
实验策略子人群挖掘系统在因果推断与用户建模中的应用
精细化、科学化的业务决策支持工具
导读:本次内容介绍了实验策略子人群挖掘系统在因果推断与用户建模方面的能力,包括统一维度表建设、CATE 模型训练、双重差分估计与倾向性得分匹配方法的实现。系统可支持推荐策略优化、产品运营迭代等场景,助力实现更精细化的业务决策。
主要内容包括以下几个部分:
- 平台介绍
- 策略正向子人群
- 其他因果推断功能
- 总结
- 问答
分享嘉宾|罗慰蓝 腾讯音乐 实验平台负责人
编辑整理|陈思永
内容校对|李瑶
出品社区|DataFun
01 平台介绍
腾讯音乐娱乐集团(TME)是中国领先的在线音频娱乐平台,旗下包括 QQ 音乐、酷狗音乐、酷我音乐及全民 K 歌等多个主流平台。
02 策略正向子人群
围绕 TME 实验平台的一项关键功能——策略正向子人群挖掘,全面介绍其项目背景、数据准备、建模方法及算法实现,旨在展示该功能的技术路径与落地效果。
1. 项目背景

在腾讯音乐的产品迭代过程中,实验平台是常规评估工具。通常流程如下:产品上线新功能后,通过小规模垂直随机实验验证效果,并由数据科学团队回收并分析数据以判断是否达到推广标准。
然而,实验组整体效果可能并不显著,但部分用户对新功能存在偏好。这种异质性提示需要进一步探索子人群响应差异。因此,需要识别并对积极响应用户进行精准建模。
过去,这一过程依赖数据科学团队模型开发与特征工程,周期冗长,影响产品快速迭代。为提升效率,平台构建自动化挖掘工具,实现一键化分析与报告生成,将周期压缩至小时级别。
2. 解题思路

