():if len(sys.argv) < 3:print("Usage: python3 {} onnx_model_path [platform] [dtype(optional)] [output_rknn_path(optional)]".format(sys.argv[0]));print(" platform choose from [rk3562,rk3566,rk3568,rk3576,rk3588,rk1808,rv1109,rv1126]")print(" dtype choose from [i8, fp] for [rk3562,rk3566,rk3568,rk3576,rk3588]")print(" dtype choose from [u8, fp] for [rk1808,rv1109,rv1126]")exit(1)model_path = sys.argv[1]platform = sys.argv[2]do_quant = DEFAULT_QUANTif len(sys.argv) > 3:model_type = sys.argv[3]if model_type not in ['i8', 'u8', 'fp']:print("ERROR: Invalid model type: {}".format(model_type))exit(1)elif model_type in ['i8', 'u8']:do_quant = Trueelse:do_quant = Falseif len(sys.argv) > 4:output_path = sys.argv[4]else:output_path = DEFAULT_RKNN_PATHreturn model_path, platform, do_quant, output_pathif __name__ == '__main__':model_path, platform, do_quant, output_path = parse_arg()# Create RKNN objectrknn = RKNN(verbose=False)# Pre-process configprint('--> Config model')rknn.config(mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]], target_platform=platform)print('done')# Load modelprint('--> Loading model')ret = rknn.load_onnx(model=model_path)#ret = rknn.load_onnx(inputs=['images'], model=model_path, outputs=['output0'],input_size_list=[[1, 3, 640, 640]])if ret != 0:print('Load model failed!')exit(ret)print('done')# Build modelprint('--> Building model')ret = rknn.build(do_quantization=do_quant, dataset=DATASET_PATH)#ret = rknn.build(do_quantization=False)if ret != 0:print('Build model failed!')exit(ret)print('done')# Export rknn modelprint('--> Export rknn model')ret = rknn.export_rknn(output_path)if ret != 0:print('Export rknn model failed!')exit(ret)print('done')# Releaserknn.release()
集成到应用程序中
将导出的模型集成到目标检测应用程序中,实现实时检测或批量检测等功能。
RKNN Model Zoo
RKNN Model Zoo基于 RKNPU SDK 工具链开发, 提供了目前主流算法的部署例程. 例程包含导出RKNN模型, 使用 Python API, CAPI 推理 RKNN 模型的流程.
·支持 RK3562, RK3566, RK3568, RK3576, RK3588, RV1126B 平台。
·部分支持RV1103, RV1106
·支持 RV1109, RV1126, RK1808 平台。
https://github.com/airockchip/rknn_model_zoo/blob/main/README_CN.md
依赖库安装
RKNN Model Zoo依赖 RKNN-Toolkit2 进行模型转换, 编译安卓demo时需要安卓编译工具链, 编译Linux demo时需要Linux编译工具链。这些依赖的安装请参考 https://github.com/airockchip/rknn-toolkit2/tree/master/doc 的 Quick Start 文档.
Demo修改和编译
/home/xhl/rknn_model_zoo/rknn_model_zoo/examples/yolov8/cpp
examples/yolov8/cpp/postprocess.h
OBJ_CLASS_NUM 改为自己的目标个数

examples/yolov8/cpp/postprocess.cc
LABEL_NALE_TXT_PATH 需要设置自己的标签路径

对于 Linux 系统的开发板:
## 编译# build-linux.shexport GCC_COMPILER=/home/xhl/project/toolchains/gcc-linaro-aarch64-linux-gnu/install/gcc-linaro-aarch64-linux-gnu/bin/aarch64-none-linux-gnu
./build-linux.sh -t <target> -a <arch> -d <build_demo_name> [-b <build_type>] [-m]-t : target (rk356x/rk3576/rk3588/rv1106/rv1126b/rv1126/rk1808)-a : arch (aarch64/armhf)-d : demo name-b : build_type(Debug/Release)-m : enable address sanitizer, build_type need set to DebugNote: 'rk356x' represents rk3562/rk3566/rk3568, 'rv1106' represents rv1103/rv1106, 'rv1126' represents rv1109/rv1126,'rv1126b' is different from 'rv1126'.# 以编译64位Linux RK3566的yolov5 demo为例:./build-linux.sh -t rk356x -a aarch64 -d yolov5
DEMO 的API的详细说明可以参考rk官方文档:docs/cn/Common/NPU/rknpu2/Rockchip_RKNPU_User_Guide_RKNN_API_V1.4.0_CN.pd📎Rockchip_RKNPU_User_Guide_RKNN_API_V1.4.0_CN.pdf
通用API调用流程:
在推理 RKNN 模型时,原始数据要经过输入处理、NPU 运行模型、输出处理三大流程。