整个系统分为三个核心阶段:数据准备、条件平均处理效应预估、可视化决策支持。
(1)数据准备
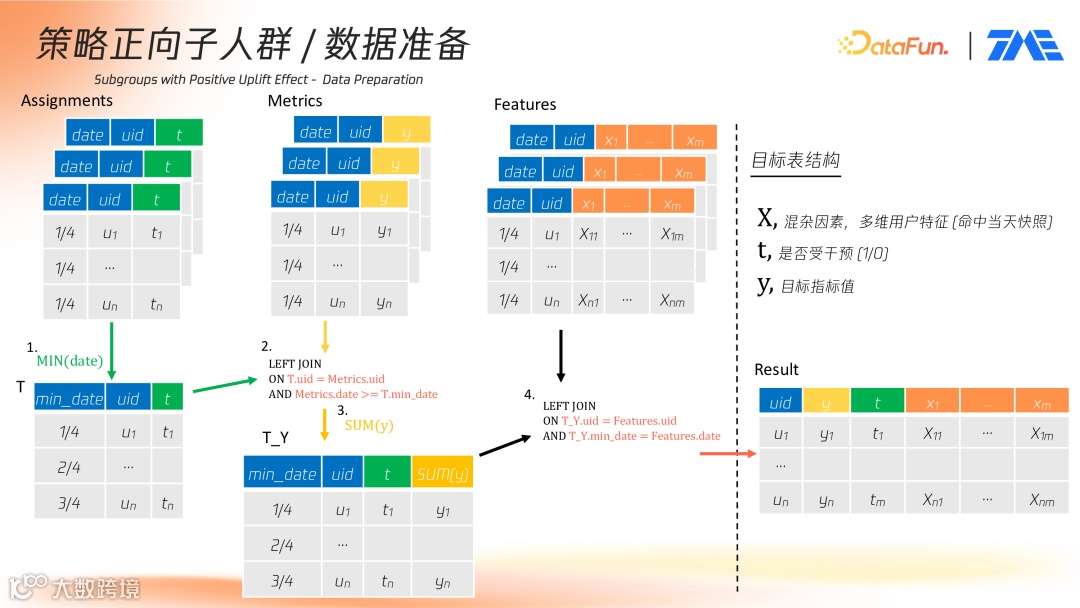
平台底层数据主要由三类表构成:
- Assignments 表:记录用户是否命中实验组及时间点;
- Metrics 表:记录实验期间用户行为指标;
- Features 表:包含实验起始日用户静态和动态特征。
提取每位用户最早命中实验或对照组日期,作为分析起点。随后将其与 Metrics 表关联,获取干预后的行为指标并聚合计算生成用户单条指标记录。
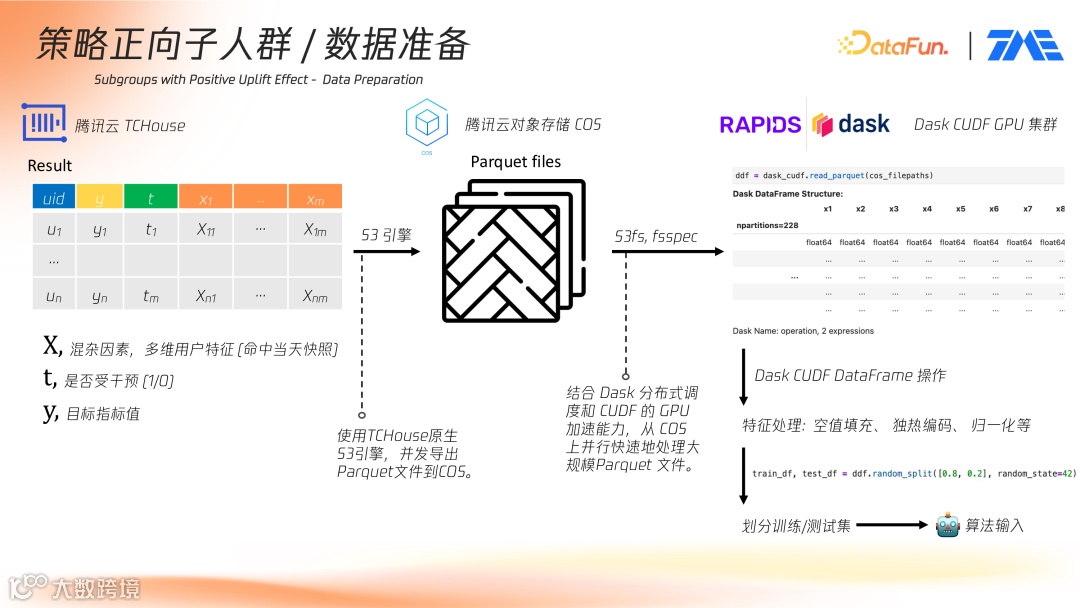
通过关联 Features 表提取用户当日画像特征,最终输出样本包括:
- X:混杂因素,多维用户特征(当日快照);
- t:是否受干预(1/0);
- y:目标指标值。
经处理的数据导出为 Parquet 文件上传至腾讯云 COS,并通过 S3 引擎转换为 Dask CUDF DataFrame 结构,便于 GPU 集群并行处理。
(2)条件平均处理效应预估

建模目标为条件平均处理效应预估(Conditional Average Treatment Effect, CATE),即给定用户画像特征 X,预测接受策略干预与否下的预期指标差值。
由于无法同时观测干预与未干预状态下的指标(潜在结果不可测),采用多种因果推断方法对 CATE 进行估计,主要包括:

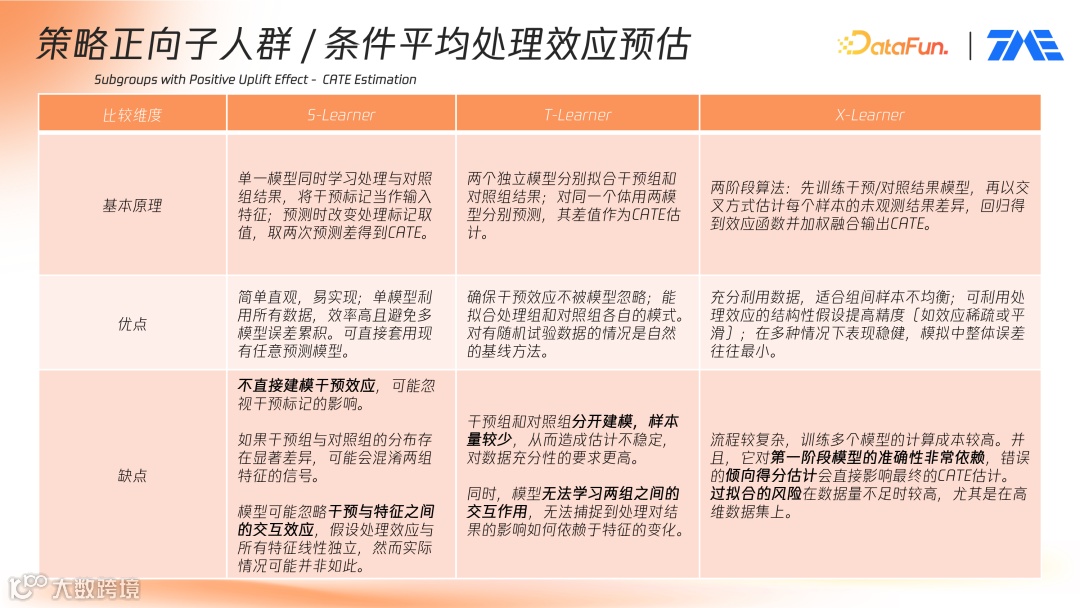
- S-Learner(单模型法):将是否干预 t 作为特征之一,与用户特征 X 一起输入同一个模型,分别以 t=1 与 t=0 对同一用户预测,其差值即为提升值。

- T-Learner(双模型法):分别对实验组与对照组样本训练两个独立模型。预测时,将同一用户特征输入两个模型得出指标差值。
T-Learner 存在对组间样本量平衡的依赖,当实验组与对照组差距过大时,模型表现容易失衡。

- X-Learner:利用实验组与对照组数据训练两个模型,并使用 Uplift 方法结合倾向性得分调整权重,解决样本不平衡问题。
平台支持多种底层算法进行模型训练,包括 XGBoost、LightGBM、Random Forest 等。训练任务均在 GPU 集群中并行执行,显著提升训练效率与泛化性能。
表示学习:

CATE建模与因果推断应用全解析
基于表示学习的CATE模型架构优化
除传统Meta-Learner架构外,近年来在CATE建模中引入了表示学习方法。此类方法通过学习实验组和对照组的共享表示,提升模型泛化能力。
① 双头神经网络建模
该方法为实验组与对照组分别构建输出头。训练时根据样本所属组别更新相应分支及共享层权重,使网络分别拟合两种条件下的响应函数。推理阶段输入用户特征,输出两分支结果之差,即该用户的uplift值。
② DragonNet模型结构
DragonNet在双头网络基础上增加倾向性打分(Propensity Score)头,输出三个量:实验响应值、对照响应值与倾向性得分。其中响应值差值部分即CATE。
训练过程中,仅更新对应组别的输出头及其共享表示层参数,实现更精准的因果效应建模。预测阶段同时输出treatment与control条件下的预测值,两者差值为uplift值。
③ 模型评估 – AUUC指标

评估多个CATE模型效果时,常用AUUC(Area Under the Uplift Curve)作为核心指标。
- 将所有样本按预测uplift值从高到低排序;
- 分桶计算实验组与对照组平均指标差值;
- 绘制uplift曲线并计算曲线下面积;
- 面积越大代表模型干预敏感度越高。
④ 超参数调优 – Optuna框架支持