对于零拷贝 API 接口,在分配内存后使用内存信息初始化 rknn_tensor_memory 结构体,在推理前创建并设置该结构体,并在推理后读取该结构体中的内存信息。根据用户是否需要自行分配模型的模块内存(输入/输出/权重/中间结果)和内存表示方式(文件描述符/物理地址等)差异。
代码逻辑
int main(int argc, char **argv){if (argc != 3){printf("%s <model_path> <image_path>\n", argv[0]);return -1;}const char *model_path = argv[1];const char *image_path = argv[2];int ret;int result_idx = 0;rknn_app_context_t rknn_app_ctx;memset(&rknn_app_ctx, 0, sizeof(rknn_app_context_t));init_post_process();ret = init_yolov8_model(model_path, &rknn_app_ctx);if (ret != 0){printf("init_yolov8_model fail! ret=%d model_path=%s\n", ret, model_path);goto out;}image_buffer_t src_image;memset(&src_image, 0, sizeof(image_buffer_t));ret = read_image(image_path, &src_image);//RV1106 rga requires that input and output bufs are memory allocated by dmaret = dma_buf_alloc(RV1106_CMA_HEAP_PATH, src_image.size, &rknn_app_ctx.img_dma_buf.dma_buf_fd,(void **) & (rknn_app_ctx.img_dma_buf.dma_buf_virt_addr));memcpy(rknn_app_ctx.img_dma_buf.dma_buf_virt_addr, src_image.virt_addr, src_image.size);dma_sync_cpu_to_device(rknn_app_ctx.img_dma_buf.dma_buf_fd);free(src_image.virt_addr);src_image.virt_addr = (unsigned char *)rknn_app_ctx.img_dma_buf.dma_buf_virt_addr;src_image.fd = rknn_app_ctx.img_dma_buf.dma_buf_fd;rknn_app_ctx.img_dma_buf.size = src_image.size;if (ret != 0){printf("read image fail! ret=%d image_path=%s\n", ret, image_path);goto out;}object_detect_result_list od_results;ret = inference_yolov8_model(&rknn_app_ctx, &src_image, &od_results);if (ret != 0){printf("init_yolov8_model fail! ret=%d\n", ret);goto out;}// 画框和概率char text[256];for (int i = 0; i < od_results.count; i++){object_detect_result *det_result = &(od_results.results[i]);printf("%s @ (%d %d %d %d) %.3f\n", coco_cls_to_name(det_result->cls_id),det_result->box.left, det_result->box.top,det_result->box.right, det_result->box.bottom,det_result->prop);if (od_results.count > MAX_DETECTIONS){printf("too many detections! count=%d\n", od_results.count);result_idx = det_result->prop > od_results.results[result_idx].prop ? i : result_idx;}int x1 = det_result->box.left;int y1 = det_result->box.top;int x2 = det_result->box.right;int y2 = det_result->box.bottom;draw_rectangle(&src_image, x1, y1, x2 - x1, y2 - y1, COLOR_BLUE, 3);sprintf(text, "%s %.1f%%", coco_cls_to_name(det_result->cls_id), det_result->prop * 100);draw_text(&src_image, text, x1, y1 - 20, COLOR_RED, 10);}if (od_results.count <= 0){printf("no detections! count=%d\n", od_results.count);printf("animals_result = -1 null @ 0\n");}else{printf("animals_result = %d %s @ %.3f\n", od_results.results[result_idx].cls_id, coco_cls_to_name(od_results.results[result_idx].cls_id), od_results.results[result_idx].prop);}write_image("out.png", &src_image);out:deinit_post_process();ret = release_yolov8_model(&rknn_app_ctx);if (ret != 0){printf("release_yolov8_model fail! ret=%d\n", ret);}if (src_image.virt_addr != NULL){dma_buf_free(rknn_app_ctx.img_dma_buf.size, &rknn_app_ctx.img_dma_buf.dma_buf_fd,rknn_app_ctx.img_dma_buf.dma_buf_virt_addr);free(src_image.virt_addr);}return 0;}