采用Optuna超参优化框架,自动遍历模型空间和参数组合,使用贝叶斯优化、TPE树结构搜索等策略寻找最优参数组合。
- 定义模型结构与搜索空间;
- 多轮模型训练与验证;
- 每轮评估验证集AUUC表现;
- 迭代优化搜索策略,输出最优超参组合。
训练完成后,在测试集上验证性能以确定最终模型。
结果可视化与业务决策支持

通过uplift预测值结合用户特征构建可解释模型——决策树,便于策略制定。
“二阶段建模”流程:
- 第一阶段训练uplift模型;
- 第二阶段建立解释型模型,增强业务可理解性。

- 提取正向uplift最大人群路径与负向路径;
- 汇总分裂条件,形成可操作策略;
- 自动生成文字报告并通过企业微信推送,辅助产品经理决策。
全流程打通从建模、评估到可视化解释各环节,实现策略正向人群的自动化建模输出。
因果推断平台全流程能力建设

建模流程已嵌入实验平台,通过自动化管道支持模型训练、评估、调参、可视化与报告生成。相较传统人工建模,效率提升数十倍,任务周期从数天缩短至半小时至一小时。
- 支持多种因果模型(Meta-Learners、表示学习法等);
- 内置自动特征表与共享维度仓,避免手动处理特征;
- 涵盖模型训练、调参、评估、可视化与报告输出的全流程。

- 默认设置下,单轮建模至报告输出可在30分钟~1小时内完成。
其他因果推断功能支持
1. 双重差分法

平台提供经典双重差分法,用于消除实验前存在的初始差异对因果效应估计的影响。
通过构建线性回归模型计算净效应 β₃ 及其置信区间,得到准确的因果效应估计。

2. 倾向性得分匹配(PSM)
平台同样提供PSM(倾向性得分匹配)方法,适用于非随机试验场景下的因果推断。
- 倾向得分建模:基于用户特征训练分类模型,输出每个用户接受干预的概率;
- 分桶抽样匹配:将得分划分桶区间,在对照组进行比例抽样,确保整体匹配;
- 匹配质量评估:通过标准化平均差异(SMD)衡量匹配效果,一般SMD < 0.1视为匹配质量合格。
较传统一对一匹配方式,该方法显著提升效率,并通过桶级匹配实现全量人群的一致控制。
平台价值总结
本次内容聚焦介绍了平台核心因果推断能力——策略正向子人群挖掘,详细解析其数据科学流程、工程实现与落地应用,帮助更全面掌握不同因果推断技术的适用场景。
因果推断是从现象到本质理解的关键步骤。未来将持续深化因果建模能力,拓展应用场景边界,推动业务更科学、更具解释性的策略决策。
常见问题解答
1. 模型落地与系统集成
平台构建的人群挖掘能力不仅停留在建模层面,已在推荐算法与策略运营场景中实现有效集成:
(1)推荐系统协同
在推荐系统场景中,建模输出的显著特征贡献度可用于启发算法团队优化特征设计。例如通过识别哪些特征对uplift值影响显著,在不改变模型结构前提下加入这些特征,从而提升模型表达力与可解释性。
精细化运营与因果推断建模的实践应用
(2)精细化运营支持
在人群策略落地过程中,运营或产品团队可通过平台输出的人群规则,在画像平台中精准圈选目标用户,执行下一轮实验或策略迭代。这种方式实现了策略的精细化分发与循环优化,适用于非推荐类业务场景。
(3)闭环实验验证
对通过 uplift 建模识别出的正向响应人群,可在下轮实验中聚焦这些人群执行干预,形成以因果推断为核心的迭代式优化流程。例如,在不更改推荐算法的前提下,仅对预期响应显著的群体进行推荐实验,有助于更精确释放业务价值。
结果建模与因果树模型分离实现
平台采用“两步建模”方式,在获得更大建模灵活性的同时提升业务适应性与可解释性。首先使用 CATE 类方法确定 uplift 显著人群,再基于这些结果与特征构建决策树,从而实现对人群结构的可视化与解释。
